



 本文介绍了在Python爬虫中GET和POST请求的区别,包括数据位置、长度限制、安全性、编码需求等,并展示了如何使用urllib库进行get和post操作的实际例子。
本文介绍了在Python爬虫中GET和POST请求的区别,包括数据位置、长度限制、安全性、编码需求等,并展示了如何使用urllib库进行get和post操作的实际例子。
最近在学习爬虫的过程中,越到后面越感到难受,忍不住写下这篇总结。
请求方式现在认识到的总共有两种,一种是post,另一种则是get,从网上搜索到的两种方式的区别如下:
- get用来获取数据,post用来提交数据。
- get将参数放在url中,post将参数放在body中。
- get的参数有长度限制,post没有。
- get的参数只能是ASCII字符,post支持多种编码方式。
- get的请求可以被缓存、收藏和保存在浏览器历史记录中,post不可以。
- get的请求比post更不安全,因为参数直接暴露在url上。
从上方不难看出,get方法更加的不安全,个人认为会更加容易爬取一些,所以我们的总结从get方法说起
get
# 导包
import urllib.request
# import urllib.parse 这个在这里是没有用到的,在后续用到再说。
# 基本信息准备
url='https://movie.douban.com/j/chart/top_list?type=10&interval_id=100%3A90&action=unwatched&start=0&limit=20'
headers={
# 这里放一个在标头里面一个叫做User-Agent的信息,这里为避免泄露一些信息,我就不放了,如果不明表是哪个的话,可以去网上找些视频看一下,也可以直接私信本人。
}
# 请求对象的定制
request=urllib.request.Request(url=url,headers=headers)
# 发送请求,获取返回的数据和状态信息
reponse=urllib.request.urlopen(request)
# 将信息转换格式
content=reponse.read().decode('utf-8')
# 将转换完格式的信息写入文件
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
在get方法中有一个方法需要大家认识,那就是urllib.parse.quote,代码如下:
name = urllib.parse.quote('周杰伦')
# 这个方法适用于当我们抓取get请求页面的url中包含中文时需要用到。
# 转换完成之后就可以将其加到我们url的后面。
post
import json
import urllib.request
import urllib.parse
# 基本信息准备
url='https://fanyi.baidu.com/sug'
headers={
# 同上
}
# 由于post请求的参数放置在body中,所以我们不能像get请求那样将一些详细参数放到url中。
# 而是要将其用一个字典包含,后续放在请求对象的定制当中。
data={
'kw':'spider'
}
#post请求的参数必须进行编码
data=urllib.parse.urlencode(data).encode('utf8')
# 请求对象的定制
request=urllib.request.Request(url=url,data=data,headers=headers)
# 模拟浏览器向服务器发送请求,获取数据
response=urllib.request.urlopen(request)
# 转换格式
content=response.read().decode('utf8')
# 字符串——>json对象
obj=json.loads(content)
print(obj)
# post 请求方式的参数必须编码 data=urllib.parse.urlencode(data).encode('utf8')
# 编码之后 必须调用encode方法 data=urllib.parse.urlencode(data).encode('utf8')
# 参数是放在请求对象定制的方法中 request=urllib.request.Request(url=url,data=data,headers=headers)
另外更值得一提的是post请求的url并不是浏览器上方的一个url
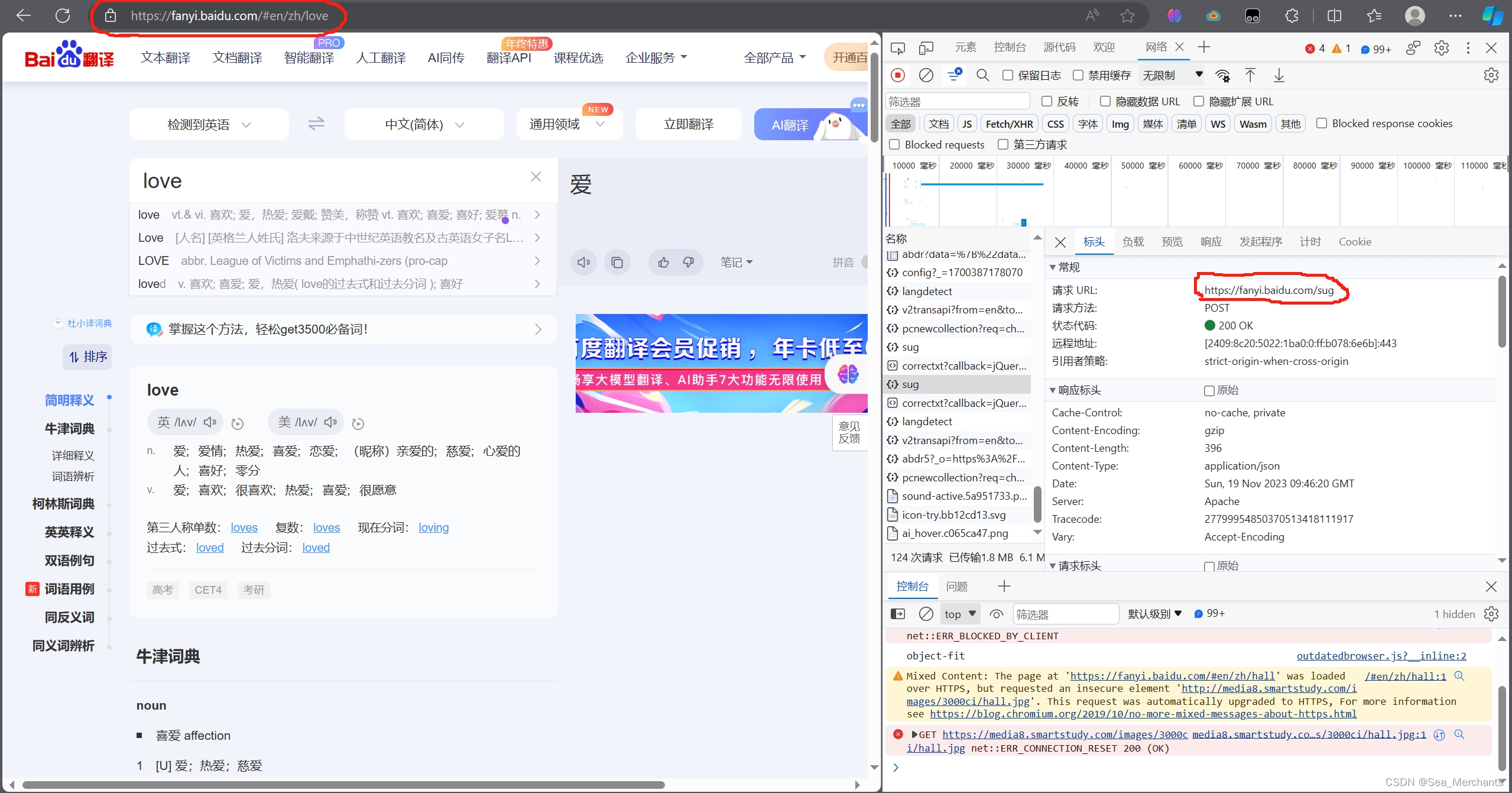
而是在调试器的网络中寻找到的。
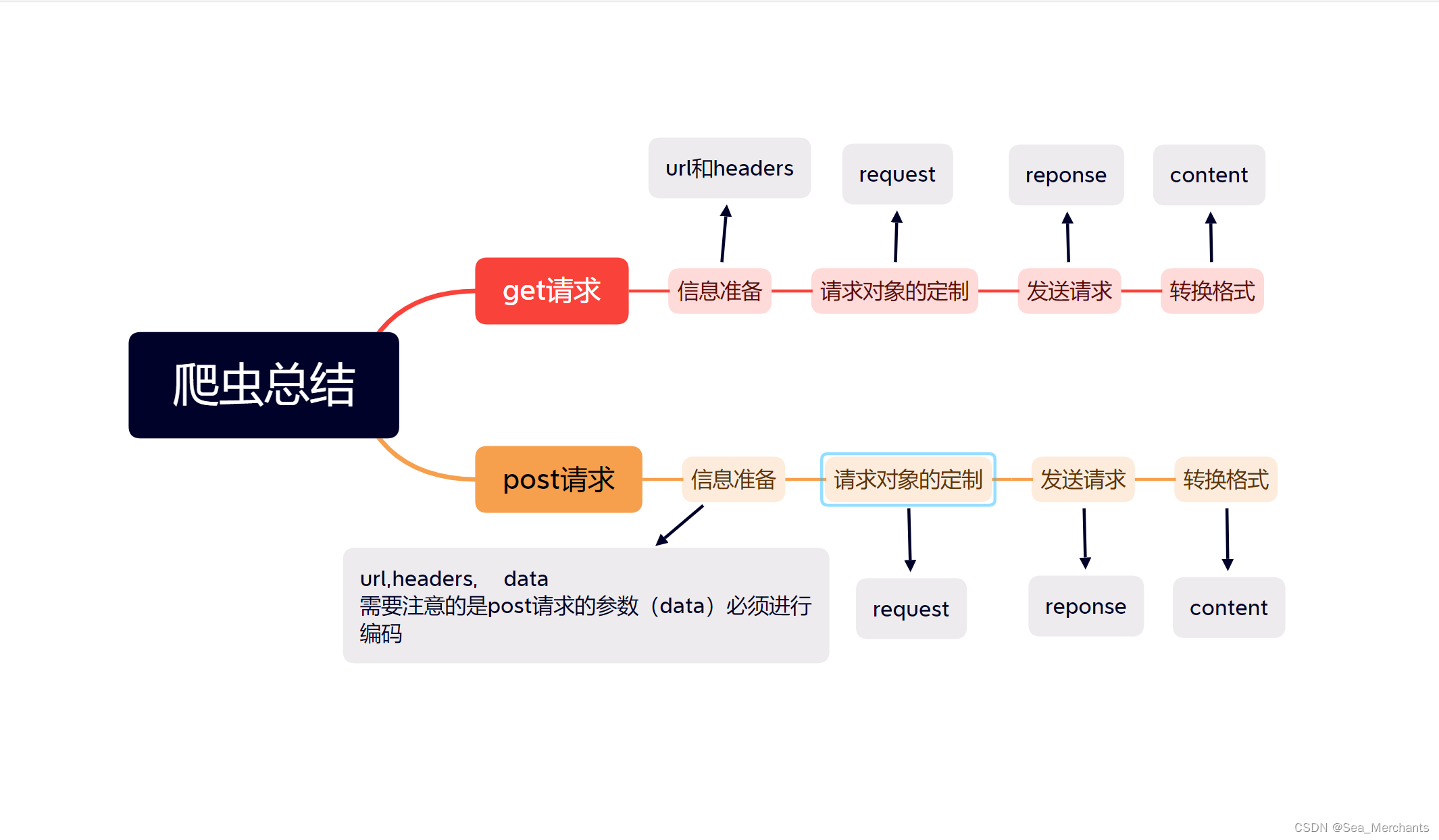
到这里整篇文章几乎就结束了。下面是我做的一个思维导图,大家可以看一下。


















 3839
3839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











