




引言
在上一篇文章《Apache Doris 4.0 AI 能力揭秘(一):AI 函数之 LLM 函数介绍》中,我们介绍了 Apache Doris 4.0 如何通过原生集成 LLM 函数,将大语言模型的强大能力引入 SQL 分析场景,实现文本处理的智能化与内部分析的无缝化。这一能力不仅拓展了数据库的边界,也为数据密集型业务注入了全新的智能维度。
然而,技术能力的落地并不止于功能实现,真正的价值在于其在企业复杂场景中的稳定、高效与可管理的实践。随着 AI 函数在更多业务线中使用,如何将其从“可用”推进到“好用”、“可控”、“可规模化”,成为企业级应用的关键挑战。 在本篇文章中,我们将深入探讨在真实生产环境中应用 AI 函数的核心考量:Apache Doris LLM Function 的技术架构、核心功能特性、典型应用场景及性能优化策略,为相关技术实践提供参考。
LLM Function 核心价值
在传统的企业级数据分析架构中,文本数据的 AI 处理通常采用分离式模式:数据从数据库导出,应用层调用外部 AI API 进行处理,然后将结果写回数据库。这种架构模式在实际生产环境中面临数据一致性难以保障、性能瓶颈、运维复杂等挑战。Apache Doris LLM Function 通过将大语言模型能力原生集成到 SQL 执行引擎中,从根本上解决了传统架构的痛点,最显著的优势在于实现了事务一致性保障:AI 分析和数据操作在同一个 SQL 事务中完成,对于金融风控、订单处理等对数据一致性要求极高的场景而言,带来了至关重要的提升。
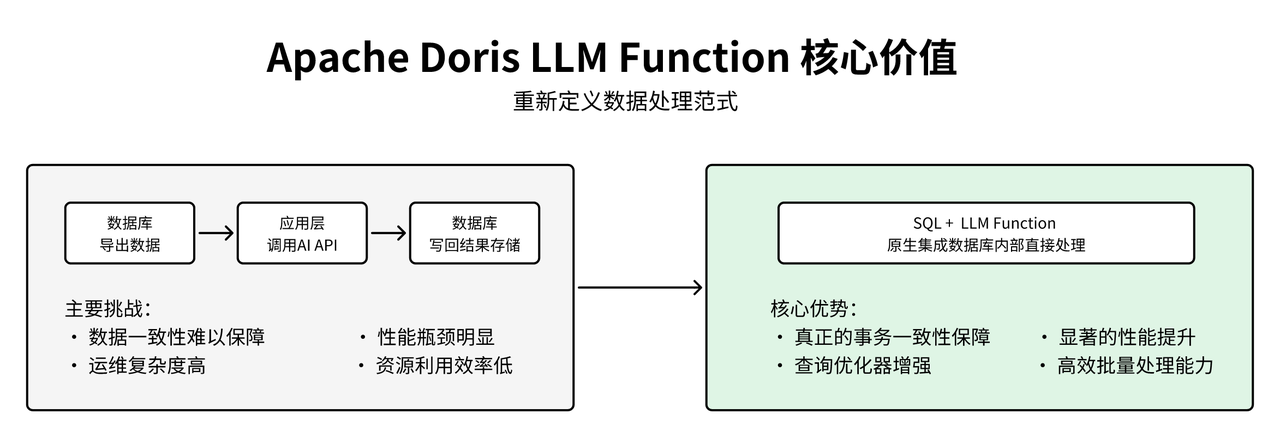
LLM Function 在性能上展现出显著优势:通过将 AI 处理内置于数据库中,省去数据导出导入环节,大幅降低网络与传输开销,使处理时间从分钟级缩短至毫秒级,显著提升实时决策效率。此外,Apache Doris 查询优化器可对包含 LLM 函数的 SQL 进行整体优化,支持并行执行、顺序调度与缓存复用,结合 SQL 的批量处理能力,有效避免了逐条调用外部 API 的性能瓶颈,实现高效、可扩展的智能分析。
数据库原生 AI 能力
01 技术架构设计思路深度解析
Apache Doris LLM Function 的设计理念体现了现代数据库架构演进的重要趋势:将 AI 能力深度集成到数据处理引擎的核心。这种设计思路与传统的“数据导出 - 外部处理 - 结果回流”模式形成鲜明对比,代表了一种更加高效、一体化的技术路径。
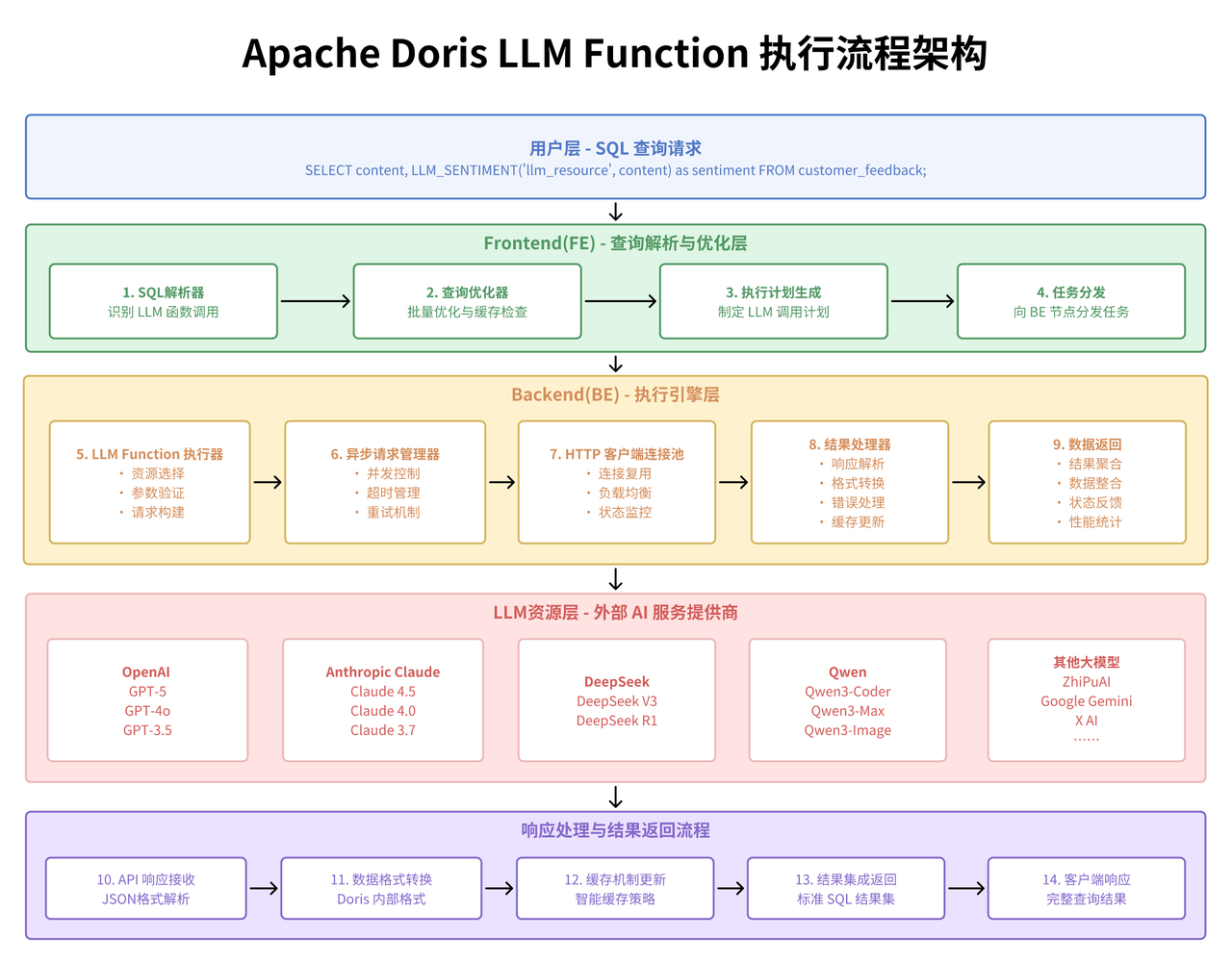
从架构层面来看,LLM Function 采用了资源池化管理的设计模式。通过 CREATE RESOURCE 语句建立的 LLM 资源池,实现了对不同 AI 服务提供商(OpenAI、Anthropic、Gemini 等)的统一管理和动态调用。这种设计的技术优势在于:首先是接口标准化,不同的 LLM 提供商通过统一的资源接口进行管理,避免了业务代码与具体 AI 服务的强耦合;其次是负载均衡****能力,可以根据不同的业务场景和性能要求,灵活选择最适合的 LLM 资源;最后是故障隔离机制,单个 LLM 服务的异常不会影响到整个数据分析流程的稳定性。
在具体的技术实现上,LLM Function 的核心价值体现在其 SQL 原生集成能力。传统的文本分析流程通常需要将数据从数据库中导出,通过外部程序调用 AI 接口,然后将结果写回数据库。这个过程不仅涉及复杂的数据流转,还存在数据一致性、事务管理、性能瓶颈等多个技术挑战。而 LLM Function 通过将 AI 调用能力直接嵌入到 SQL 执行引擎中,实现了数据处理和 AI 分析的无缝融合。
从数据库引擎的角度来看,LLM Function 的实现涉及了多个关键技术层面。在查询优化器层面,需要对包含 LLM 函数的查询进行特殊的优化处理,包括合理的执行顺序安排、批量调用优化、缓存策略等。在执行引擎层面,需要处理异步 API 调用、超时管理、错误重试等复杂逻辑。在资源管理层面,需要实现对外部 API 调用的配额控制、并发限制、成本监控等功能。
02 AI 函数功能详解
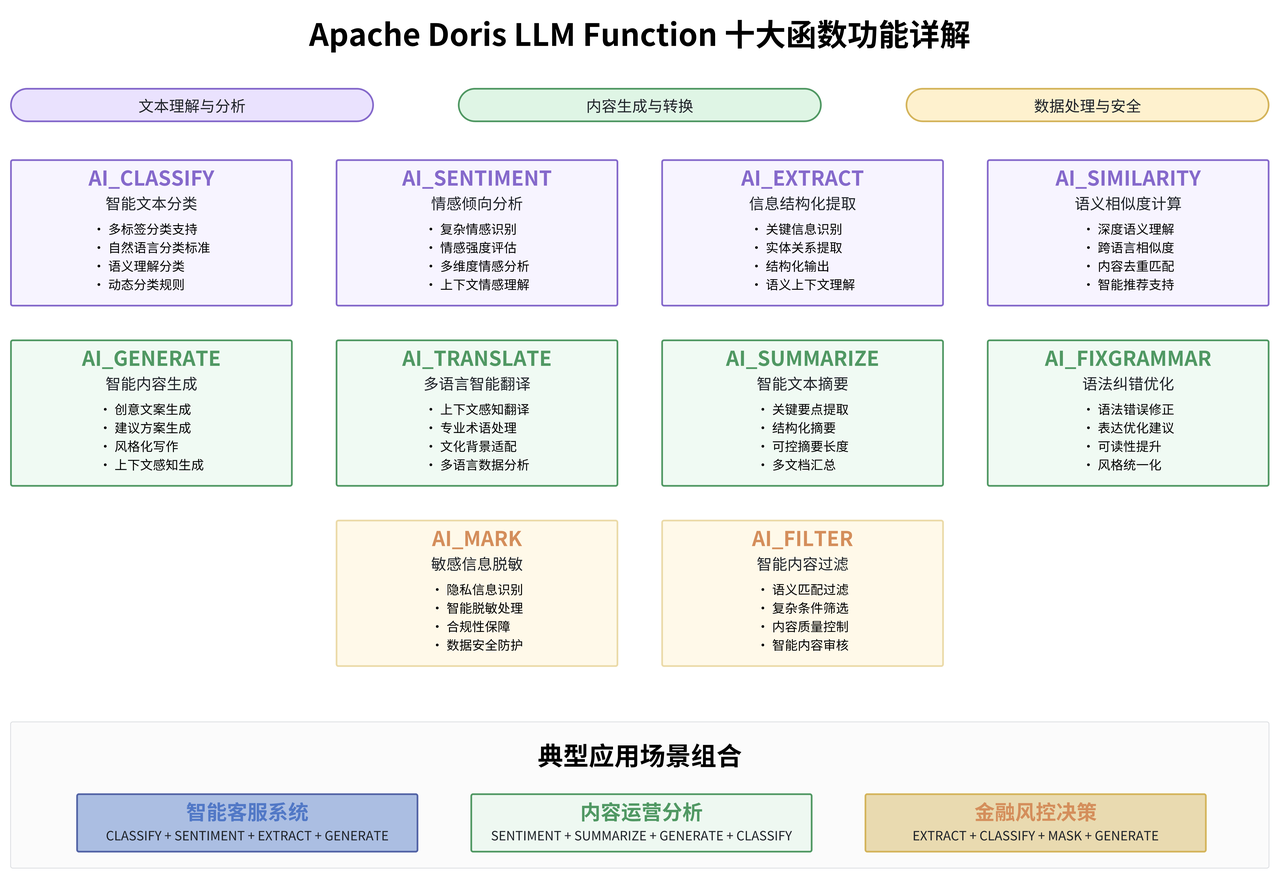
Apache Doris 提供的 10 个 LLM 函数覆盖了文本处理的主要应用场景,每个函数都有其特定的技术特点和最佳适用场景。
-
AI_CLASSIFY 函数 是文本分类场景的核心工具:
在技术实现上,该函数接受文本内容和分类标签作为参数,通过大语言模型的理解能力进行智能分类。与传统的机器学习分类方法相比,AI_CLASSIFY 的最大优势在于无需预训练和特征工程,可以通过自然语言描述的分类标准直接进行分类。在电商平台的用户评价分析中,传统的方法可能需要预先定义大量的关键词规则或训练专门的分类模型,而 AI_CLASSIFY 可以通过语义理解,对复杂的用户反馈进行精准分类。
-- AI_CLASSIFY多维度分类示例 SELECT feedback_id, content, AI_CLASSIFY('primary_llm', content, '产品质量,物流服务,客户服务') as category, AI_CLASSIFY('primary_llm', content, '紧急,重要,普通') as priority FROM user_feedback WHERE create_time >= CURRENT_DATE - INTERVAL 1 DAY; -
AI_SENTIMENT 函数提供了比传统情感分析更加细腻的情感识别能力:
传统的情感分析主要基于词汇情感词典或简单的机器学习模型,往往只能识别基本的正面、负面、中性情感,而且容易被表面的情感词汇误导。AI_SENTIMENT 通过深度的语义理解,能够识别复杂的情感表达,包括讽刺、反语、多重情感等复杂情况。比如"虽然价格有点贵,但是确实物有所值"这样的表述,传统的情感分析可能会因为"贵"这个词而判断为负面,但 AI_SENTIMENT 能够理解整体的正面倾向。
-- AI_SENTIMENT情感分析示例 SELECT review_id, review_text, AI_SENTIMENT('primary_llm', review_text) as sentiment, AI_EXTRACT('primary_llm', review_text, '提取关键问题点') as key_issues FROM product_reviews WHERE review_date >= CURRENT_DATE - INTERVAL 7 DAY; -
AI_EXTRACT 函数在信息提取场景中展现出了强大的结构化能力:
该函数能够从非结构化的文本中提取特定的信息实体,其技术优势在于能够理解语义上下文,准确识别和提取关键信息。传统的正则表达式提取在面对复杂的非结构化文本时往往力不从心,特别是当目标信息以不同的表达方式出现时。而 AI_EXTRACT 通过大语言模型的语义理解能力,可以识别同一概念的不同表达方式,大大提升了信息提取的准确性和覆盖面。
-
AI_GENERATE 函数是创意性文本生成的强大工具:
该函数可以基于给定的上下文和要求,生成符合特定风格和内容要求的文本。在实际应用中,这个功能可以用于自动生成产品描述、客服回复模板、营销文案等多种场景。与传统的模板化生成不同,AI_GENERATE 能够根据具体的上下文信息,生成更加个性化和相关性更强的内容。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











