



 本文介绍如何使用Sweetviz和pandas_profiling这两个Python库,通过一行代码快速生成探索性数据分析报告,包括数据概述、变量分布、相关性分析等,节省数据分析时间。
本文介绍如何使用Sweetviz和pandas_profiling这两个Python库,通过一行代码快速生成探索性数据分析报告,包括数据概述、变量分布、相关性分析等,节省数据分析时间。
💮两种方法教你一行代码实现探索性数据分析报告
==探索性数据分析(EDA)== 是使用可视化方法总结和分析数据集主要特征的过程。EDA是数据科学家要做的第一部分,如果我们不懂得如何进行EDA,那么无法对数据进行进一步的建模。上一篇文章我以泰坦尼克号数据为例,介绍了如何使用python详细的进行探索性数据分析,但有时这是很耗费时间的,现在,我介绍两种方法实现一行代码生成探索性数据分析报告。分别使用以下两个包,如果没有安装的小伙伴先去安装一下。
- Sweetviz
- pandas_profiling
我们照样使用泰坦尼克号数据集进行分析,需要相关数据集的看我这篇文章:blog.youkuaiyun.com/weixin_4505…
- 先导入数据
import pandas as pd
from pandas_profiling import ProfileReport
df = pd.read_csv("train.csv")
df.head()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
df.shape
(891, 12)
🏵️1. Sweetviz
==Sweetviz== 一个python开源库,通过基本的可视化来分析数据,并生成一个html文件。这个库的主要优点是我们可以 比较数据集。 首先我们创建一个名为sweet_Analysized_report的文件,显示探索性数据分析结果。在本报告中,我们可以很容易地找到不同变量的特征,如:数量、缺失值、不同值、最大值、最小值、平均值等。具体代码和结果如下图所示
import sweetviz as sv
sweet_report = sv.analyze(df)
sweet_report.show_html('sweet_report.html')
-
==相关系数热力图==
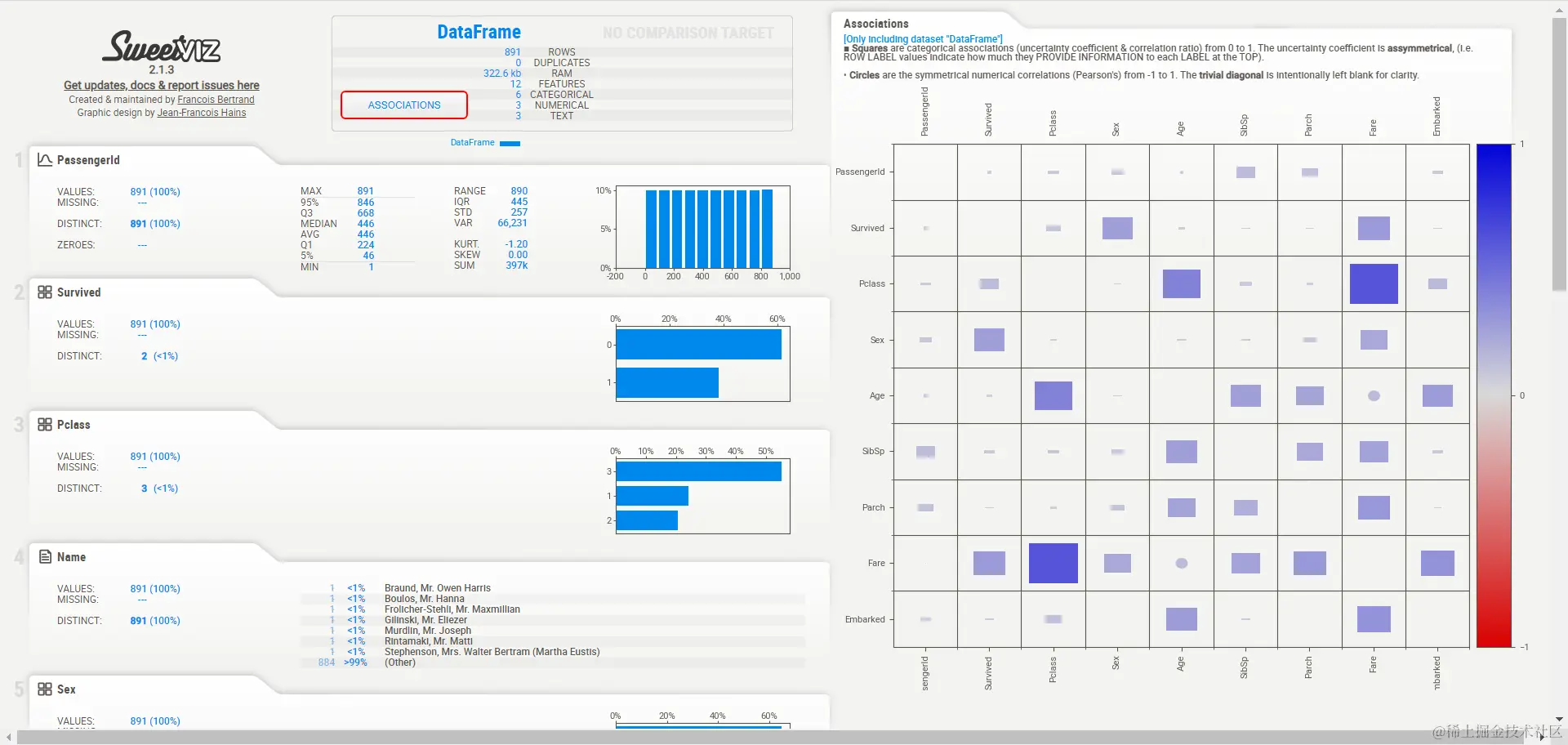
-
==Age分布情况==
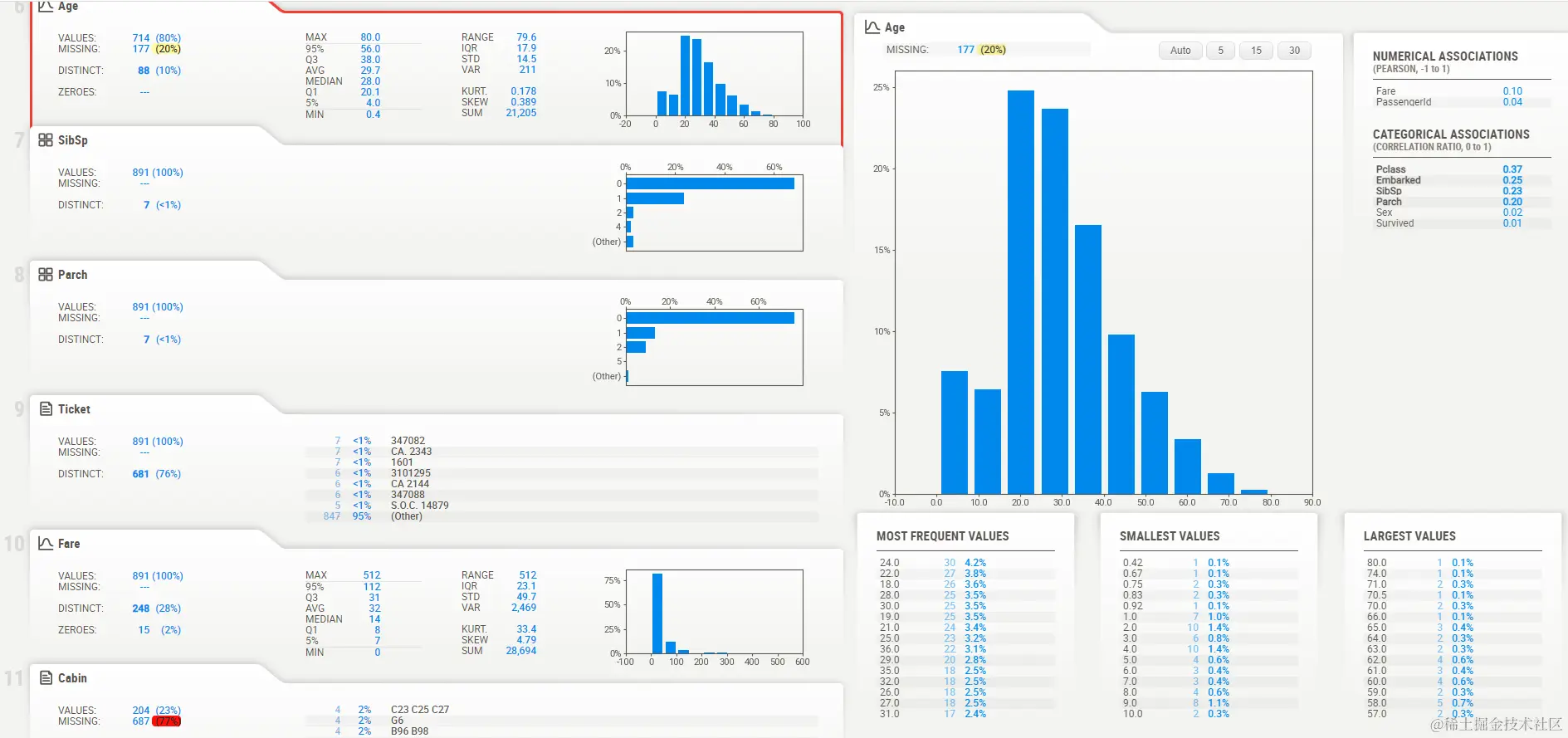
- ==sibsip分布情况==
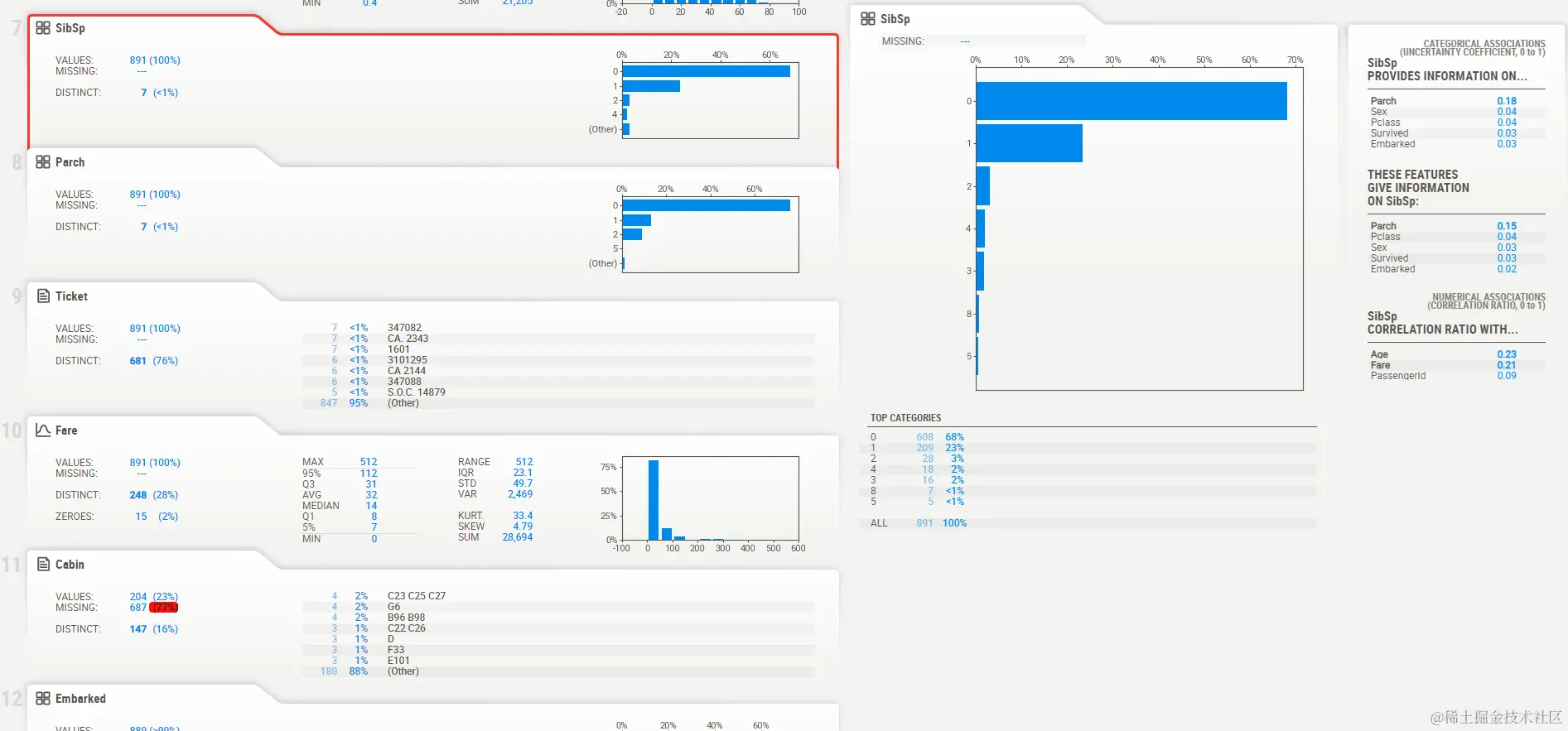
==在这个Html文件中,我们可以看到其他每个变量的分布情况,大家可以自行验证测试。==
🌹2. 比较探索性数据分析
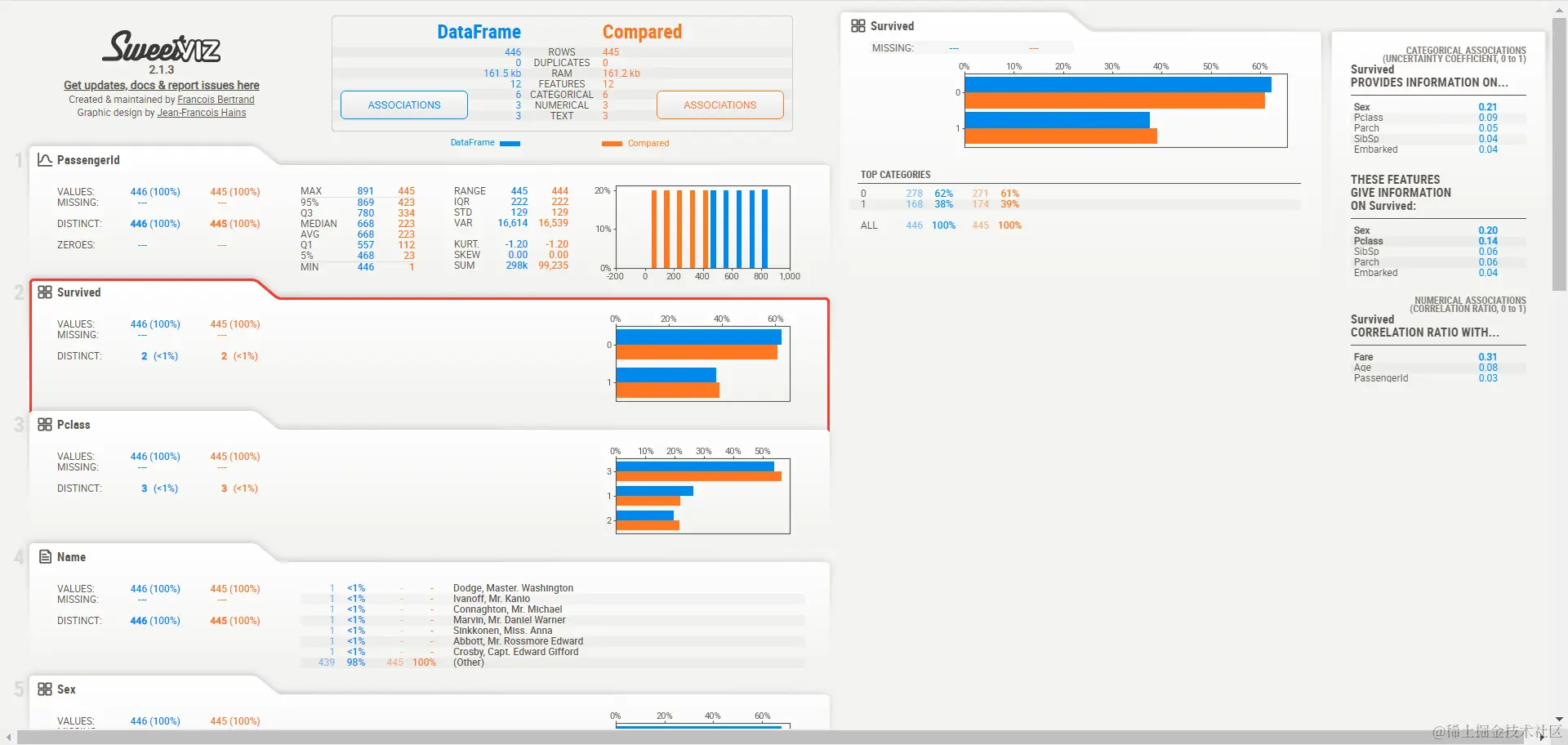
Sweetviz还支持比较不同数据集的探索性数据分析,首先,我们将数据集分成两部分,然后进行比较,然后保存此比较报告。数据集的两部分显示两种不同的颜色橙色和蓝色。具体代码和结果见下文:
df1 = sv.compare(df[445:], df[:445])
df1.show_html('Compare.html')
这里我把数据分为两部分,分别有445和446个数据。
- ==survived分布情况==
-
==Pclass分布情况==
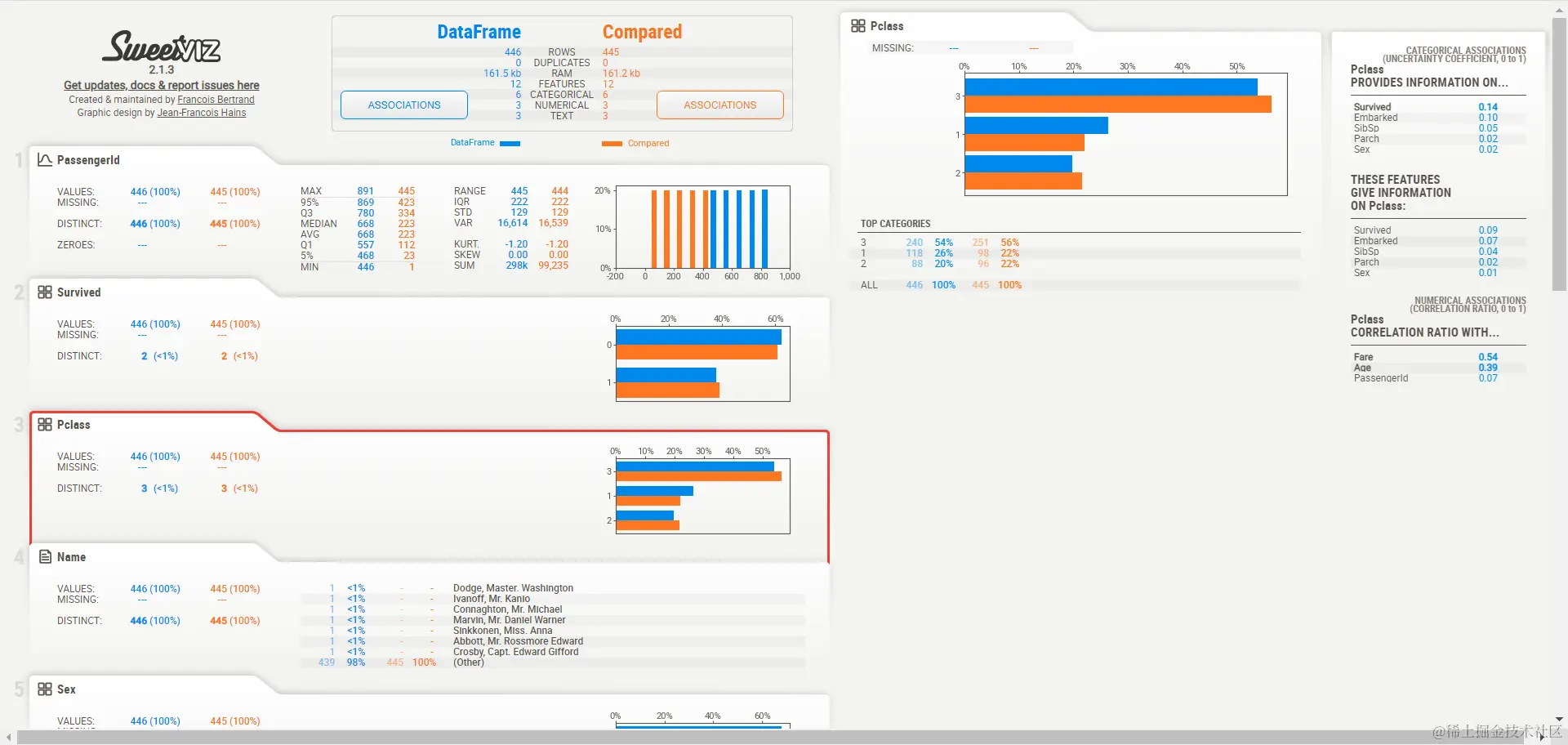
-
==sex分布情况==
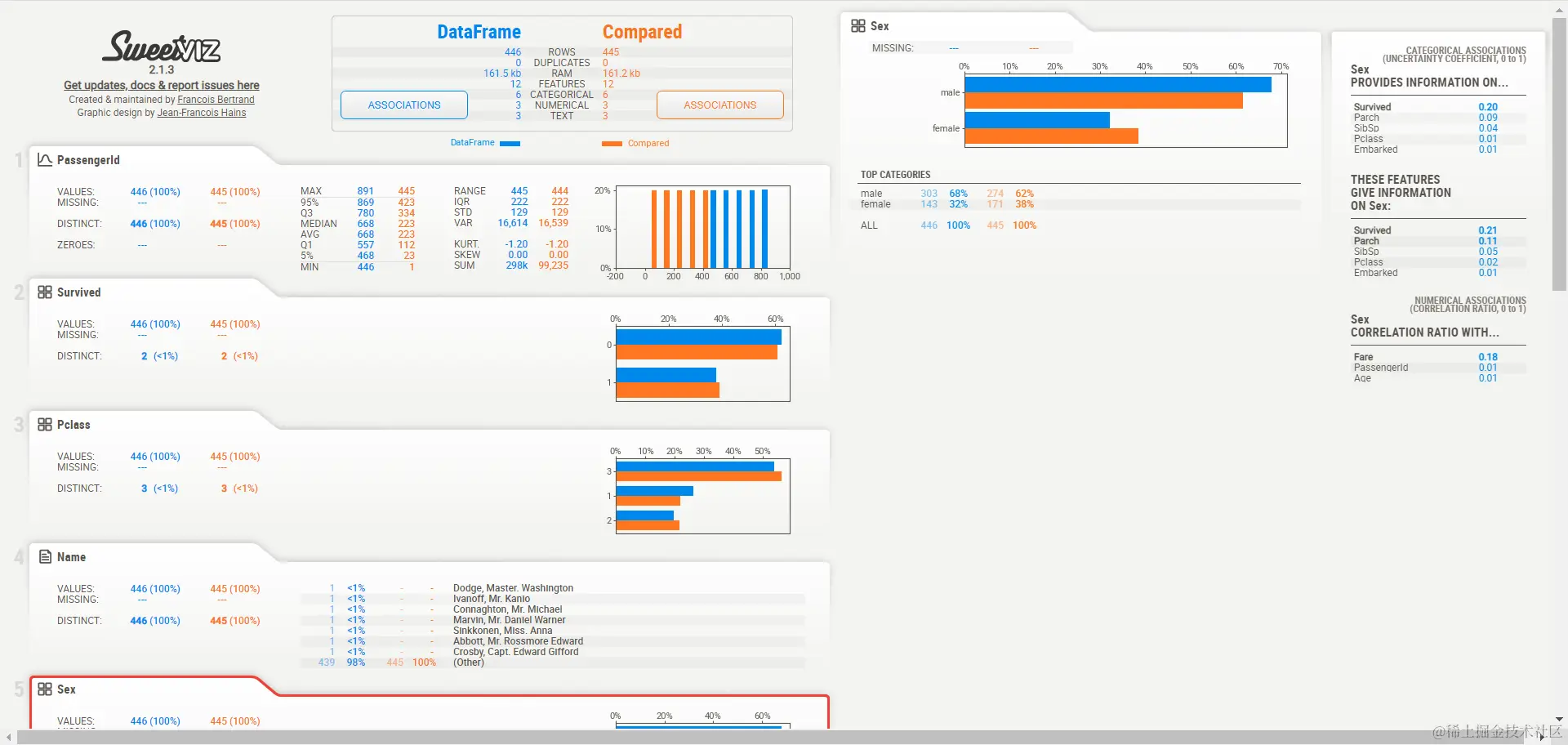
🥀3. pandas_profiling
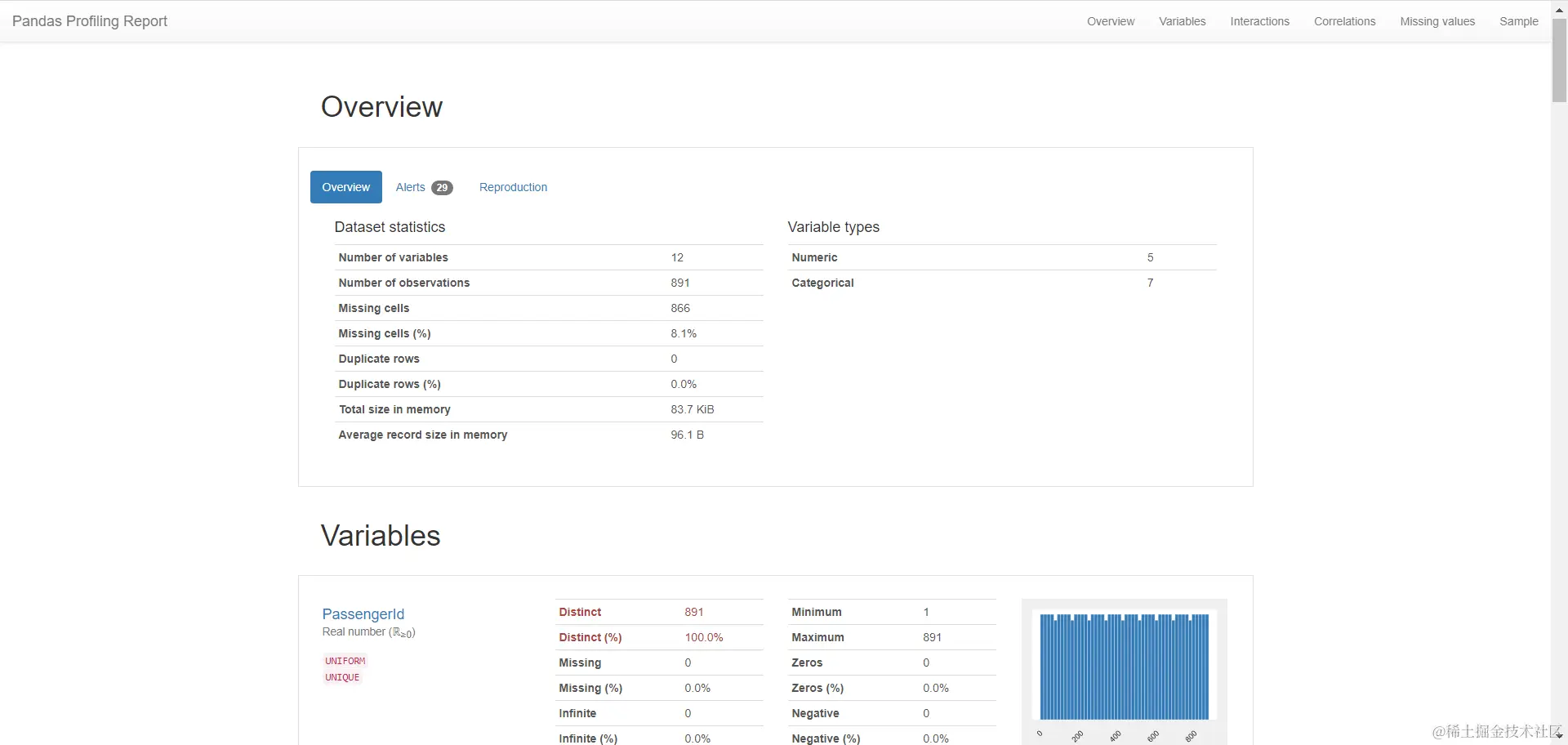
==pandas_profiling==基于pandas的DataFrame数据类型,可以简单快速地进行探索性数据分析。和sweetviz类似,pandas_profiling可以返回一个html文件,包含如下内容
- 数据整体概要:数据类型,唯一值,缺失值等
- 各个变量的描述性统计分析
- 各个变量的分布情况,直方图和条形图
- 变量间的相关系数热力图等
具体代码和结果如下:
design_report = ProfileReport(df)
design_report.to_file(output_file='report.html')
-
==变量分布情况==
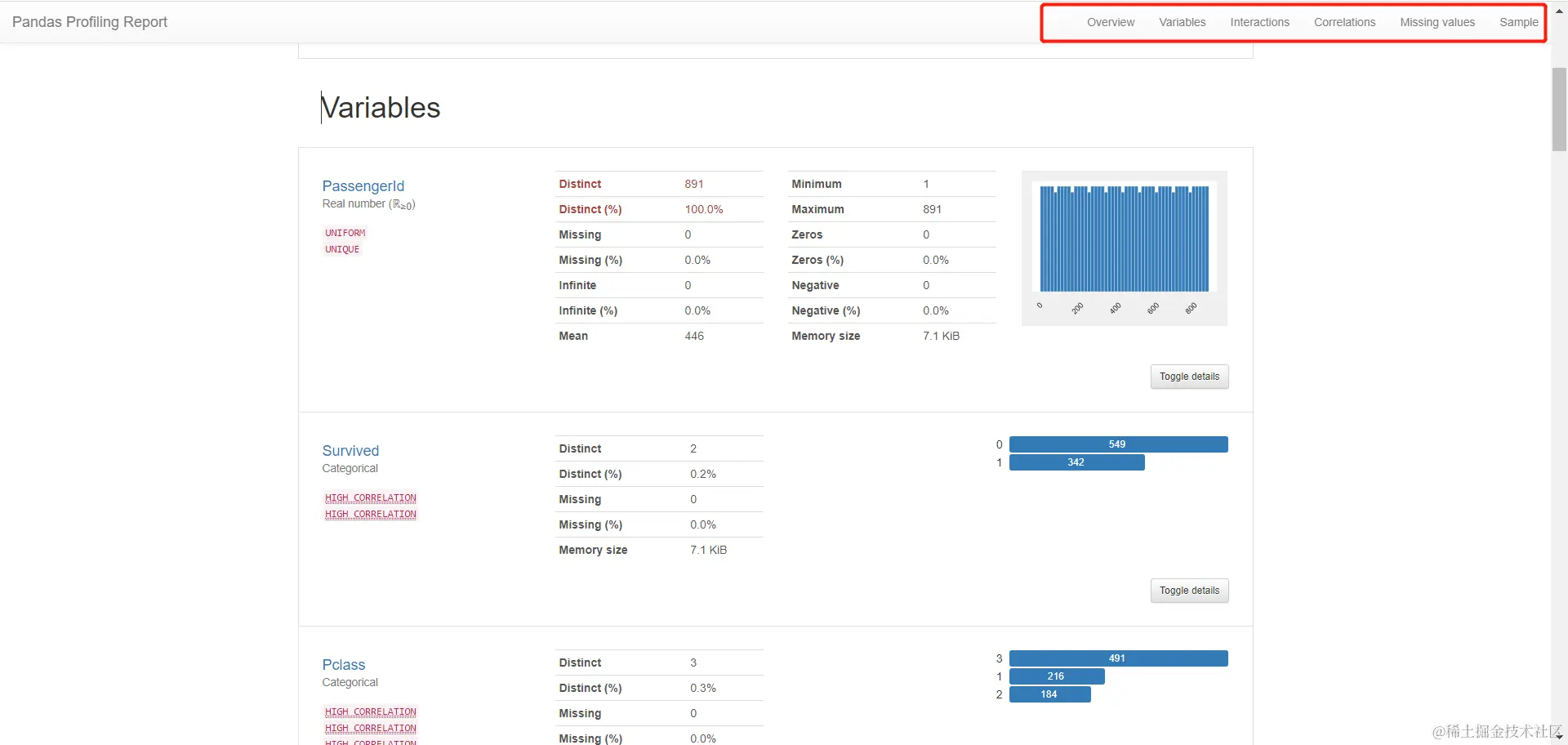
-
==相关系数热力图==
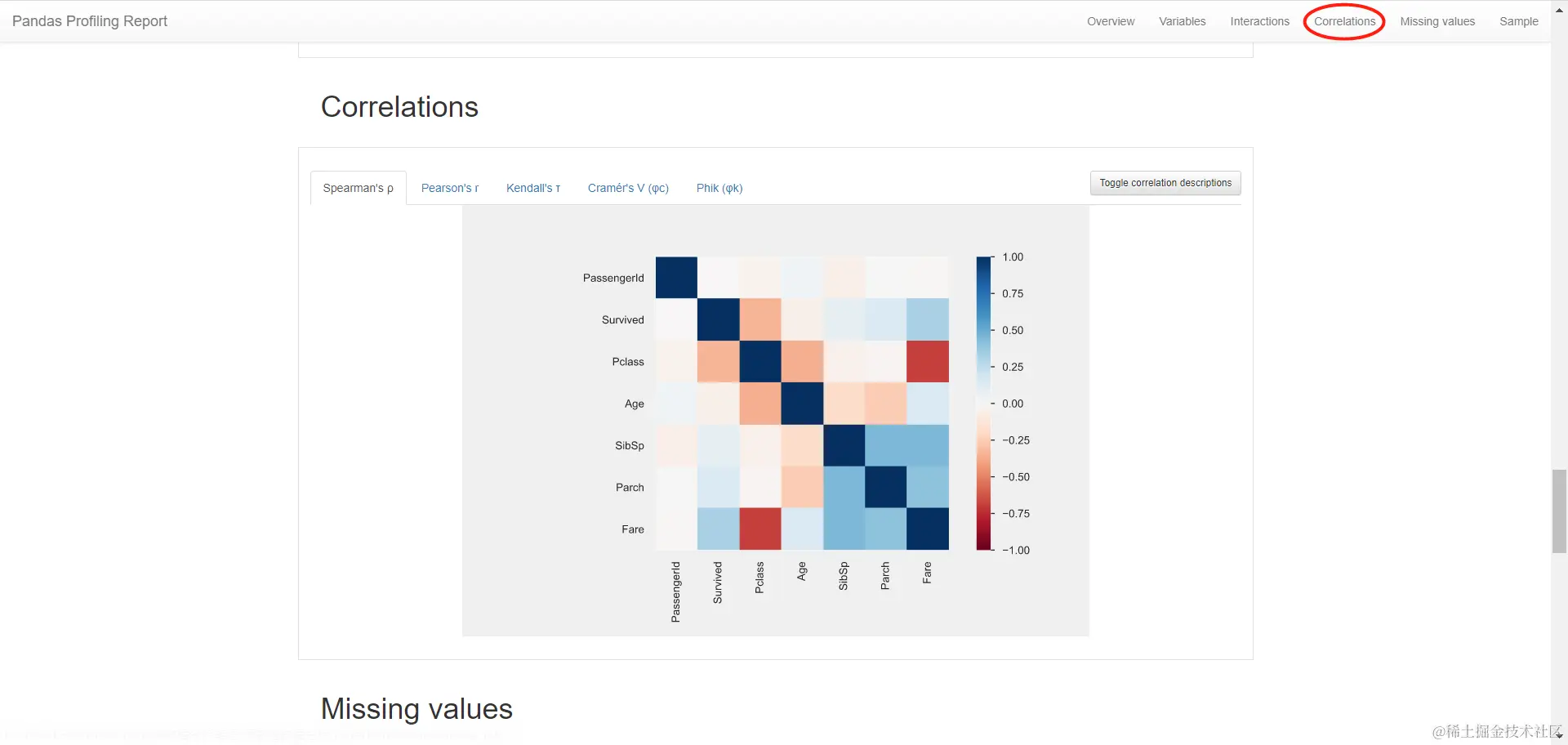
-
==变量关系图==

-
==数据总体概要==
✨总结
用上述两种方法得到的探索性数据分析是非常简易的。如果要想详细了解数据的话,建议一步一步根据自己的需求进行分析。具体可以看下面这篇推荐的文章,不过通过上述两种方法可以让我们大致初步的了解一下数据情况,并且可以节约很多时间(毕竟探索性数据分析真的很花费时间)
题外话
当下这个大数据时代不掌握一门编程语言怎么跟的上时代呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉优快云大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
👉优快云大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









