




一、NLP简介
NLP: Natural Language Processing 自然语言处理
统计自然语言处理运用了推测学、机率、统计的方法来解决上述,尤其是针对容易高度模糊的长串句子,当套用实际文法进行分析产生出成千上万笔可能性时所引发之难题。处理这些高度模糊句子所采用消歧的方法通常运用到语料库以及马可夫模型(Markov models)。统计自然语言处理的技术主要由同样自人工智能下与学习行为相关的子领域:机器学习及资料采掘所演进而成。
二、文本处理的流程
【1】文本相似度分析:从海量数据(文章,评论)中,把相似的数据挑选出来
【2】步骤:
把评论翻译成机器看的懂的语言
使用机器看的懂得算法轮询去比较每一条和所有评论的相似程度
把相似的评论挑出来
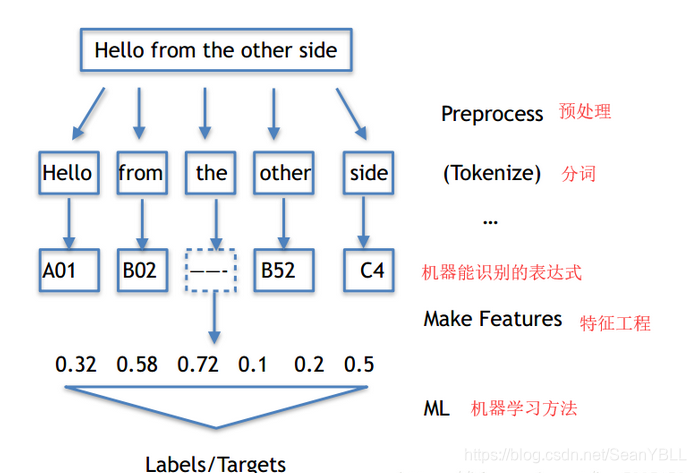
【3】分词
英语用NLTK,中文用jieba。
【3】去掉停用词
【4】把评论翻译成机器看的懂的语言
1、分词
2、制作词袋模型(bag-of-word)
3、用词袋模型制作语料库(corpus)
4、把评论变成词向量
三、jieba中文分词
【1】特点:
1、支持三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析
- 全模式:把句子中所有的可以组成词的词语都扫描出来,速度非常快,但是不能解决歧义
- 搜索引擎模式:在精确模式的基础上,对长词再次进行切分,提高召回率,适合用于搜索引擎分词
2、支持繁体分词
3、支持自定义词典
4、MIT授权协议
【2】算法
- 基于前辍词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
- 采取了动态规划查找最大概率路径,找出基于词频的最大切分组合
- 对于未登陆词,采用了基于汉字成词的能力的HMM模型,使用Viterbi算法
【3】主要功能
1、分词
jieba.cut方法接受三个输入参数:需要分词的字符串;(cut_all 参数用来控制是否采用全模式HMM 参数用来控制是否使用HMM模型)jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用HMM模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细- 待分词的字符串可以是unicode或UTF-8字符串、GBK字符串。注意:不建议直接输入GBK字符串,可能无法预料的错误解码成UTF-8
ji
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









