




作者:字节跳动数据平台
在直播、电商等业务场景中存在着大量实时数据,这些数据对业务发展至关重要。而在处理实时数据时,我们也遇到了诸多挑战,比如实时数据开发门槛高、运维成本高以及资源浪费等。
此外,实时数据处理比离线数据更复杂,需要应对多流 JOIN、维度表变化等技术难题,并确保系统的稳定性和数据的准确性。本文将分享基于 Apache Doris 的实时数仓架构在不同业务场景的实践经验,以及该架构带来的收益。
存储实时数仓架构背景
首先介绍存储实时数仓架构的背景。
01 实时数据数仓链路
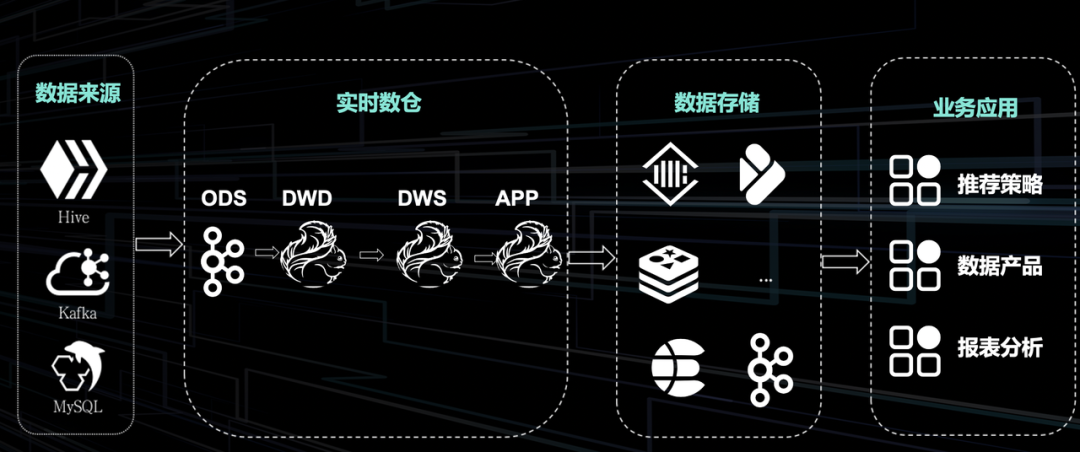
目前实时数据主要使用 Flink 作为中转工具,Kafka 作为 Flink 的逻辑表,实现数据在不同数据分层之间的流转。Kafka 本身没有逻辑表,无法像 Hive 那样清晰地进行开发过程。
实时数据和离线数据的内容生产量级会有比较大落差,主要原因在于实时数据开发成本、运维成本以及资源成本,尤其是前两者相较离线开发更高,因此尽管有一部分实时数据的需求,我们经常会想办法将其降级。
02 Flink 数仓问题与挑战
-
开发门槛高:Flink 是有状态的一套数据流引擎,具有状态的增量特性,需要更清晰的底层认知,特别是在多流 JOIN 等场景下。增量的状态,导致无法像 Hive 那样把全量的数据状态存到内存里,进一步进行简单的数据操作。
实时数据涉及的数据存储量较大,需要使用多种计算引擎,如 OLTP 引擎(MySQL、PostgreSQL)、OLAP 引擎(ClickHouse、Doris)、KV 存储(Abase、Tier、Redis)等,以适应不同的计算需求,这也增加了开发难度。另外,由于其增量状态,也让测试变得困难。
-
开发运维成本高:复杂的多流 JOIN 操作经常需要存储大量状态数据,这可能会导致稳定性问题,尤其是在处理连续直播等情况下。
在多个业务线的平台中,一些发展中的业务线由于需要不断进行业务创新,业务口径随之变化,而 Flink 作为增量状态存储的系统,遇到状态不可恢复的问题是不可避免的。当数据口径变更时,直接上线可能会由于状态结构改变而无法进行数据恢复。
-
资源浪费:在实时场景中,资源浪费是很常见的情况,虽然资源浪费不是核心问题,但是目前各个公司都有治理的需求。
对于一个任务来说,比如在大促活动刚开始的时候,会有大的潮汐洪峰,但过了几分钟之后,流量会迅速地递减退变,为了保证稳定性,我们需要保持高资源位,来稳定地进行 24x7 的运行,这就会导致资源浪费。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7178
7178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











