



 本文介绍了DBSCAN聚类算法的基本原理,包括核心概念如核心点、边界点及密度可达等,并探讨了算法的优点和局限性。此外,还提供了一个实际案例,展示了如何使用DBSCAN算法进行数据分析。
本文介绍了DBSCAN聚类算法的基本原理,包括核心概念如核心点、边界点及密度可达等,并探讨了算法的优点和局限性。此外,还提供了一个实际案例,展示了如何使用DBSCAN算法进行数据分析。
DBSCAN属于无监督学习算法,无监督算法的内涵是观察无标签数据集自动发现隐藏结构和层次,在无标签数据中寻找隐藏规律。
聚类模型在数据分析当中的应用:既可以作为一个单独过程,用于寻找数据内在规律,也可以作为分类等其他分析任务的前置探索。

什么是DBSCAN
DBSCAN是一种基于密度的考虑到噪音的空间聚类算法。简单来讲,给定一组点,DBSCAN将彼此距离(欧几里得距离)很近的点聚成一类,同时它还将低密度区域中的点标记为异常值(outlier)。要了解DBSCAN算法,我们先来熟悉一些关键概念:
数据点密度:某数据点指定的半径中点的数量即称为密度;
核心对象/核心点:如果指定半径(ε)内的数据点数量超过了规定的点数量(Minpts),那么该点即称为核心点;
边界点:如果某点的半径(ε)内的点数量少于规定的点数量(Minpts),不能发展下线,但是却在核心点的邻域内,那么该点称为边界点;
密度可达:若某点a在点b的邻域内,则b是核心点a的直接密度可达,若点c又在点b的邻域内,则点c是点a的间接密度可达,a和c密度相连 (传播过程);
异常值/离群值:未在核心点邻域内,从任何一个核心点出发都密度不可达,既不是核心点也不是边界点的点称为异常值点;
以下图为例,将所有点基于半径(ε)画圈,指定数据点密度为3,我们发现下图红色点在指定半径内的密度均>3,故红色点为核心点;
而B、C点在核心点邻域内,但是其半径内的点只有2个,小于指定密度,故B、C为边界点;
N点未在核心点邻域内,且从任何一个核心点出发都密度不可达,故N为异常值点;以上点A与B、A与C均密度相连;
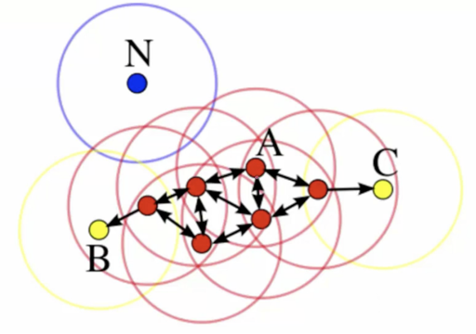

DBSCAN算法实现原理
算法根据指定的邻域密度参数 ( ε , Minpts ) 找出所有点中的核心点,确定核心点集合为Ω;
从Ω中,随机选取一个核心点作为对象,找出所有由其密度可达的样本生成聚类簇;
重复过程2,在Ω中随机选取未被聚簇过的剩余核心点,持续进行直到所有核心点密度可达的聚类完全被发现;


算法优缺点
优点
不需要预先指定聚类簇个数
聚类的形状和大小非常灵活
能够识别和处理异常值(离群点)
参数较少,只有2个
缺点
不适用高维数据
确定合理的参数较困难,且参数对结果影响较大
Sklearn中运行效率较慢
难以寻找不同密度下的聚类
算法针对数据点形状和大小有灵活性,且可以识别处理异常值,聚类效果表现优异,如下图:
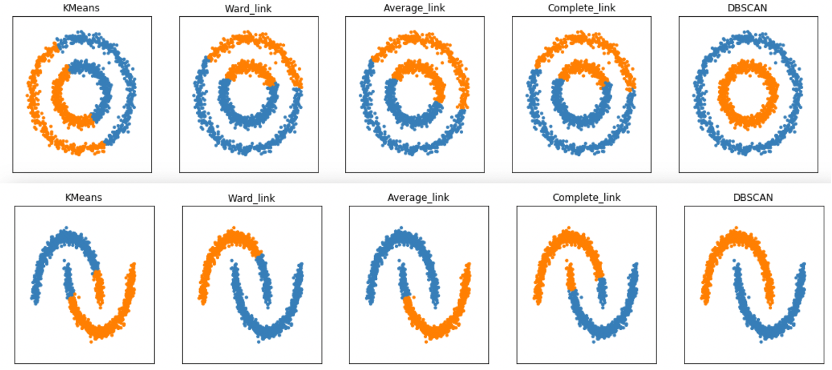
 DBSCAN数据分析实战案例
DBSCAN数据分析实战案例
案例背景:O2O平台为了更好地为线下店面服务,增加一个增值服务,即利用自己拥有的地理位置数据为线下店面选址,数据如下:
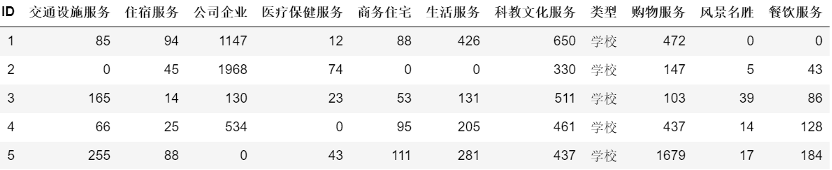
每一条数据是一个兴趣点(POI - Point of Interest)的特征,具体指的是以这个位置为中心的500米半径圆里,各类商家/设施的数量,数据中我们隐藏掉了每个POI的具体名称、坐标、类型。选址的商家将试图从这些位置中选择一个作为下一个店面的位置。
商家想知道这40个潜在店面位置之间是否有显著的差异。我们可以将所有POI按照相似程度,划分成几个类别?
步骤:

数据准备:数据获取、数据清洗、数据变换等步骤,重点是针对分析目的,进行特征选择以及特征标准化;
数据建模:使用DBSCAN算法进行数据建模;
后续分析:聚类模型的特征描述分析,基于业务问题,进一步分析;
1、读取数据
2、特征选取

3、标准化
4、建立DBSCAN模型并可视化
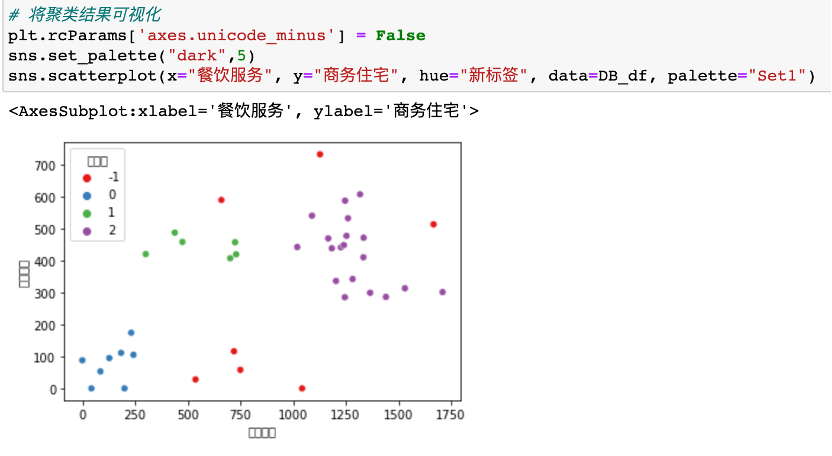
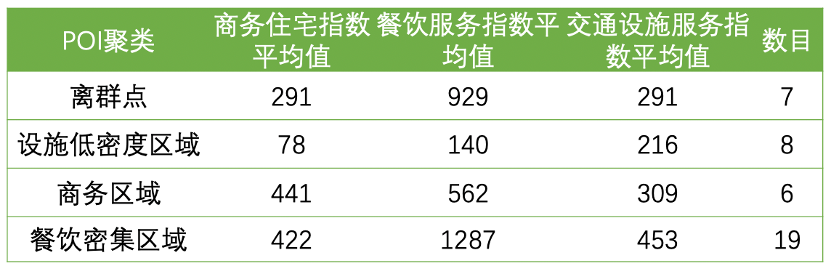
5、聚类分析,对每一聚类进行进一步分析和描述
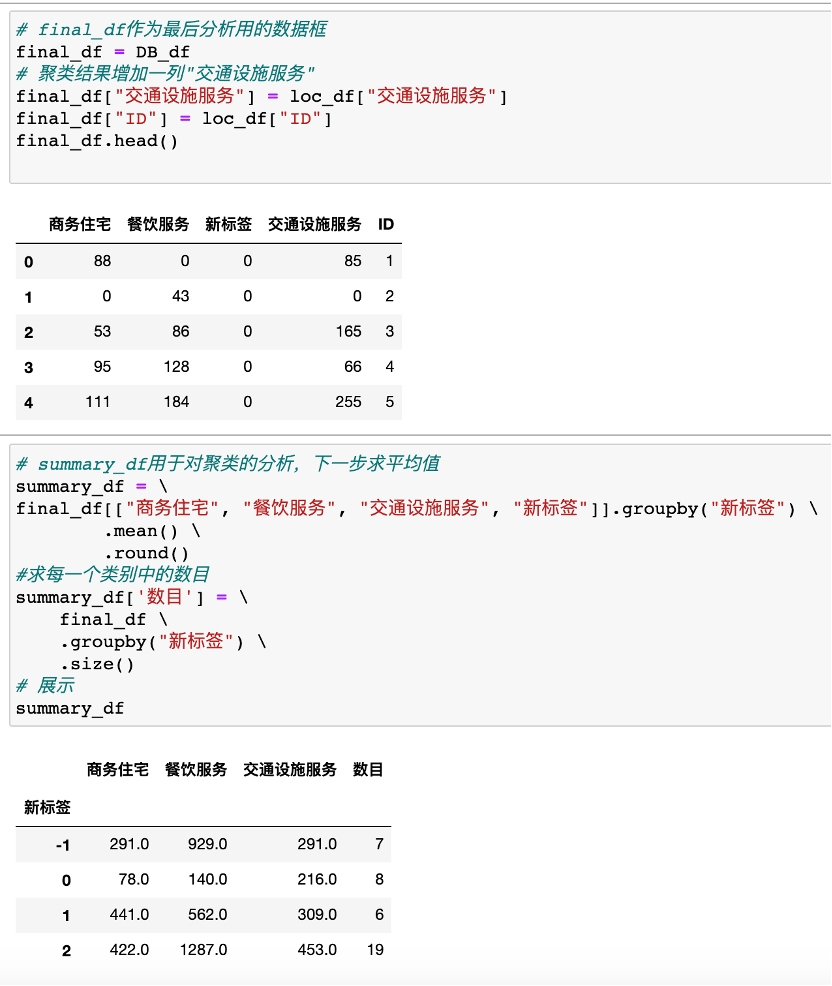
6、根据描述分析,生成poi聚类结果画像,利用聚类,对人群/商品/行为标签进行精细划分,作为进一步商业决策的基础;
以上DBSCAN聚类算法就讲完了,关于算法的参数选择通常是基于经验和对数据集的业务了解来确定,可以使用画k距离图的方式来找拐点然后通过观测聚类表现来调优。

●终于有人把指标设计方法讲明白了
●SQL优化的魅力
















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









