 PythonPandas爬虫实战:股票数据与代理IP获取,
PythonPandas爬虫实战:股票数据与代理IP获取,




 本文介绍了如何使用Python的Pandas库通过爬虫技术从新浪财经网获取股票财务数据,并演示了如何爬取89免费代理IP列表,通过循环实现全量数据抓取。
本文介绍了如何使用Python的Pandas库通过爬虫技术从新浪财经网获取股票财务数据,并演示了如何爬取89免费代理IP列表,通过循环实现全量数据抓取。
还在为论文、大作业的数据获取而发愁吗,来试试Pandas爬虫、代码只需要一行,让爬取数据不再遥不可及。
众所周知数据的获取极其重要,而Python爬虫既实用又听起来高大上,本文通过两个实战小例子来介绍Pandas爬取表格数据。
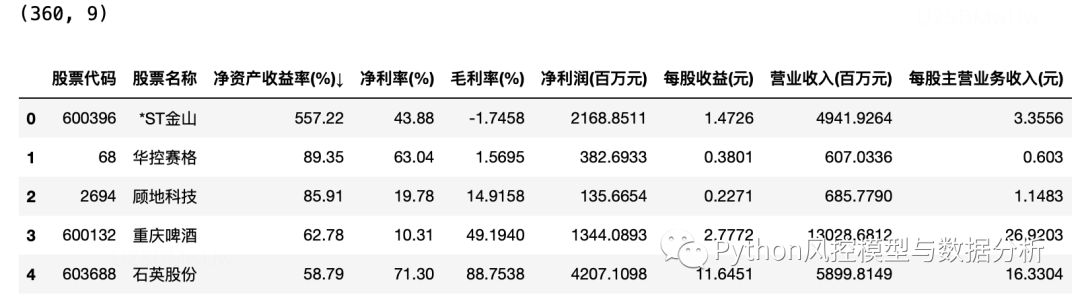
1、爬取新浪财经网股票机构的财务数据
如图可以看到,网页里的财务数据是表格形式的,通过右键检查可以定位到网页元素为table,这种结构就可以直接用pandas来爬取数据了
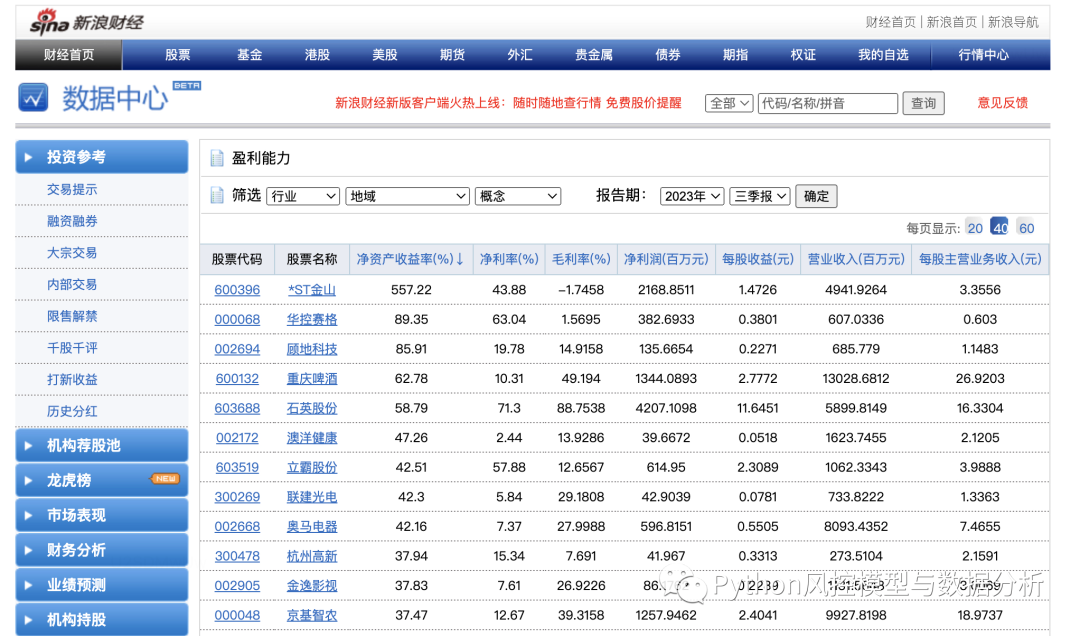
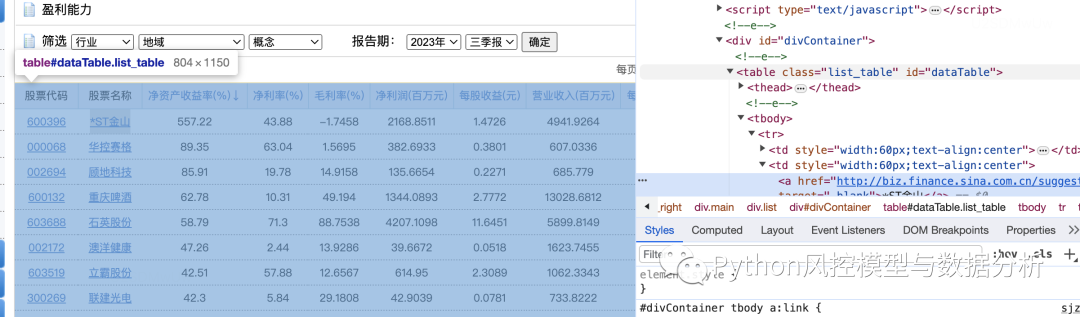
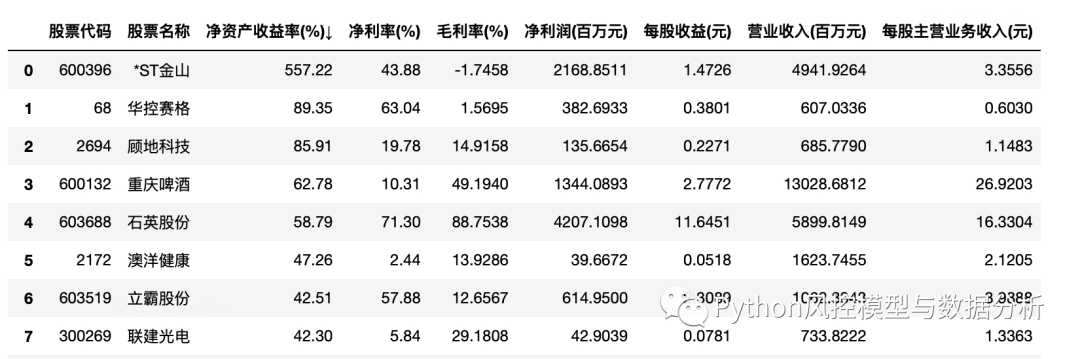
import pandas as pd``url='https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml'``df=pd.read_html(url)[0] # 取这个页面中第0个table元素``df
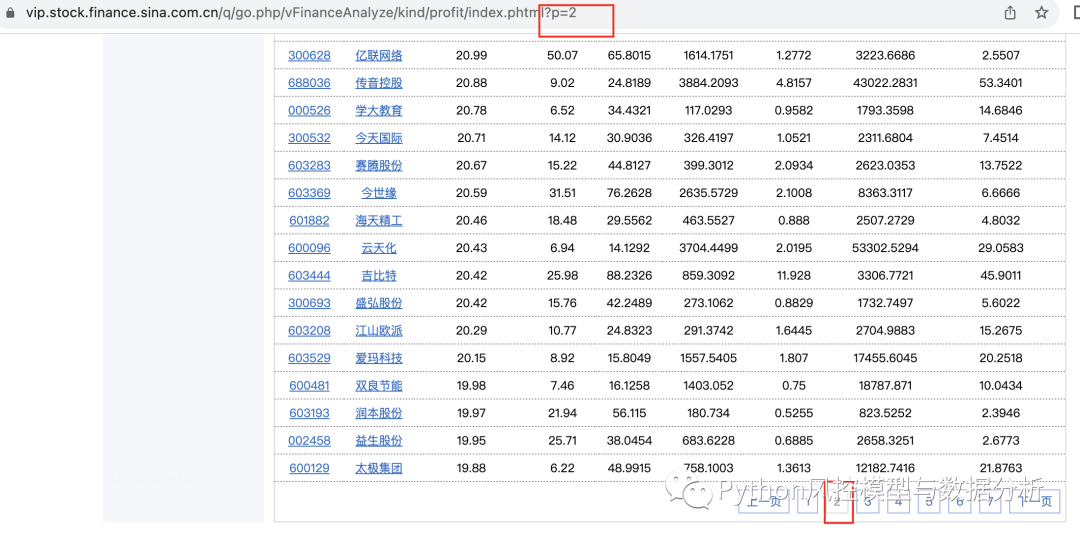
当然这只是第一页的数据,点击第二页可以看到网址后面多了?p=2,同理后面第三、四页也是如此,所以只需要循环改变url最后的页数就可以全量爬取数据了
import pandas as pd``l=[]``for i in range(1,10):` `url='https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml?p={}'.format(i)` `l.append(pd.read_html(url)[0])``df=pd.concat(l,axis=0).reset_index(drop=True)``print(df.shape)``df.head()
2、爬取89免费代理ip
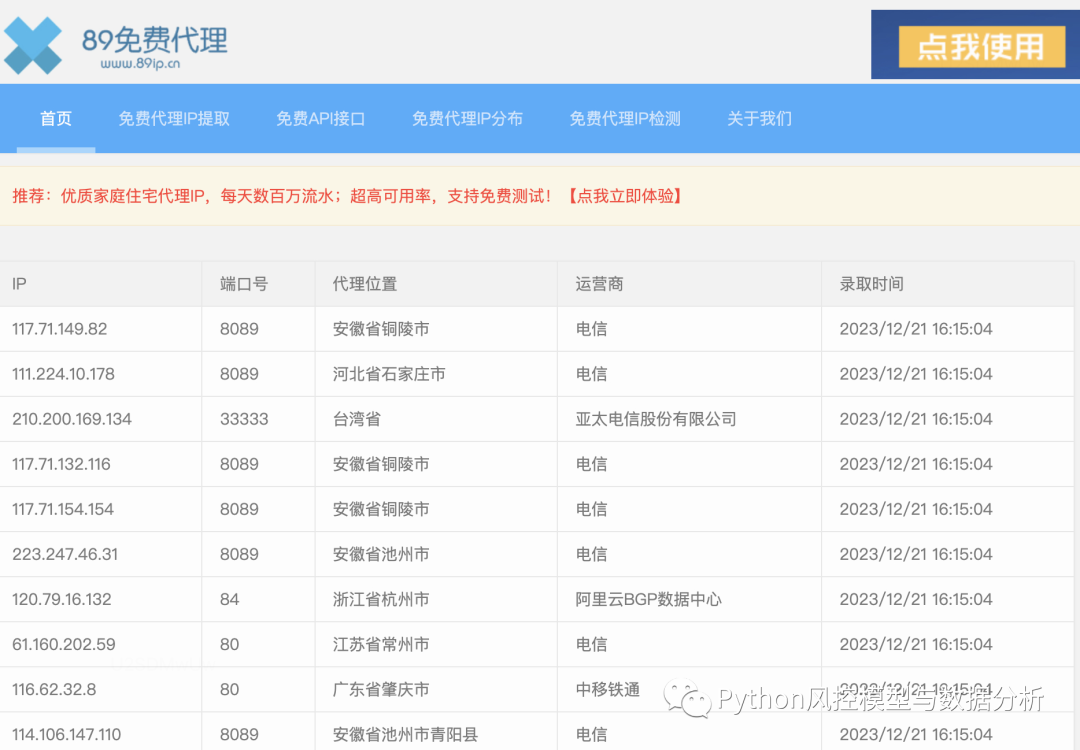
import pandas as pd``url='https://www.89ip.cn/index_1.html'``df=pd.read_html(url,encoding='utf-8')[0]``df
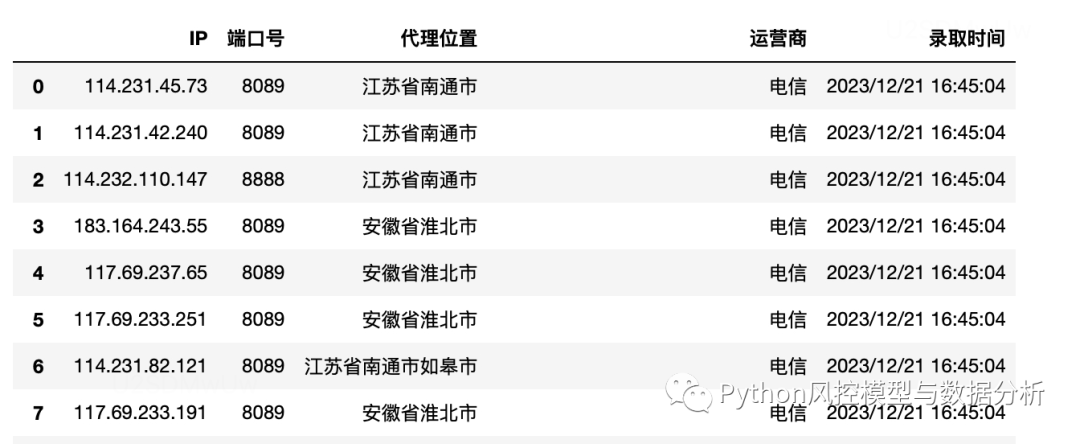
循环爬取多页
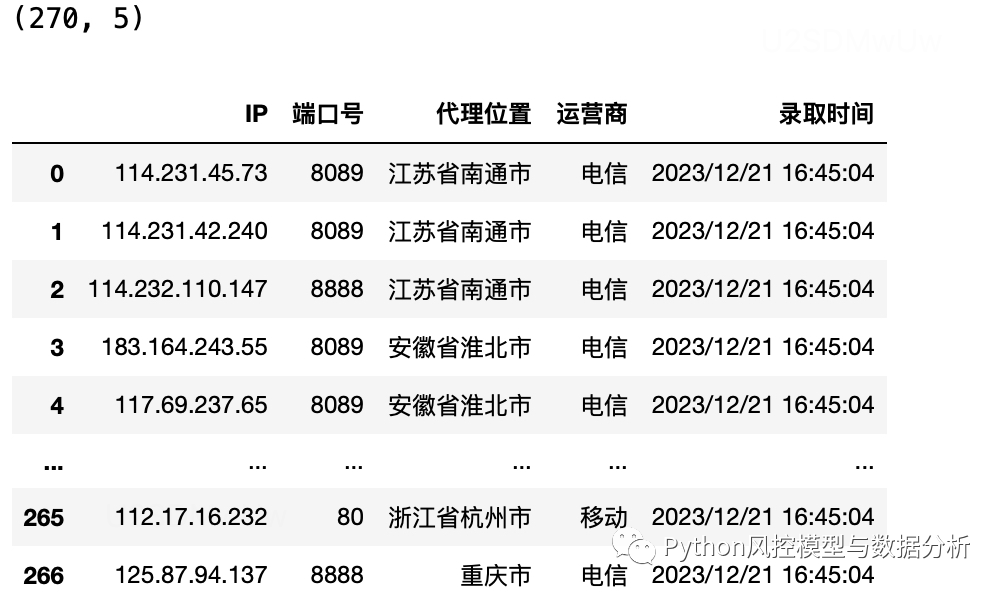
l=[]``for i in range(1,10):` `url='https://www.89ip.cn/index_{}.html'.format(i)` `l.append(pd.read_html(url,encoding='utf-8')[0])``df=pd.concat(l,axis=0).reset_index(drop=True)``print(df.shape)``df
**如果认为文章有价值的话,****也欢迎****各****位读者能够多多转发、分享,大家共同**助力**知识分享、也让笔者有动力继续写下去。**
这里先给大家展示一下我进的兼职群和最近接单的截图,小伙伴有需要也可继续往下看.





有需要Python兼职爬虫资料和兼职内推的小伙伴可扫下方二维码

题外话
感谢你能看到最后,给大家准备了一些福利!
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉优快云大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python兼职渠道推荐*
学的同时助你创收,每天花1-2小时兼职,轻松稿定生活费.

三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉
优快云大礼包:gift::[全网最全《Python学习资料》免费赠送:free:!](https://blog.youkuaiyun.com/weixin_68789096/article/details/132275547?spm=1001.2014.3001.5502)
(安全链接,放心点击)
若有侵权,请联系删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









