




 本文深入探讨了Hive SQL中窗口函数over()的使用,特别是在不指定ROWS BETWEEN时,默认采用RANGE BETWEEN...导致的问题。通过示例展示了ROWS BETWEEN...如何按行处理数据,得到预期结果,而RANGE BETWEEN...则根据相同值范围进行累积。最终得出结论,在处理排序时,使用ROWS BETWEEN...可以确保按行基准得到正确累计。
本文深入探讨了Hive SQL中窗口函数over()的使用,特别是在不指定ROWS BETWEEN时,默认采用RANGE BETWEEN...导致的问题。通过示例展示了ROWS BETWEEN...如何按行处理数据,得到预期结果,而RANGE BETWEEN...则根据相同值范围进行累积。最终得出结论,在处理排序时,使用ROWS BETWEEN...可以确保按行基准得到正确累计。
题目:
数据:stu
subject score
数学,30
数学,50
语文,65
数学,55
英语,80
数学,50
语文,60
数学,80
语文,90
结果:
subject score num
数学,30,1
数学,50,1
数学,50,1
数学,55,1
语文,60,2
语文,65,2
英语,80,3
数学,80,4
语文,90,5
请写出SQL输出结果表
输出一:
--1)科目的改变的定位,lag()+over()得到上次的科目
select
subject,score,
lag(subject) over(order by score asc) before_subject
from stu;t1
--2)将本次科目和上次科目进行对比,如果相等则为0,否则1,初始值为1--case when
select
subject,score,
case when before_subject is null then 1
when before_subject=subject then 0 else 1 end num
from ()t1;t2
--3)统计
select
subject,score,
sum(num) over(order by score) sums
from ()t2;
--最终SQL
select
subject,score,
sum(num) over(order by score asc ) sums
from
(select
subject,score,
case when before_subject is null then 1
when before_subject=subject then 0 else 1 end num
from (select
subject,score,
lag(subject) over(order by score asc) before_subject
from stu)t1)t2;
如果我按照输出一来处理,发现最终的输出结果竟然是:
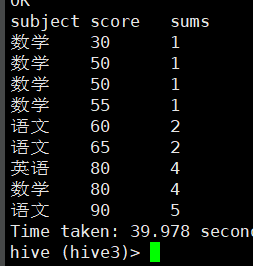
和预想的结果不一样,这是为什么呢?
其实呢,早在hive的官网中已经表明:

含义是: 当 ORDER BY 指定时缺少 WINDOW 子句,WINDOW 规范默认为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。
也就是hive本身的开窗函数over()中如果不指定rows between..的时候默认为以range between...
,那么就来看看rows和range的区别吧!
rows.... :
select
subject,score,
sum(num) over(order by score asc rows between unbounded preceding and current row) sums
from
(select
subject,score,
case when before_subject is null then 1
when before_subject=subject then 0 else 1 end num
from (select
subject,score,
lag(subject) over(order by score asc) before_subject
from stu)t1)t2;
结果:
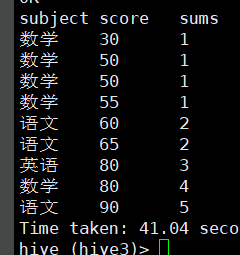
这正是我们想要的结果....所以rows 的排序设置是以行为基准,他会按照我们理想来以行挨着处理!!!
再来看看range的
range:
select
subject,score,
sum(num) over(order by score asc range between unbounded preceding and current row ) sums
from
(select
subject,score,
case when before_subject is null then 1
when before_subject=subject then 0 else 1 end num
from (select
subject,score,
lag(subject) over(order by score asc) before_subject
from stu)t1)t2;
结果:
这个和我们想要的结果有差别,就是在累计的时候只是以最后的那个相同的值累计来表达;
=========================================================================最终SQL:
select
subject,score,
sum(case when before_subject is null then 1
when before_subject=subject then 0 else 1 end ) over(order by score rows between unbounded preceding and current row) nums
from (select
subject,score,
lag(subject) over(order by score asc) before_subject
from stu)t1;
=================================总结:==================================
!!! 在开窗函数表达排序的时候,要想达到理想状态也就是以行为基准,记得写
rows between ....

















 328
328




 到【灌水乐园】发言
到【灌水乐园】发言







