



 山西一所小学因发布详尽的家庭背景分类引发讨论,揭示了刻板印象对学生的影响及教育潜在的不公。作者质疑这种数据处理方式可能导致资源分配不公和歧视,并呼吁回归教育本质。
山西一所小学因发布详尽的家庭背景分类引发讨论,揭示了刻板印象对学生的影响及教育潜在的不公。作者质疑这种数据处理方式可能导致资源分配不公和歧视,并呼吁回归教育本质。
我是小z
最近,山西一小学因为统计数据火了。
因为统计的不是男女比例,不是各科平均成绩,更不是重点中学升学率这种俗套的指标。
他们统计的,是学生的家庭情况,更准确点说是家长背景。
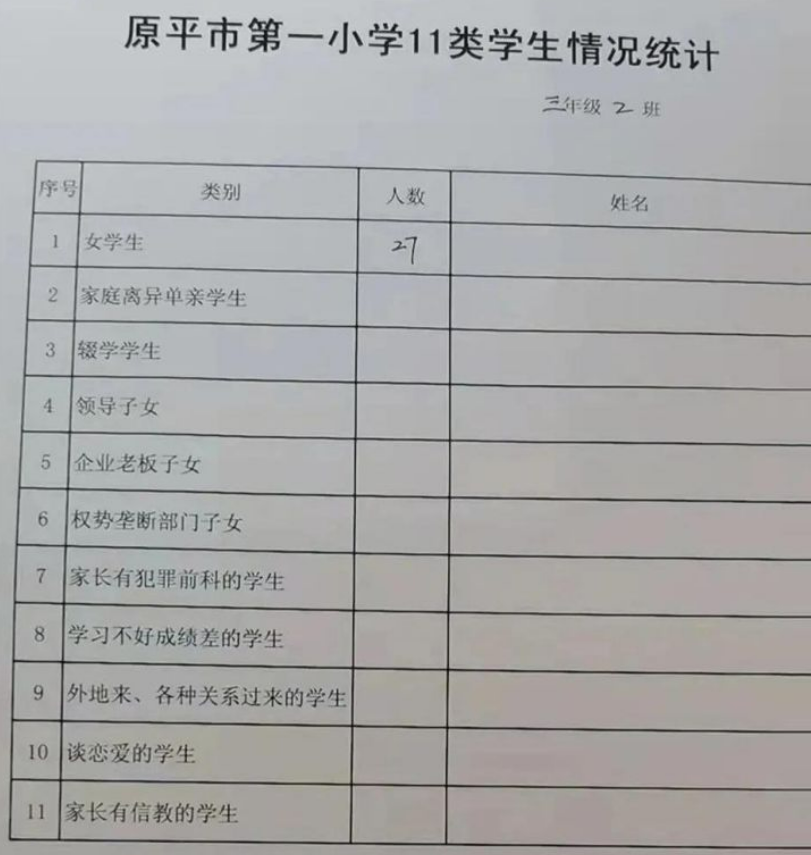
统一印制的表格里,所有学生被分成了11类:
女学生(按性别分类)
家庭离异单亲学生(按父母关系)
辍学学生(按上学情况)
领导子女(按父母背景)
企业老板子女(按父母背景)
权势垄断部门子女(按父母背景)
家长有犯罪前科的学生(按父母是否犯罪)
学习不好成绩差的学生(按成绩)
外地来、各种关系过来的学生
谈恋爱的学生(情感状态)
家长有信教的学生(宗教信仰)
如果班里有个小红同学,她父母刚刚离异;家庭的伤痛让她决定辍学;她的父亲是当地某部门二把手;母亲是当地私企老板,之前因为偷漏税被抓过,还信基督教;辍学前她已经转过几所小学,来到这个小学又谈起了恋爱,导致成绩一直不好。
小红以一己之力,让表格里每一个分类都多了一个人。
所以说,这个分类是极其不合理的,如果是数值类大数统计,一定是要遵循MECE(不重不漏)的原则,如果是多选,那更合理的方式是平铺统计。
知乎网友唐旭已经帮他们做好了平铺统计的表格:
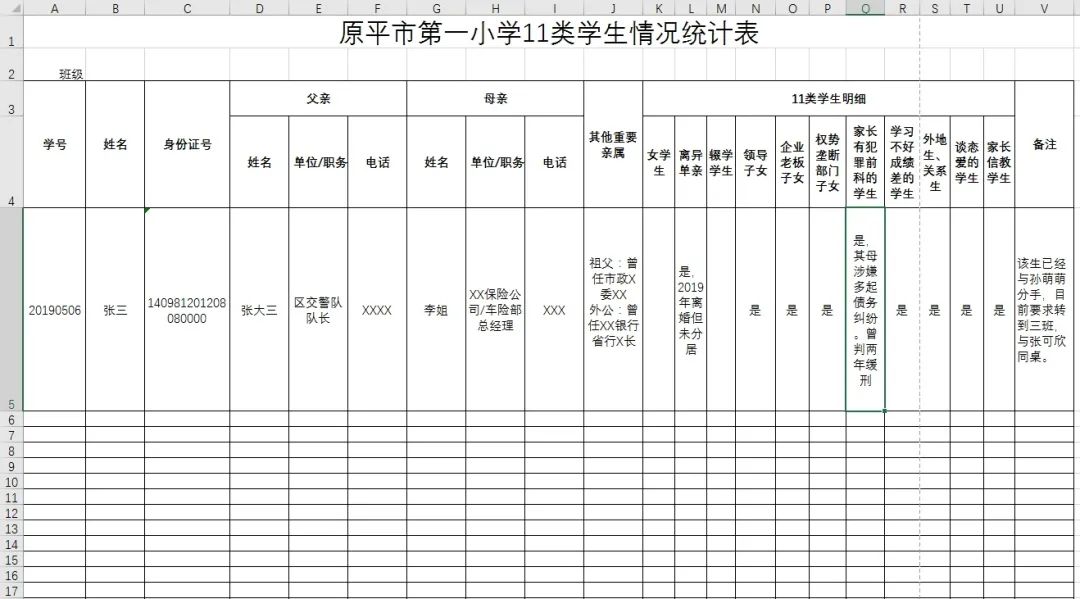
既减少了老师重复统计和反复校对数据的工作量,又增强了实用性,谁是丁谁是卯一清二楚。
反讽告一段落。
这件事其实挺可怕的。
当然,可怕的不是统计数据,因为统计数据永远只是冷冰冰的统计数据,它不会说话。
可怕的是这份统计背后,冷冰冰的刻板标签。
如果真的流水化统计和印发至各个老师,意味着什么?
可能意味着,一个成绩中下,但父母是领导/老板的子女,大概率会比普通家庭但成绩优秀的孩子,得到更多的优待。且地方越小,这个概率越大。
可能意味着,老师在处理学生矛盾时,会带着主观立场去拉偏架。
可能意味着,父母有污点的孩子,得不到足够的关注和保护,更容易成为被霸凌的对象。
可能意味着,家长已经成为老师的一种资源,校内老师关照孩子、校外家长用资源照顾老师的路径更加通畅。
打听学生家长背景的情况,在各地多少都会有。但以这种纸面形式做统计的,是彻底扒了自己的底裤,连脸都不要了。
只能希望,在校园这片净土,少一些市侩,多一些纯真。
以上。
最后,送两本《分布式一致性算法开发实战》,内容偏技术,从介绍分布式一致性算法开始,分析了Raft算法以及Raft算法所依赖的理论,在此基础上讲解并实现了Raft算法以及基于Raft算法的KV服务。

这次完全凭手气,11月9日开奖,扫码即可参与:


●10个面试必会的统计学问题!
●品牌知名度分析

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









