




目录
1、布隆过滤器的作用
一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
2、布隆过滤器原理
向布隆过滤器中添加元素:
先使用多个哈希函数对元素值进行计算,得到多个哈希值。
根据得到的每个哈希值,在位数组中把对应下标的值置为 1。
判断元素是否存在:
对给定元素再次进行添加元素时相同的哈希计算;
得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。

3、使用场景
- 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5亿以上!)、
防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。 - 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
4、三种实现方式
4.1 自定义实现
4.1.1 需要实现以下功能:
- 一个合适大小的位数组保存数据
- 几个不同的哈希函数
- 添加元素到位数组(布隆过滤器)的方法实现
- 判断给定元素是否存在于位数组(布隆过滤器)的方法实现。
4.1.2 代码:
package com.study.bloomFilter.myBloom;
import java.util.BitSet;
/**
*
* @描述: 自己实现bloom过滤器
* @版权: Copyright (c) 2020
* @公司:
* @作者: 严磊
* @版本: 1.0
* @创建日期: 2020年5月30日
* @创建时间: 下午12:19:22
*/
public class MyBloomFilter
{
/** 位数组的大小 */
private static final int DEFAULT_SIZE = 2 << 24;
/** 通过这个数组可以创建 6 个不同的哈希函数 */
private static final int[] SEEDS = new int[] { 3, 13, 46, 71, 91, 134 };
/** 位数组。数组中的元素只能是 0 或者 1 */
private BitSet bits = new BitSet(DEFAULT_SIZE);
/** 存放包含 hash 函数的类的数组 */
private SimpleHash[] func = new SimpleHash[SEEDS.length];
/**
* 描述:初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样
* 使用多个位数组,可以减少hash冲突带来的误判,必须是存在所有位数组中时,才判定这个元素存在
*/
public MyBloomFilter()
{
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++)
{
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
*
* @描述:添加元素到位数组
* @作者:严磊
* @时间:2020年5月30日 下午12:00:56
* @param value
*/
public void add(Object value)
{
for (SimpleHash f : func)
{
bits.set(f.hash(value), true);
}
}
/**
* 判断指定元素是否存在于每一个位数组
*/
public boolean contains(Object value)
{
boolean ret = true;
for (SimpleHash f : func)
{
ret = ret && bits.get(f.hash(value));
if(!ret)
{
return ret;
}
}
return ret;
}
/**
*
* @描述: 静态内部类。用于 hash 操作
* @版权: Copyright (c) 2020
* @公司:
* @作者: 严磊
* @版本: 1.0
* @创建日期: 2020年5月18日
* @创建时间: 上午11:58:23
*/
public static class SimpleHash
{
private int cap;
private int seed;
public SimpleHash(int cap, int seed)
{
this.cap = cap;
this.seed = seed;
}
/**
*
* @描述: 计算 hash 值
* @作者:严磊
* @时间:2020年5月18日 上午11:58:32
* @param value
* @return
*/
public int hash(Object value)
{
int h;
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));
}
}
}
4.1.3 测试:
package com.study.bloomFilter.myBloom.test;
import java.util.LinkedHashSet;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
import com.study.bloomFilter.myBloom.MyBloomFilter;
/**
*
* @描述: 测试
* @版权: Copyright (c) 2020
* @公司:
* @作者: 严磊
* @版本: 1.0
* @创建日期: 2020年5月16日
* @创建时间: 下午5:22:41
*/
public class TestFunc
{
private static Random random = new Random();
// 数据量
private static int size = 1000000;
// 用一个数据结构保存一下所有实际存在的值
private static LinkedHashSet<Integer> existentNumbers = new LinkedHashSet<Integer>();
private static MyBloomFilter bloom = new MyBloomFilter();
public static void main(String[] args)
{
AtomicInteger count_while = new AtomicInteger();
while(true)
{
count_while.incrementAndGet();
if(existentNumbers.size()>=size)
{
break;
}
int randomKey = random.nextInt();
existentNumbers.add(randomKey);
bloom.add(randomKey);
}
System.out.printf("获取%d个数据量,循环了%d次",size,count_while.get());
//verify.1 验证已存在的数是否都存在的
AtomicInteger count = new AtomicInteger();
existentNumbers.forEach(number -> {
if ( bloom.contains(number) )
{
count.incrementAndGet();
}
});
System.out.printf("实际的数据量: %d, 判断存在的数据量: %d \n", existentNumbers.size(), count.get());
//verify.2 找1000000个不存在的数,验证误识别率
for (int i = 0; i < 10; i++)
{
LinkedHashSet<Integer> notExist = new LinkedHashSet<Integer>();
int num =0;
while (num < 1000000)
{
int key = random.nextInt();
if ( existentNumbers.contains(key) )
{
continue;
}
else
{
// 这里一定是不存在的数
notExist.add(key);
num++;
}
}
count.set(0);
notExist.forEach(number -> {
if ( bloom.contains(number) )
{
count.incrementAndGet();
}
});
System.out.printf("%d个不存在的数据, 判断存在的数据量: %d \n", 1000000, count.get());
}
}
}
4.2 GoogleGuava实现
4.2.1 添加Guava 依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
4.2.2 BloomFilter构造方法
<T> BloomFilter<T> BloomFilter.create(Funnel<? super T> funnel, int expectedInsertions, double fpp)
各参数含义:
funnel: 数据类型(一般是调用Funnels工具类中的)
expectedInsertions: 期望插入的值的个数
fpp: 错误率(默认值为0.03)
4.2.3 判定基本数据类型
package com.study.bloomFilter.googleGuava;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Map;
import java.util.Random;
import java.util.Set;
import java.util.concurrent.atomic.AtomicInteger;
import org.junit.Test;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.Funnels;
import com.google.common.hash.PrimitiveSink;
/**
*
* @描述: 使用谷歌guava工具类集成的布隆过滤器
* 参考:https://ifeve.com/google-guava/
* @版权: Copyright (c) 2020
* @公司:
* @作者: 严磊
* @版本: 1.0
* @创建日期: 2020年5月30日
* @创建时间: 下午2:51:49
*/
public class GoogleGuava
{
/**
*
* @描述:测试基本数据类型
* @作者:严磊
* @时间:2020年5月30日 下午2:53:43
* @param args
*/
@Test
public void test1()
{
BloomFilter<String> bloom = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8),//Funnels.integerFunnel(), //数据格式
1000000,//预计存入数据量
0.01);//误判率
// 生成1000000个不同的数
int size = 1000000;
Set<String> existentNumbers = new HashSet<String>();
Random random = new Random();
int count = 0;
while(true)
{
if(existentNumbers.size()>=size)
{
break;
}
count++;
String randomKey = random.nextInt()+"";
existentNumbers.add(randomKey);
bloom.put(randomKey);
}
System.out.printf("获取%d个数据量,循环了%d次 \n",size,count);
//verify.1 验证已存在的数是否都存在的
AtomicInteger countAtomic = new AtomicInteger();
existentNumbers.forEach(number -> {
if ( bloom.mightContain(number) )
{
countAtomic.incrementAndGet();
}
});
System.out.printf("实际的数据量: %d, 判断存在的数据量: %d \n", existentNumbers.size(), countAtomic.get());
//verify.2 找1000000个不存在的数,验证误识别率
for (int i = 0; i < 10; i++)
{
LinkedHashSet<String> notExist = new LinkedHashSet<String>();
int num =0;
while (num < 1000000)
{
String key = random.nextInt()+"";
if ( existentNumbers.contains(key) )
{
continue;
}
else
{
// 这里一定是不存在的数
notExist.add(key);
num++;
}
}
countAtomic.set(0);
notExist.forEach(number -> {
if ( bloom.mightContain(number) )
{
countAtomic.incrementAndGet();
}
});
System.out.printf("%d个不存在的数据, 判断存在的数据量: %d ", 1000000, countAtomic.get());
System.out.println("实际误差:"+(countAtomic.get()/1000000.0));
}
}
}
误差测试结果:符合预期的0.01

4.2.4 判定自定义类
注意:自定义类一定要重写hashcode和equals方法,才能比较两个对象的相同
package com.study.bloomFilter.googleGuava;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Map;
import java.util.Random;
import java.util.Set;
import java.util.concurrent.atomic.AtomicInteger;
import org.junit.Test;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.Funnels;
import com.google.common.hash.PrimitiveSink;
/**
*
* @描述: 使用谷歌guava工具类集成的布隆过滤器
* 参考:https://ifeve.com/google-guava/
* @版权: Copyright (c) 2020
* @公司:
* @作者: 严磊
* @版本: 1.0
* @创建日期: 2020年5月30日
* @创建时间: 下午2:51:49
*/
public class GoogleGuava
{
/**
*
* @描述:测试自定义对象 (只有重写了hashcode方法和equals,才能正确对比对象)
* 只有是同一个对象才会返回true
* @作者:严磊
* @时间:2020年5月30日 下午5:05:57
*/
@SuppressWarnings("serial")
@Test
public void testBloom3() {
BloomFilter<Person> bloomFilter = BloomFilter.create(new Funnel<Person>() {
@Override
public void funnel(Person person, PrimitiveSink primitiveSink) {
primitiveSink.putString(person.toString(), Charsets.UTF_8);
}
}, 1000, 0.001);
Person person = new Person(1, "小红");
bloomFilter.put(person);
// 判断是否存在,false则表示一定不存在; true表示可能存在
boolean ans = bloomFilter.mightContain(person);
System.out.println(ans);
Person person2 = new Person(1, "小红");
ans = bloomFilter.mightContain(person2);
System.out.println("只有重写了hashcode方法和equals才会返回【true】:"+ans);
bloomFilter.put(person2);
ans = bloomFilter.mightContain(person2);
System.out.println(ans);
}
static class Person
{
public int id;
public String name;
public Person(int id, String name)
{
super();
this.id = id;
this.name = name;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (id != other.id)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
}
4.3 Redis实现
相较于Guava的优点:
Guava的布隆过滤器使用简单,但是Guava重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景
4.3.1 使用redis的module功能
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom.
4.3.2 利用redis的bitmap数据结构实现
package com.study.bloomFilter.redisBloom.bitmap;
import java.nio.charset.Charset;
import org.apache.log4j.Logger;
import com.google.common.hash.Funnels;
import com.google.common.hash.Hashing;
import com.google.common.primitives.Longs;
import com.study.bloomFilter.error.BloomFilterException;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
/**
*
* @描述: 使用redis bitmap实现布隆过滤器
* @版权: Copyright (c) 2020
* @公司:
* @作者: 严磊
* @版本: 1.0
* @创建日期: 2020年5月31日
* @创建时间: 上午11:06:07
*/
public class RedisBloomFilter
{
private static final Logger LOGGER = Logger.getLogger(RedisBloomFilter.class);
private static final String BF_KEY_PREFIX = "bf:";
private int numHashFunctions; //hash函数个数
private long bitmapLength; //bit位数
private Jedis jedis; //redis连接池
/**
* 描述: 构造方法,构造布隆过滤器
* @param numApproxElements 预估元素数量
* @param fpp 可接受的最大误差(假阳性率)
* @param jedisResourcePool Codis专用的Jedis连接池
*/
public RedisBloomFilter(long numApproxElements, double fpp, Jedis jedis)
{
this.jedis = jedis;
if ( fpp >= 1 || fpp <= 0 )
{
new RuntimeException("可接受的最大误差必须满足0<fpp<1");
}
//限制bitmapLength大为4294967296, redis bitMap映射被限制在 512MB之内,最多存储2^32( 4294967296)数据
bitmapLength = Math.min((long) ( -numApproxElements * Math.log(fpp) / (Math.log(2) * Math.log(2))), 2L << 31);
numHashFunctions = Math.max(1, (int) Math.round((double) bitmapLength / numApproxElements * Math.log(2)));
}
/**
*
* @描述:取得自动计算的最优哈希函数个数
* @作者:严磊
* @时间:2020年5月31日 上午11:26:36
* @return
*/
public int getNumHashFunctions()
{
return numHashFunctions;
}
/**
*
* @描述:取得自动计算的最优Bitmap长度
* @作者:严磊
* @时间:2020年5月31日 上午11:26:30
* @return
*/
public long getBitmapLength()
{
return bitmapLength;
}
/**
*
* @描述:计算一个元素值哈希后映射到Bitmap的哪些bit上
* 使用的是 com.google.common.hash.BloomFilterStrategies MURMUR128_MITZ_64()
* @作者:严磊
* @时间:2020年5月31日 上午11:26:05
* @param element 元素值
* @return bit下标的数组
*/
private long[] getBitIndices(String element)
{
long[] indices = new long[numHashFunctions];
byte[] bytes = Hashing.murmur3_128().hashObject(element, Funnels.stringFunnel(Charset.forName("UTF-8")))
.asBytes();
long hash1 = Longs.fromBytes(bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
long hash2 = Longs.fromBytes(bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9],
bytes[8]);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++)
{
indices[i] = (combinedHash & Long.MAX_VALUE) % bitmapLength;
combinedHash += hash2;
}
return indices;
}
/**
*
* @描述:插入元素
* @作者:严磊
* @时间:2020年5月31日 上午11:25:27
* @param key 原始Redis键,会自动加上'bf:'前缀
* @param element 元素值,字符串类型
* @param expireSec 过期时间(秒)
*/
public void addElement(String key, String element, int expireSec)
{
if ( key == null || element == null )
{
throw new RuntimeException("键值均不能为空");
}
String actualKey = BF_KEY_PREFIX.concat(key);
/**
* 使用redis 管道Pipeline,将命令打包推送 参考:https://www.cnblogs.com/yepei/p/5662734.html
*/
try (Pipeline pipeline = jedis.pipelined())
{
for (long index : getBitIndices(element))
{
pipeline.setbit(actualKey, index, true);
}
pipeline.syncAndReturnAll();
jedis.expire(actualKey, expireSec);
}
catch (Exception ex)
{
LOGGER.error("资源关闭时发生Exception", ex);
throw new BloomFilterException(ex);
}
}
/**
*
* @描述:检查元素在集合中是否(可能)存在
* @作者:严磊
* @时间:2020年5月31日 下午1:30:24
* @param key 原始Redis键,会自动加上'bf:'前缀
* @param element 元素值,字符串类型
* @return
*/
public boolean mayExist(String key, String element)
{
if ( key == null || element == null )
{
throw new RuntimeException("键值均不能为空");
}
String actualKey = BF_KEY_PREFIX.concat(key);
boolean result = false;
/**
* 使用redis 管道Pipeline,将命令打包推送 参考:https://www.cnblogs.com/yepei/p/5662734.html
*/
try (Pipeline pipeline = jedis.pipelined())
{
for (long index : getBitIndices(element))
{
pipeline.getbit(actualKey, index);
}
result = !pipeline.syncAndReturnAll().contains(false);
}
catch (Exception ex)
{
LOGGER.error("资源关闭时发生Exception", ex);
throw new BloomFilterException(ex);
}
return result;
}
}
测试:
package com.study.bloomFilter.redisBloom.bitmap.test;
import java.util.LinkedHashSet;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
import com.study.bloomFilter.redisBloom.bitmap.RedisBloomFilter;
import com.study.utils.RedisSimplePool;
import redis.clients.jedis.Jedis;
public class TestFunc
{
private static Random random = new Random();
// 数据量
private static int size = 1000000;
private static String key = "redis-bloom:key1";
private static int expireSec = 60*10;
// 用一个数据结构保存一下所有实际存在的值
private static LinkedHashSet<String> existentNumbers = new LinkedHashSet<String>();
private static RedisBloomFilter bloom = null;
public static void main(String[] args)
{
//获取redis连接
Jedis jedis = RedisSimplePool.getJedis();
System.out.println("连接成功");
//查看服务是否运行
System.out.println("服务正在运行: " + jedis.ping());
bloom = new RedisBloomFilter(1000000L, 0.001, jedis);
AtomicInteger count_while = new AtomicInteger();
while (true)
{
count_while.incrementAndGet();
if ( existentNumbers.size() >= size )
{
break;
}
String randomKey = random.nextInt() + "";
existentNumbers.add(randomKey);
bloom.addElement(key, randomKey, expireSec);
}
System.out.printf("获取%d个数据量,循环了%d次", size, count_while.get());
//verify.1 验证已存在的数是否都存在的
AtomicInteger count = new AtomicInteger();
existentNumbers.forEach(number -> {
if ( bloom.mayExist(key, number) )
{
count.incrementAndGet();
}
});
System.out.printf("实际的数据量: %d, 判断存在的数据量: %d \n", existentNumbers.size(), count.get());
//verify.2 找1000000个不存在的数,验证误识别率
for (int i = 0; i < 10; i++)
{
LinkedHashSet<String> notExist = new LinkedHashSet<String>();
int num = 0;
while (num < size)
{
String number = random.nextInt() + "";
if ( existentNumbers.contains(number) )
{
continue;
}
else
{
// 这里一定是不存在的数
notExist.add(number);
num++;
}
}
count.set(0);
notExist.forEach(number -> {
if ( bloom.mayExist(key, number) )
{
count.incrementAndGet();
}
});
System.out.printf("%d个不存在的数据, 判断存在的数据量: %d \n", size, count.get());
}
RedisSimplePool.returnJedis(jedis);
}
}
结果截图: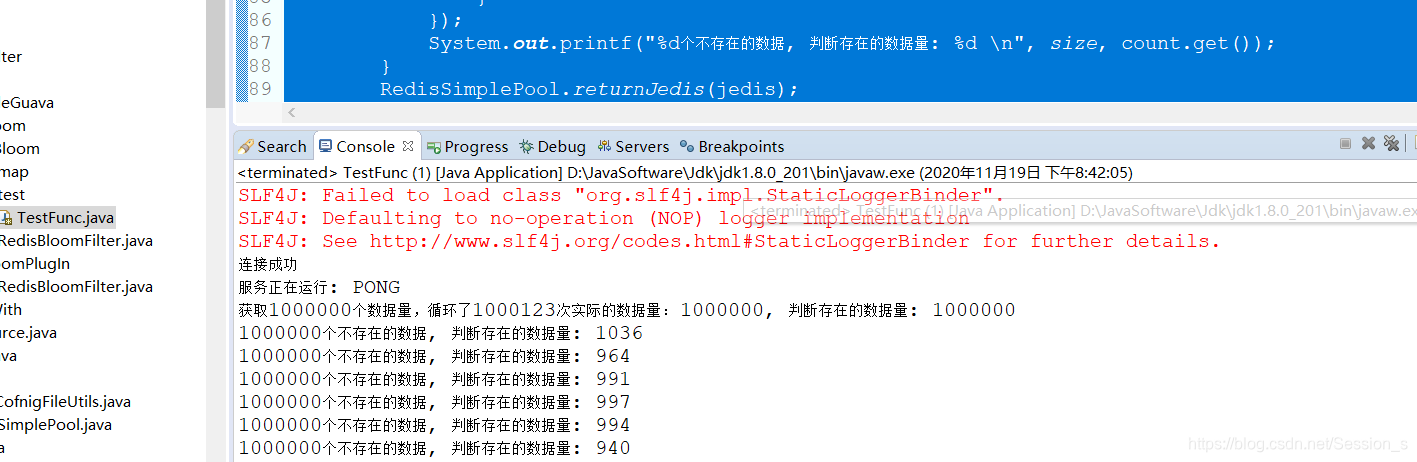

















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









