



视频教程:黑马程序员P62-80
数据容器入门
目录
为什么学习数据容器:

Python中的数据容器
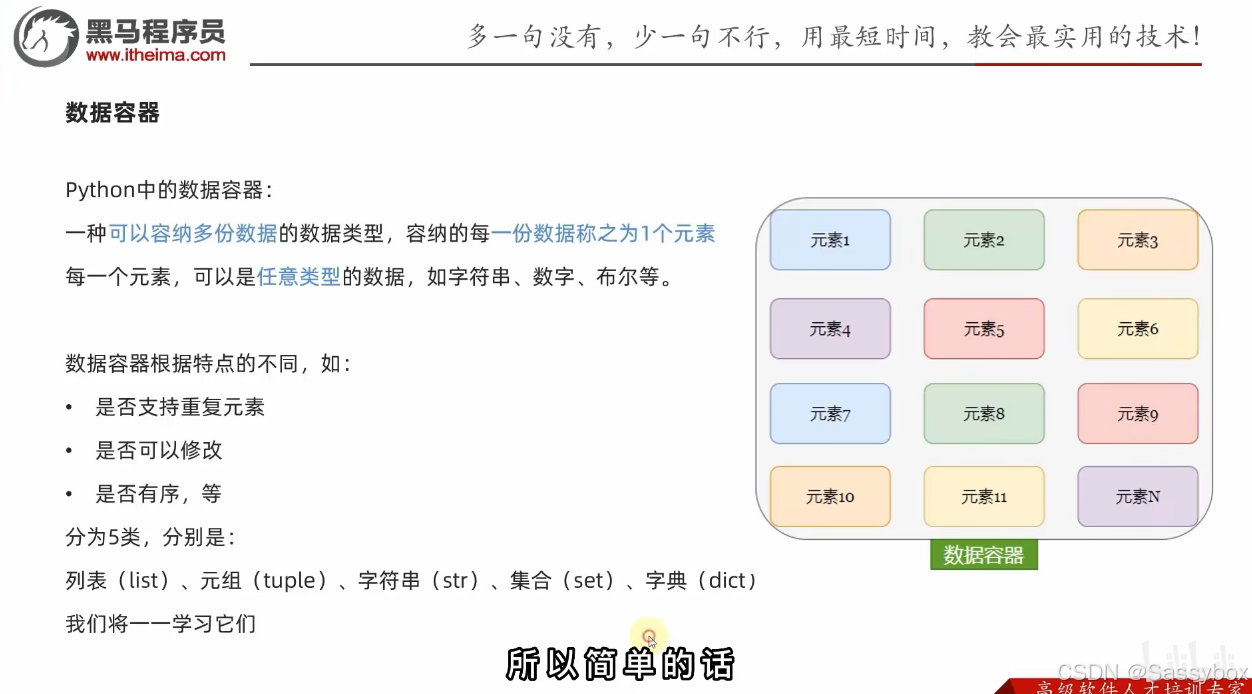
数据容器-list(列表)
列表的定义:
列表的基本语法 :
[元素1,元素2,..............]
list的特点:列表中的元素类型不受限,可以是字符串,整型,甚至可以是列表
嵌套列表:列表里面的元素含有列表
'''
数据容器--list列表
'''
#定义一个列表
my_list=["itheima","itcast","python"]
print(type(my_list))
my_list=["itheima",666,True]
print(type(my_list))
#定义一个嵌套的列表
my_list=[[1,2,3],[4,5,6]]
print(type(my_list))列表的下标索引:
语法: 列表[下标索引]
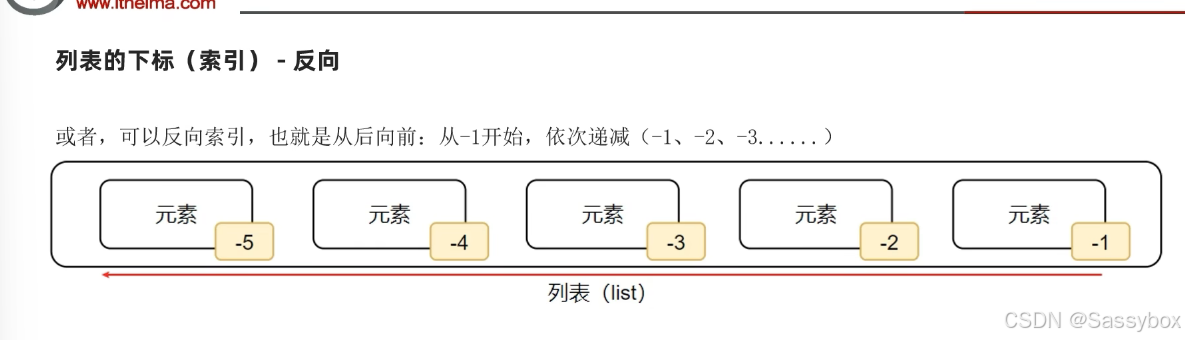
嵌套列表
#定义一个嵌套的列表
my_list=[[1,2,3],[4,5,6]]
print(type(my_list))#定义一个列表
name_list=["Tom",'Lily',"Rose"]
print(name_list [-1])
#取出嵌套列表的元素(目标取出数字5)
my_list=[[1,2,3],[4,5,6]]
print(my_list[1][1])
列表的常用操作:
列表添加元素:
1.+ 运算符
list=[3,4,5]
list=list+[7]
print(list)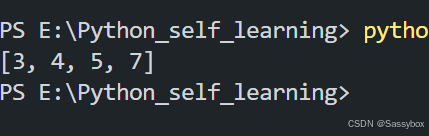
2.append()方法 在尾部追加元素
3.extend()将另一个迭代对象添加到列表对象尾部
index()方法
查询元素的下标值
功能:查找指定元素在列表的下标,查不到则报错
语法:列表.index(元素)
index为列表对象(变量)内置的方法(函数)
mylist=["Sassybox","Flower","Python"]
#1.1查找元素的下标索引
index=mylist.index("Sassybox")
print(index)
#1.2被查找的元素不存在会报错
index=mylist.index("Goat")
print(index)2.修改元素的值
#2.修改特定下标索引的值
mylist[0]="Box"
print(mylist)3.在指定位置插入元素
语法:列表.insert(下标,元素)
#3.插入元素
mylist.insert(1,"Banana")
print(mylist)4.在指定位置追加元素
1.追加方法1,使用append追加单个元素在尾部
语法:列表.append(元素),把指定元素放到列表的尾部
#4.追加元素
mylist.append("Apple")
print(mylist)2.追加方法2,使用,在列表的尾部追加一批元素
语法:列表.extend(其他数据容器),将其他数据容器的内容取出来追加到列表的尾部
mylist2=["A","B","C","D"]
mylist.extend(mylist2)
print(mylist)append()方法
append() 方法为就地修改的操作,返回值为None,修改原列表不返回新列表
a=[1,2]
b=a.append('3')
print(b)输出结果是None,原因在于append()方法的返回值为None赋值给b
extend()方法
extend()方法也是就地修改,返回值为None
a=[1,2]
b=a.extend(list(range(3,5)))
print(a,b)
extend()和append()方法的区别
extend()方法接受一个可迭代对象
5.删除元素
语法1:del 列表[下标]
del语句删除方法,仅能满足删除元素
del mylist[3]
print(mylist)语法2:列表.pop(下标)
pop方式不仅能够删除元素,并且能够将被删除的元素作为返回值得到,进行储存
mylist=["Sassybox","box","Sexybox"]
element=mylist.pop(2)
print(mylist)6.列表的修改功能
删除元素在列表的第一个匹配项
语法:列表.remove(元素) 会删除第一个
mylist=["Sassybox","box","Sexybox","box","Banana"]
mylist.remove("box")
print(mylist)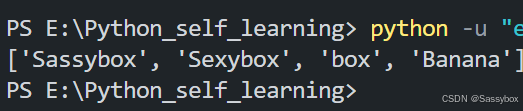
输出结果可见删除第一个出现的元素,本例即"box"
7.清空列表
#清空列表
mylist.clear()
print(mylist)8.统计某一个元素在列表内的数量
语法:列表.count(元素)
9.统计列表内有多少元素
语法:len(列表) 列表有5个元素
my_list=[1,2,3,4,5]
print(len(my_list))总结: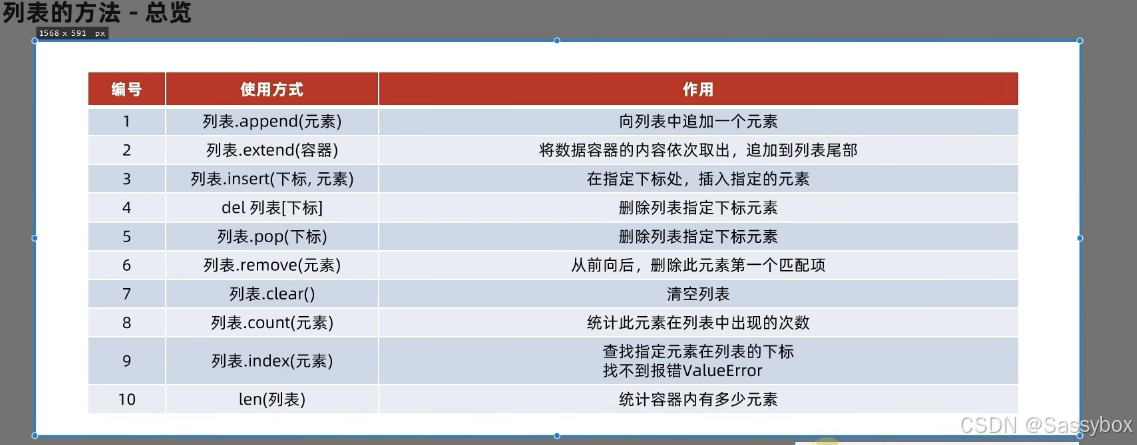
列表的基本操作:(本讲涉及的全部代码)
mylist=["Sassybox","Flower","Python"]
#1.1查找元素的下标索引
index=mylist.index("Sassybox")
print(index)
#1.2被查找的元素不存在会报错
#index=mylist.index("海绵宝宝")
#print(index)
#2.修改特定下标索引的值
mylist[0]="Sexybox"
print(mylist)
#3.插入元素
mylist.insert(1,"Banana")
print(mylist)
#4.追加元素
mylist.append("Apple")
print(mylist)
mylist2=["A","B","C","D"]
mylist.extend(mylist2)
print(mylist)
#方法一:通过del语句删除
del mylist[3]
print(mylist)
#方法二: 列表.pop(下标)
mylist=["Sassybox","box","Sexybox"]
element=mylist.pop(2)
print(mylist)
#列表的修改功能
mylist=["Sassybox","box","Sexybox","box","Banana"]
mylist.remove("box")
print(mylist)
#清空列表
mylist.clear()
print(mylist)
#统计某一个元素出现的数量
mylist=["Sassybox","box","Sexybox","box","Banana"]
num=mylist.count("box")
print(num)
#统计列表内有多少元素
my_list=[1,2,3,4,5]
print(len(my_list))
列表的遍历:
通过while循环
def list_while_func():
my_list=["Sassybox","Python","Robots"]
index=0
while index<len(my_list):
element=my_list[index]
print(f"来自列表的元素:{element}")
index+=1
list_while_func()通过for循环
def list_for_func():
my_list=[1,2,3,4,5]
for element in my_list:
print(f"列表的元素有:{element}")
list_for_func()两个循环的区别

分别使用for循环和while循环取出列表中的偶数
while循环 偶数判断使用if语句,索引一定要更迭😅
def get_num():
my_list=[1,2,3,4,5,6,7,8,9,10]
index=0
new_list=[]
while index<len(my_list):
if my_list[index]%2==0:
new_list.append(my_list[index])
index+=1
print(new_list)
get_num()for循环 注意缩进😅
def get_num_through_forloop():
my_list=[1,2,3,4,5,6,7,8,9,10]
new_list=[]
for temp in my_list:
if temp%2==0:
new_list.append(temp)
print(new_list)
get_num()
列表推导式:
列表推导式的简单语法:
[exp for variable in iterable if condition]
exp为表达式 ,condition为条件表达式,决定哪些元素会被包含在最终生成的列表中
列表推导式的应用:
例如:使用列表推导式生成10个数字5的列表
newlist=[ 5 for _ in range(10)]
print(newlist)数据容器-元组
为什么引入元组:想让传递的信息不被篡改

元组的定义:
元组的定义使用小括号,数据可以是不同的数据类型
定义空元组的方法 :方式1. 变量名称=()
方式2.变量名称=tuple()
'''
演示tuple的定义和操作
'''
#定义空元组
t2=()
t3=tuple()
#定义1个元素的元组
t2=('Hello',) #单个元组必须有逗号,否则不是元组类型
t4=("Hello")
print(type(t4))
#定义3个元素的元组
t1=(1,"Hello",True)
print(f"t1的类型是:{type(t1)}")
#元组的嵌套
t5=((1,2,3),(4,5,6))
print(type(t5))
#下标索引取出元素
element=t5[1][2]
print(element)元组的操作:
1.查找元素对应的索引
index=t5.index("Python")
print(index)2.统计单个元素出现的次数
t6=("Sassybox","box","Python","Java","C")
nums=t6.count("Java")
print(nums)3.统计总元素个数
t8=("Sassybox","Robots","Volleyball")
print(len(t8))元组的遍历:
1.while loop
t8=("Sassybox","Robots","Volleyball")
index=0
while index<len(t8):
print(f"元组的元素有 {t8[index]}")
index+=1
2.for loop
t8=("Sassybox","Robots","Volleyball","Kpop")
for temp in t8:
print(f"元组的元素有{temp}")元组的注意事项:
元组元素不允许修改,若尝试修改
t8[0]="Boxer"
可见输出结果:

存在一种情况 元组里面嵌套了列表,可以修改列表里面的内容
t9=(1,2,["Sassybox","Robots","Volleyball","Kpop"])
t9[2][1]="机器人"
t9[2][2]="排球"
print(t9)数据容器-字符串
字符串:字符的数据容器

value=my_str[2]
print(value)字符串同元组一样不支持修改
value=my_str[2]
print(value)
my_str[0]="a"
print(my_str)可见输出结果:

字符串的操作:
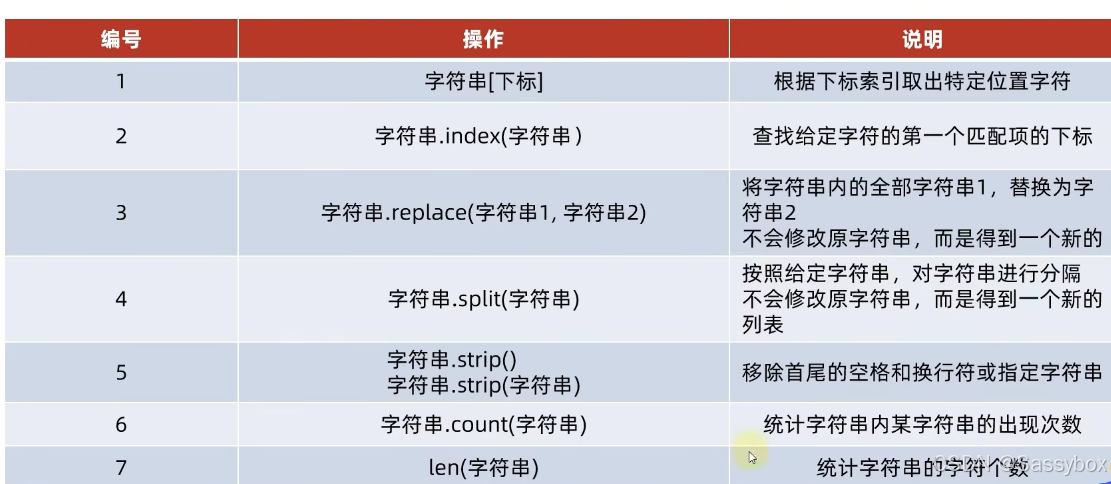
查找特定字符串的下标索引值
value=my_str.index("is")
print(value)字符串的替换:
语法:字符串.replace(字符串1,字符串2)
功能:把字符串内全部的字符串1换成字符串2
不是修改字符串本身而是得到一个新的字符串
#字符串的替换
new_my_str=my_str.replace("boxer","dancer")
print(new_my_str)注意:my_str本身不会被修改,只会得到一个返回值,因此需要用new_my_str来进行接收
字符串的分割:
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔字符串,将字符串划分为多个字符串,并存入列表对象中
字符串本身不变,而是得到了一个列表对象
my_str="Hello Sassybox! Peace be with you and your family"
my_str_list=my_str.split("!")
print(type(my_str_list))
print(my_str_list)根据split传入的参数对原先的字符串进行分割,这里我使用了感叹号!进行分割,得到一个列表对象并且用my_str_list来接收
输出结果:

字符串的规整操作:
默认情况(去掉前后空格) 语法:字符串.strip()
传入参数的情况 (去掉前后指定字符串) 语法:字符串.strip(字符串)
默认情况,不传入参数
my_str=" Peace and love "
new_my_str=my_str.strip()
print(new_my_str)输出结果:观察到前后空格都去除掉了

传入参数的情况
my_str="12Peace and love21"
new_my_str=my_str.strip("12")
print(new_my_str)想试一下给strip()传两个参数,发现报错了。strip()至多传一个参数
![]()
正常的输出结果:可以发现"12"和"21"都被去除掉了,这是因为strip()规整的原理:把传入的字符串"12"进一步划分为两个小的字符串,去除指定的"1"和"2",因此"21"也被删除了

统计字符串中特定字符串出现的次数:
my_str="Love yourself and Just be yourself"
count=my_str.count("yourself")
print(count)统计字符串的长度:
my_str="Do not mind what others say about you"
print(len(my_str))
数据容器-切片
序列:
内容连续、有序,能够用下标索引的一类数据容器,之前涉及的列表、元组、字符串都可以视作序列
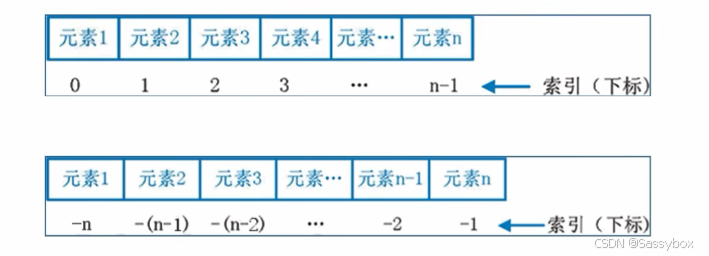
切片:从一个序列中取出一个子序列
语法:序列[起始下标:结束下标:步长]

切片操作:
#对list切片,从1开始,4结束但不包含4,步长为1
my_list=[0,1,2,3,4,5,6]
result1=my_list[1:4:1]
print(result1)
#对tuple进行切片,从头开始到最后结束步长为1
my_tuple=(0,1,2,3,4,5,6)
result2=my_tuple[::] #起始和结束不写,步长为1不写
print(result2)
#对str进行切片,从头开始到最后结束,步长为2
my_str="01234567"
result3=my_str[::2]
print(result3)
#对str进行切片,从头开始到最后结束,步长为-1
my_str="01234567"
result4=my_str[::-1]
print(result4)
#对列表进行切片,从3开始到1结束,步长为-1
my_list=[0,1,2,3,4,5,6]
result5=my_list[3:1:-1]
print(result5)
#对元组进行切片,从头开始,到尾结束,步长-2
my_tuple=(0,1,2,3,4,5,6)
result6=my_tuple[::-2]
print(result6)
text="Sassybox"
print(text[0:5:2])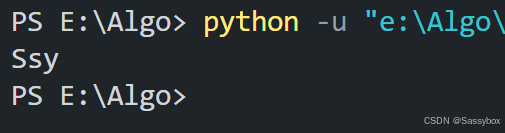
(步长为2时的切片)
切片负索引的使用:
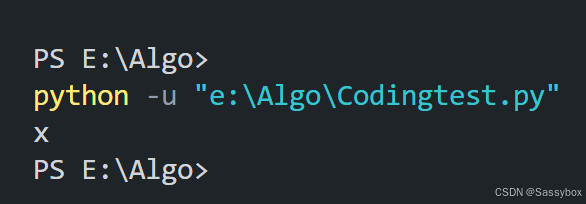
输出最后一个字母:
text="Sassybox"
print(text[-1])输出效果:
输出倒数3个字母
text="Sassybox"
print(text[-3:])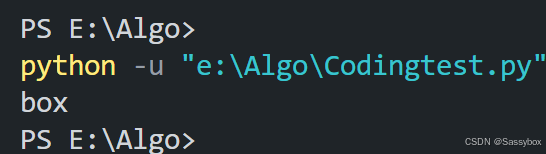
数据容器-集合
为什么学习集合:场景需要对内容进行去重处理
语法:
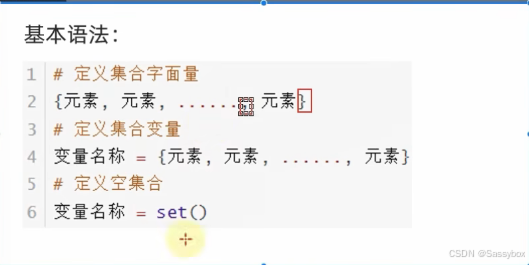
集合的定义
#定义空集合
my_set_empty=set()
print(my_set_empty)
print(type(my_set_empty))
#定义集合
my_set={"Sassybox","Robots","Banana","Sassybox","Robots","Banana"}
print(my_set)
print(type(my_set))输出结果可以看出集合去掉重复元素,并且元素无序

集合的常见操作:
集合的修改:
集合无序,因此不支持下标索引访问,但允许修改
集合添加新元素:
语法:集合.add(元素)
my_set.add("Python")集合移除元素:
语法:集合.remove(元素)
my_set.remove("Sassybox")
print(my_set)
集合随机取出元素:
语法:集合.pop() 能够从集合中随机取出一个元素,会得到一个元素,同时原集合被修改
my_set={"Sassybox","Robots","Banana","Sassybox","Robots","Banana"}
element=my_set.pop()
print(f"现在的集合是{my_set}")
print(f"取出的元素是{element}")集合的清空:
语法:集合.clear()
my_set={"Sassybox","Robots","Banana","Sassybox","Robots","Banana"}
my_set.clear()
print(my_set)
输出结果:空集合

集合的差集
语法:集合1.difference(集合2)
功能:取出集合1和集合2的差集(集合1有而集合2没有),得到一个新集合
my_set1={1,2,3,5,8}
my_set2={1,4,7,8}
my_set3=my_set1.difference(my_set2)
print(my_set3)集合的消除交集(A-A∩B)
语法:集合1.difference_update(集合2)
功能:在集合1内删除和集合2相同的元素,集合1被修改,集合2不变
set1={1,2,3}
set2={1,5,6}
set1.difference_update(set2)集合的合并
语法:集合1.union(集合2)
功能:将集合1,2组合成新的集合,集合1和集合2不变
set1={1,2,3}
set2={1,5,6}
set3=set1.union(set2)
print(set3)集合统计数量
set4={1,3,5,7}
num=len(set4)
print(num)集合的遍历
set1={1,2,3,4,5}
for element in set1:
print(element)数据容器-字典
为什么需要字典:
通过某个数据找到与之相连的数据,例如使用Python录入学生成绩,姓名和成绩相关联

字典的定义:

#定义字典
my_dic={"Sassybox":100,"Lucy":96,"Tony":94}
#定义空字典
my_dic2={}
my_dic3=dict()
print(type(my_dic))
print(type(my_dic2))
print(type(my_dic3))
字典中的key是唯一的
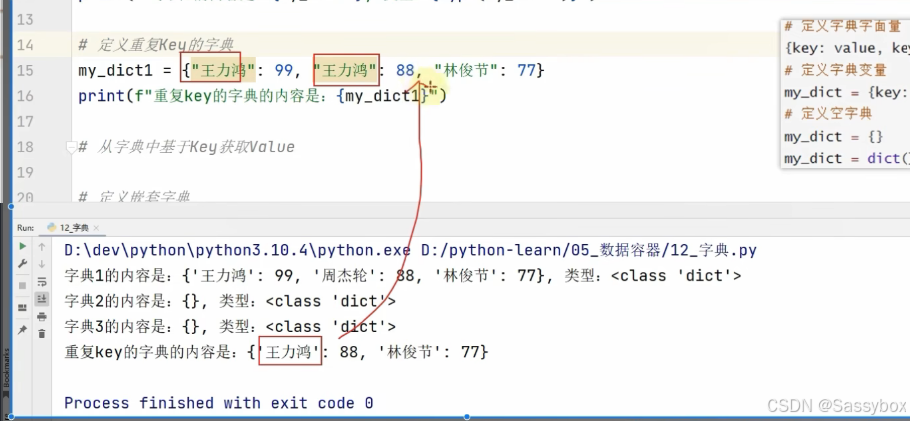
字典数据的获取:
同集合一样,字典不能通过下标索引访问,而是通过key来获取对应值
字典的嵌套:
字典的key和value可以是任意数据类型(key不能是字典)
#字典的嵌套
stu_score_dict={
"Sassybox":{
"English":100,
"Math":90,
"Physics":100
},
"Slowbox":{
"English":80,
"Math":90,
"Physics":80
}
}
print(stu_score_dict)在嵌套字典中获取数据
score=stu_score_dict["Sassybox"]["Math"]
print(score)字典的注意事项:
1.Key和Value可以是任何类型,但是Key不可以为字典
2.字典内Key不允许重复,重复添加等于覆盖原有数据
3.字典不可以用下标索引,而是通过Key检索Value
字典的常用操作:
字典新增元素和修改元素:
语法:字典[Key]=Value
my_dict={"Sassybox":90,"Slowbox":88,"Cunningbox":86}
#新增元素
my_dict["Sillybox"]=85
print(my_dict)
#元素的修改
my_dict["Sassybox"]=98
print(my_dict)字典删除元素:
语法:字典.pop(Key)
score=my_dict.pop("Sillybox")
print(f"删除的分数是{score}")
print(f"删除后的字典为{my_dict}")字典清空元素:
语法:字典.clear()
my_dict.clear()
print(my_dict)字典获取全部的Key:
keys=my_dict.keys()
print(keys)字典的遍历:
方式1:通过全部的Key得到对应的Value
#遍历字典
for key in keys:
print(f"字典的Key是{key},其对应的value是{my_dict[key]}")方式2:直接对字典进行for loop,在每一个loop中得到key
for key in my_dict:
print(f"字典遍历到的Key是{key}")
print(f"其对应的Value是{my_dict[key]}")
统计字典的元素数量:
my_dict={"Sassybox":90,"Slowbox":88,"Cunningbox":86}
num=len(my_dict)
print(f"字典中的元素数量有{num}个")字典的特点:

数据容器总结
数据容器视角分类

元组,字符串不支持修改, 字典,集合不支持重复元素
数据容器的特点
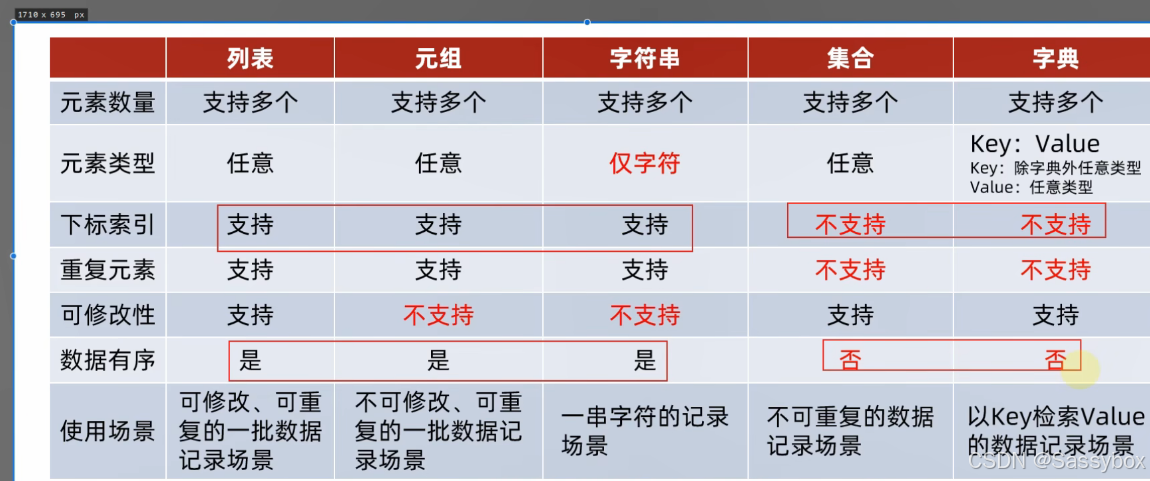
数据容器的适用场景

数据容器的通用操作
数据容器的基本操作:
my_list=[1,2,3,4,5]
my_tuple=(1,2,3,4,5)
my_str="abcdefg"
my_set={1,2,3,4,5}
my_dict={"key1":1,"key2":2,"key3":3,"key4":4,"key5":5}
#len元素个数
print(f"列表的元素个数有{len(my_list)}")
print(f"元组的元素个数有{len(my_tuple)}")
print(f"字符串的元素个数有{len(my_str)}")
print(f"集合的元素个数有{len(my_set)}")
print(f"字典的元素个数有{len(my_dict)}")
#max最大元素 (min同理)
print(f"列表的最大元素有{max(my_list)}")
print(f"元组的最大元素有{max(my_tuple)}")
print(f"字符串的最大元素有{max(my_str)}")
print(f"集合的最大元素有{max(my_set)}")
print(f"字典的最大元素有{max(my_dict)}")
数据容器的类型转换:
容器转列表
#容器转列表
print(f"列表转列表的结果是:{list(my_list)}")
print(f"元组转列表的结果是:{list(my_tuple)}")
print(f"字符串转列表的结果是:{list(my_str)}")
print(f"集合转列表的结果是:{list(my_set)}")
print(f"字典转列表的结果是:{list(my_dict)}")容器转元组
#容器转元组
print(f"列表转元组的结果是:{tuple(my_list)}")
print(f"元组转元组的结果是:{tuple(my_tuple)}")
print(f"字符串转元组的结果是:{tuple(my_str)}")
print(f"集合转元组的结果是:{tuple(my_set)}")
print(f"字典转元组的结果是:{tuple(my_dict)}")容器转字符串
#容器转字符串
print(f"列表转字符串的结果是:{str(my_list)}")
print(f"元组转字符串的结果是:{str(my_tuple)}")
print(f"字符串转字符串的结果是:{str(my_str)}")
print(f"集合转字符串的结果是:{str(my_set)}")
print(f"字典转字符串的结果是:{str(my_dict)}")容器转集合
#容器转集合
print(f"列表转集合的结果是:{set(my_list)}")
print(f"元组转集合的结果是:{set(my_tuple)}")
print(f"字符串转集合的结果是:{set(my_str)}")
print(f"集合转集合的结果是:{set(my_set)}")
print(f"字典转集合的结果是:{set(my_dict)}")转字典缺少键值对的关键要素,则不能完成转换

容器的通用排序功能:
正向排序:(排序后都变成了列表对象)
my_list=[3,1,2,5,4]
my_tuple=(3,1,2,5,4)
my_str="bdcefga"
my_set={3,1,2,5,4}
my_dict={"key3":1,"key1":2,"key2":3,"key5":4,"key4":5}
print(f"列表对象排序的结果是:{sorted(my_list)}")
print(f"元组对象排序的结果是:{sorted(my_tuple)}")
print(f"字符串对象排序的结果是:{sorted(my_str)}")
print(f"集合对象排序的结果是:{sorted(my_set)}")
print(f"字典对象排序的结果是:{sorted(my_dict)}")反向排序:传入参数 reverse=True(默认为False), 对数据进行反向排序
my_list=[3,1,2,5,4]
my_tuple=(3,1,2,5,4)
my_str="bdcefga"
my_set={3,1,2,5,4}
my_dict={"key3":1,"key1":2,"key2":3,"key5":4,"key4":5}
print(f"列表对象排序的结果是:{sorted(my_list,reverse=True)}")
print(f"元组对象排序的结果是:{sorted(my_tuple,reverse=True)}")
print(f"字符串对象排序的结果是:{sorted(my_str,reverse=True)}")
print(f"集合对象排序的结果是:{sorted(my_set,reverse=True)}")
print(f"字典对象排序的结果是:{sorted(my_dict,reverse=True)}")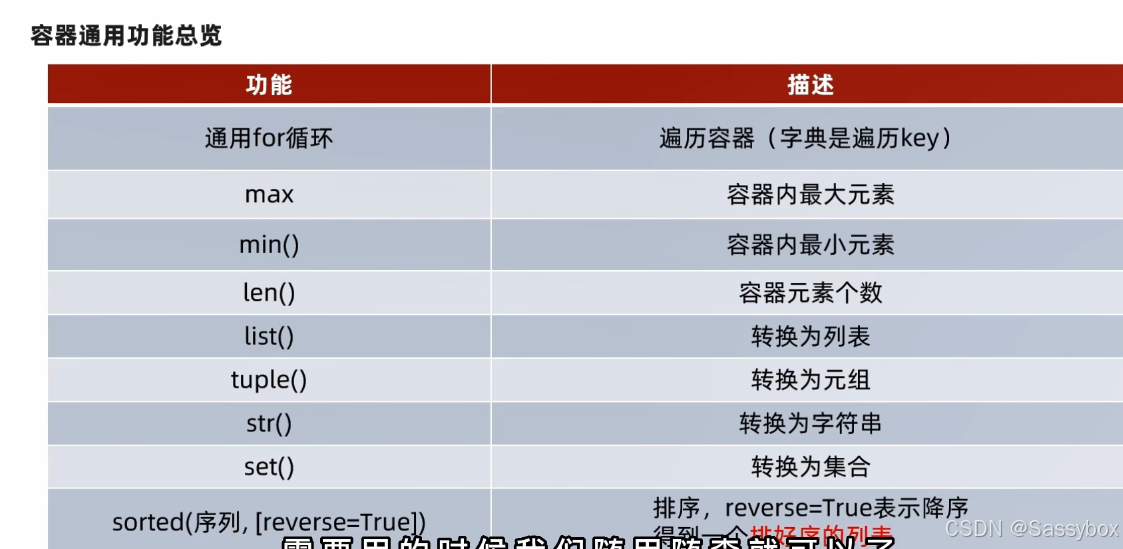


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









