




 杭银消金采用ApacheDoris1.2对风控数据集市进行升级改造,利用MultiCatalog统一ES、Hive等数据源,实现联邦查询,大幅提高查询效率,从分钟级响应提升至秒级。通过Spark-Doris-Connector,实现Hive与Doris双向流动,优化建模分析。未来计划进一步将实时数据和离线跑批任务迁移到Doris,以提升数据完整性与集群效率。
杭银消金采用ApacheDoris1.2对风控数据集市进行升级改造,利用MultiCatalog统一ES、Hive等数据源,实现联邦查询,大幅提高查询效率,从分钟级响应提升至秒级。通过Spark-Doris-Connector,实现Hive与Doris双向流动,优化建模分析。未来计划进一步将实时数据和离线跑批任务迁移到Doris,以提升数据完整性与集群效率。
导读: 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风控数据集市进行了升级改造,利用 Multi Catalog 功能统一了 ES、Hive、GP 等数据源出口,实现了联邦查询,为未来统一数据查询网关奠定了基础;同时,基于 Apache Doris 高性能、简单易用、部署成本低等诸多优势,也使得各大业务场景的查询分析响应实现了从分钟级到秒级的跨越。
作者|杭银消金大数据团队 周其进,唐海定, 姚锦权
杭银消费金融股份有限公司,成立于 2015 年 12 月,是杭州银行牵头组建的浙江省首家持牌消费金融公司,经过这几年的发展,在 2022 年底资产规模突破 400 亿,服务客户数超千万。公司秉承“数字普惠金融”初心,坚持服务传统金融覆盖不充分的、具有消费信贷需求的客户群体,以“数据、场景、风控、技术”为核心,依托大数据、人工智能、云计算等互联网科技,为全国消费者提供专业、高效、便捷、可信赖的金融服务。
业务需求
杭银消金业务模式是线上业务结合线下业务的双引擎驱动模式。为更好的服务用户,运用数据驱动实现精细化管理,基于当前业务模式衍生出了四大类的业务数据需求:
- 预警类:实现业务流量监控,主要是对信贷流程的用户数量与金额进行实时监控,出现问题自动告警。
- 分析类:支持查询统计与临时取数,对信贷各环节进行分析,对审批、授信、支用等环节的用户数量与额度情况查询分析。
- 看板类:打造业务实时驾驶舱与 T+1 业务看板,提供内部管理层与运营部门使用,更好辅助管理进行决策。
- 建模类:支持多维模型变量的建模,通过算法模型回溯用户的金融表现,提升审批、授信、支用等环节的模型能力。
数据架构 1.0
为满足以上需求,我们采用 Greenplum + CDH 融合的架构体系创建了大数据平台 1.0 ,如下图所示,大数据平台的数据源均来自于业务系统,我们可以从数据源的 3 个流向出发,了解大数据平台的组成及分工:
- 业务系统的核心系统数据通过 CloudCanal 实时同步进入 Greenplum 数仓进行数据实时分析,为 BI 报表,数据大屏等应用提供服务,部分数据进入风控集市 Hive 中,提供查询分析和建模服务。
- 业务系统的实时数据推送到 Kafka 消息队列,经 Flink 实时消费写入 ES,通过风控变量提供数据服务,而 ES 中的部分数据也可以流入 Hive 中,进行相关分析处理。
- 业务系统的风控数据会落在 MongoDB,经过离线同步进入风控集市 Hive,Hive 数仓支撑了查询平台和建模平台,提供风控分析和建模服务。
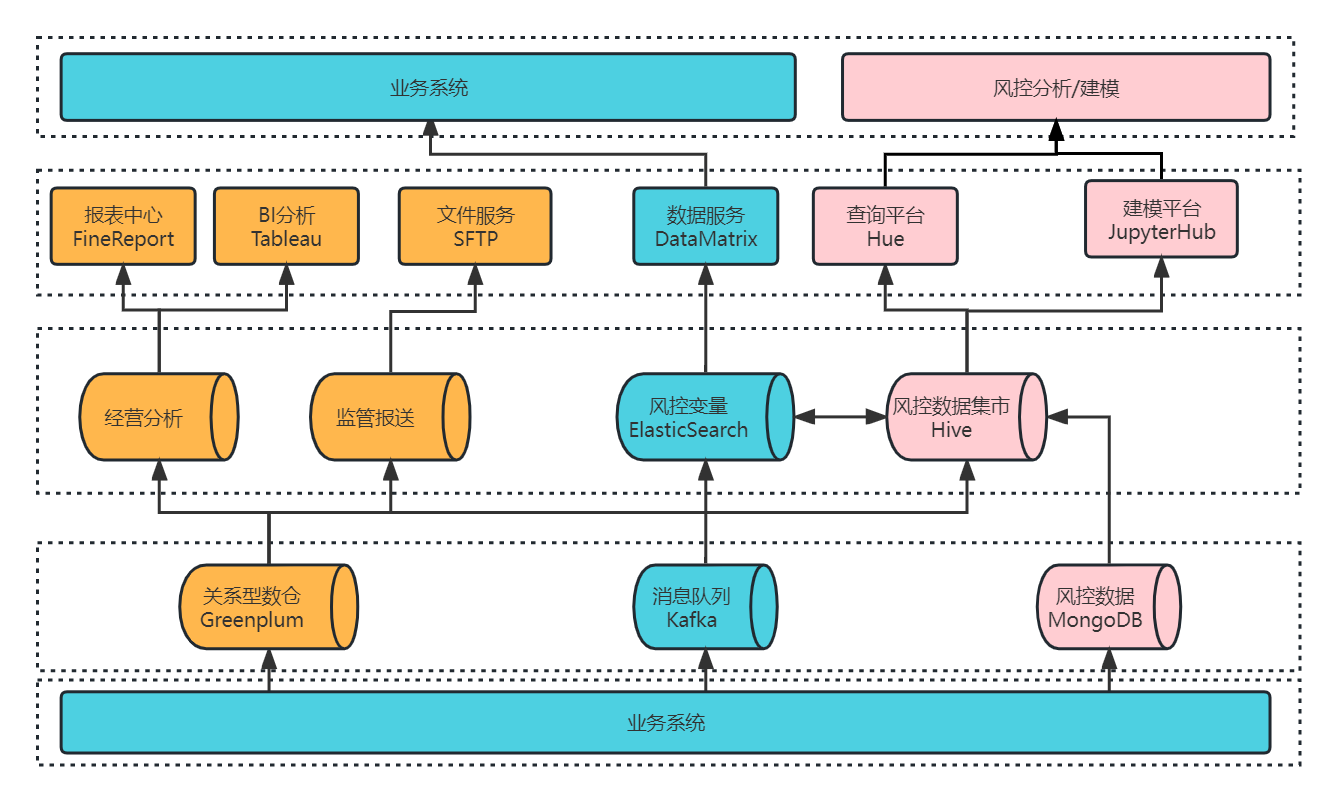
我们将 ES 和 Hive 共同组成了风控数据集市,从上述介绍也可知,四大类的业务需求基本都是由风控数据集市来满足的,因此我们后续的改造升级主要基于风控数据集市来进行。在这之前,我们先了解一下风控数据集市 1.0 是如何来运转的。
风控数据集市 1.0
风控数据集市原有架构是基于 CDH 搭建的,由实时写入和离线统计分析两部分组成,整个架构包含了 ES、Hive、Greenplum 等核心组件,风控数据集市的数据源主要有三种:通过 Greenplum 数仓同步的业务系统数据、通过 MongoDB 同步的风控决策数据,以及通过 ES 写入的实时风控变量数据。
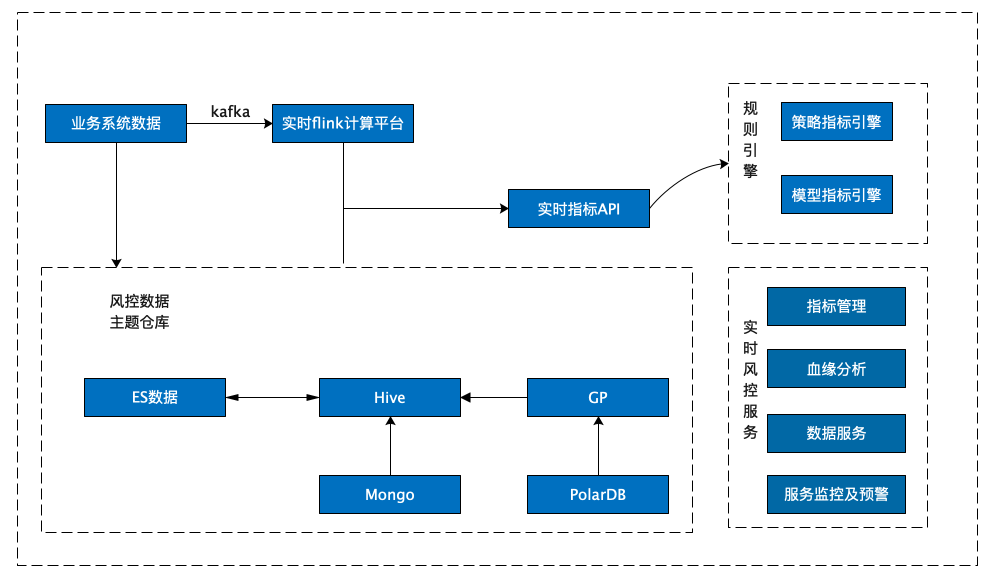
实时流数据: 采用了 Kafka + Flink + ES 的实时流处理方式,利用 Flink 对 Kafka 的实时数据进行清洗,实时写入ES,并对部分结果进行汇总计算,通过接口提供给风控决策使用。
离线风控数据: 采用基于 CDH 的方案实现,通过 Sqoop 离线同步核心数仓 GP 上的数据,结合实时数据与落在 MongoDB 上的三方数据,经数据清洗后统一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2880
2880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











