



 本文介绍在Excel中如何使用不同函数实现多区间判断,包括IF函数嵌套、LOOKUP函数、VLOOKUP配合对照表及MATCH函数结合MID的使用方法。
本文介绍在Excel中如何使用不同函数实现多区间判断,包括IF函数嵌套、LOOKUP函数、VLOOKUP配合对照表及MATCH函数结合MID的使用方法。
多区间判断的问题想必大家都遇到过,比如成绩评定、业绩考核等等。今天就和大家分享一个多区间判断的函数公式套路。
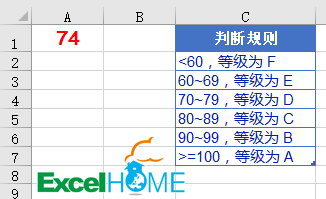
先来看问题,要根据A1单元格中的业绩给出对应的等级,划分规则是:
<60,等级为“F”。
60~69,等级为“E”。
70~79,等级为“D”。
80~89,等级为“C”。
90~99,等级为“B”。
>=100,等级为“A”。
下面咱们就简单汇总一下常用的解决方法和思路。
1、IF函数
=IF(A1>=100,"A",IF(A1>=90,"B",IF(A1>=80,"C",IF(A1>=70,"D",IF(A1>=60,"E","F")))))
通过IF函数嵌套,像剥洋葱一样逐层判断A1数值所在的区间,并返回对应的结果。
大于等于100,返回“A”,大于等于90,返回“B”,大于等于80,返回“C”……
这个公式的优点是易于理解,缺点是如果有多个判断条件,公式会变得越来越长了。
还有一个问题,使用IF函数进行多个区间的判断时,小伙伴们可以记住一个窍门,就是可以从最高的规则部分开始,逐级向下判断。也可以从最低的规则部分开始,逐级向上判断。刚刚这个公式,就可以写成:
=IF(A1<60,"F",IF(A1<70,"E",IF(A1<80,"D",IF(A1<90,"C",IF(A1<100,"B","A")))))
2、LOOKUP
=LOOKUP(A1,{0,60,70,80,90,100},{"F","E","D","C","B","A"})
这种写法是多区间判断并返回对应值的模式化公式,是IF函数逐层判断的升级版。
注意,LOOKUP第二参数要升序处理{0,60,70,80,90,100}。
LOOKUP函数以A1为查找值,返回第二参数中小于等于A1的最大数值,也就是要找所有弟弟中的大弟弟,并第三参数{"F","E","D","C","B","A"}中对应位置的字符串。
3、建立对照
接下来这种方法看起来不够牛逼了,需要先在Excel中建立一个对照表:
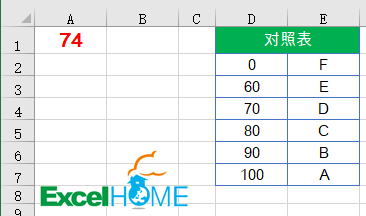
然后使用VLOOKUP函数在对照表中执行近似匹配的查询:
=VLOOKUP(A1,D2:E7,2)
这里有两点需要注意:
1、是对照表中的首列使用升序排序;
2、是VLOOKUP函数省略第四参数,返回精确匹配值或近似匹配值。如果找不到精确匹配值,则返回小于待查询内容(A1)的最大值。
相对于其他公式,建立对照表的方法看似繁琐,但是在实际应用中更便于修改标准,而不必重新编辑公式。
4、MATCH函数
=MID("FEDCBA",MATCH(A1,{0,60,70,80,90,100}),1)
MATCH函数的作用是查询某个内容在一行或一列中的位置。
本例中MATCH函数使用A1单元格的内容作为查询值,在第二参数{0,60,70,80,90,100}中用近似匹配的方式查找A1所处的位置,返回的结果用作MID函数的第二参数。
MID 函数在文本字符串"FEDCBA"中截取字符串,截取的指定开始位置,就是由MATCH函数计算出的结果,截取的字符串长度为1。
这个公式相对比较复杂一些,看不懂的小伙伴们也不必纠结,先简单做个了解就好。
四个公式,四种不同的思路,你最喜欢哪一种呢?
今天的内容就是这些,祝各位小伙伴们一天好心情!
图文制作:祝洪忠

后台回复“入群”即可加入小z数据干货交流群

















 2454
2454




 到【灌水乐园】发言
到【灌水乐园】发言







