




 本文详细介绍了如何使用Python实现gRPC服务,包括初始化准备、编写gRPC服务项目、测试服务、编写API服务以及测试API服务的全过程。文章强调了 Protobuf 文件的重要性和使用gRPC框架时的注意事项,如代码生成、依赖管理和测试策略。此外,还提到了自动化代码生成工具的使用,以提高开发效率。
本文详细介绍了如何使用Python实现gRPC服务,包括初始化准备、编写gRPC服务项目、测试服务、编写API服务以及测试API服务的全过程。文章强调了 Protobuf 文件的重要性和使用gRPC框架时的注意事项,如代码生成、依赖管理和测试策略。此外,还提到了自动化代码生成工具的使用,以提高开发效率。
前言
通过前面的文章了解到了gRPC是什么,以及清楚使用它的优缺点,现在终于可以开始实现一个gRPC服务了。
这里演示的是一个用户与书互动的项目,用户可以通过该项目进行注册,登录,注销等操作,同时也可以上传,查看和评论对应的书籍,通常情况下我们会由一个简单的Web应用来提供这些服务,现在,我们假设这个服务非常庞大,需要把他们按照功能拆分成不同的微服务了,这些服务与Web应用通过gRPC进行通信。
注:由于篇幅原因,不会夹杂大量的源代码,需要跳转到
Github中查看,同时对于业务逻辑也不会详细的介绍,所以可能需要一些接口开发经验才容易阅读懂。
1.初始化准备
在创建项目之前,我们需要确定我们的需求是什么,就像开发API接口一样,先了解需求,然后多方根据需求定义好接口,最后才为每个接口编写对应的代码,在这个项目中,我假定了拆分了两个服务,一个是与用户有关, 一个是与书籍有关,书籍部分又细分为书籍管理,书籍社交两部分。为此,先编写了Protobuf文件,之前在中说过,我们创建gRPC对应的Protobuf文件应该放在一个公有的仓库中,这样就方便后续的Protobuf文件升级以及不同语言都能共享同一份Protobuf文件。
所以创建一个gRPC服务的第一步就是先创建一个包含Protobuf文件的仓库,我把它命名为grpc-example-common,具体源码可以通过获取。
这个仓库中pyproject.toml文件的tool.poetry.dependencies部分如下:
[tool.poetry.dependencies]
python = "^3.8"
grpcio = "^1.43.0"
grpcio-tools = "^1.43.0"
通过这部分文件可以知道这个项目是基于Python3.8版本的,然后用到了2个依赖分别是grpcio以及grpcio-tools,其中grpcio是Python的gRPC实现,它是通过c语言翻译的,所以很多底层都是c实现的,如果在使用gRPC框架的过程中找不到对应的使用方法说明,那可以直接到gRPC的c项目中找到对应的函数并查看它的函数说明进而了解该函数的作用;而另一个库grpcio-tools的作用是把proto文件转译为Python代码,不过单靠grpcio-tools转译的代码很难使用,比如是这段代码:
from grpc_example_common.protos.user.user_pb2 import LoginUserResult
login_user_result: LoginUserResult = LoginUserResult()
这段代码引入了由grpcio-tools通过用户Protobuf文件生成的LoginUserResult对象,开发者在后续想要使用这个对象的时候,IDE是没办法提示你这个对象有什么属性的,只能凭自己的记忆进行填写,或者回到对应的Protobuf文件查看该对象的定义:
message LoginUserResult {
string uid = 1;
string user_name = 2;
string token = 3;
}
发现它有uid,user_name,token三个属性,然后才会在代码填写LoginUserResult对象的属性进行调用:
from grpc_example_common.protos.user.user_pb2 import LoginUserResult
login_user_result: LoginUserResult = LoginUserResult(
uid="123",
user_name="so1n",
token="aaa"
)
print(login_user_result.uid)
# 123
这时即使填错了,比如uid写为uid1IDE也不会提示有错误,我们需要等到运行时报错才知道是填错了。
这样一个场景是会让开发者非常难受的,明明都定义了一个Protobuf文件,文件中已经写了这个消息有什么属性了,结果生成对应的类却无法让IDE了解它有什么属性(跳进去源码也无法知道),这时就需要通过来解决这一个问题。mypy-protobuf会生成的一份独立的.pyi文件,这样一来IDE就可以帮忙提示这个对象有什么属性了,如图: 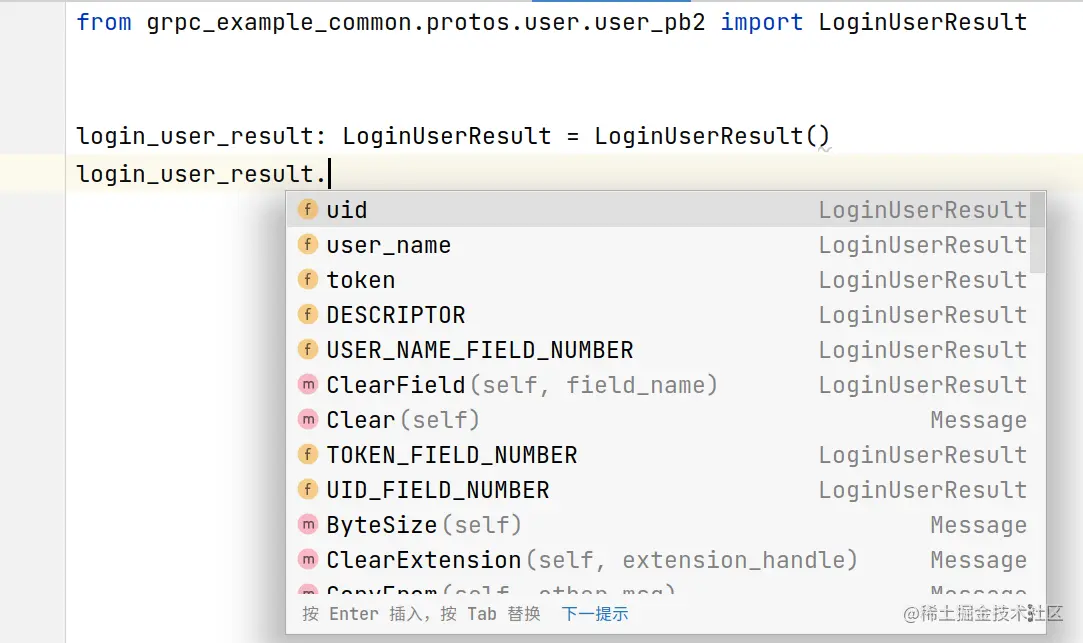 此外,通过
此外,通过.pyi文件可以使mypy等工具校验我们的代码类型是否正确,这样在运行前就能知道代码是否有问题。
mypy-protobuf的使用方法十分的简单,它以grpcio-tools的一个插件来运行,具体的使用方法如下:
# 定义生产文件的存放目录,通常都会在指定的目录下生成一个proto的文件夹
target_p = "xxx"
# 定义proto文件的目录
sourct_p = "xxx"
python -m grpc_tools.protoc \
# 指定xxx_pb2文件和xxx_pb2_grpc文件生成位置,通常我们都让他们在同一个文件夹生产
--python_out=./$target_p \
--grpc_python_out=./$target_p \
# 指定proto文件的位置
-I. \
$source_p/user/*.proto
# 上面是标准的grpcio-tools执行的标准语句
# 指定`mypy-protobuf`生成xxx_pb2和xxx_pb2_grpc对应的pyi文件的位置,必须与xxx_pb2和xxx_pb2_grpc位置保持一致
--mypy_grpc_out=./$target_p \
--mypy_out=./$target_p \
只要运行了这段命令,grpc_tools就能在对应的路径下生成Protobuf对应的代码和对应的pyi文件,不过当前的grpcio-tools默认生成的代码所在的目录名是protos,它认为这个目录是在项目对应的根目录下生成的,如果我们指定在某个子目录下生产对应的代码,那么在运行程序时会直接报错,因为生成的代码文件中有一个大概长成这样的语句:
# xxx为proto文件的名
from protos.xxx import
这意味着它永远都是从项目的根目录开始引入的protos包,但我们根目录却没有这个包,所以就会报错,这时就需要手动把生成的语句替换为:
# xxx为proto文件的名
from .xxx import
这样就可以完美运行了,但是每个文件手动改一下会非常的麻烦,因为每次生成代码后都要手动更改代码,同时由于项目存在多个Protobuf文件,每个文件都需要执行一次命令才能生成对应的代码。对于一个开发者来说,最讨厌的就是一直执行重复的工作,这种工作是非常烦心的, 所以需要编写了一个脚本来自动的把所有Protobuf文件转为Python代码(也就是项目中的gen_rpc.sh文件),该脚本如下:
# 设置脚本运行的Python环境
export VENV_PREFIX=""
if [ -d 'venv' ] ; then
export VENV_PREFIX="venv/bin/"
fi
if [ -d '.venv' ] ; then
export VENV_PREFIX=".venv/bin/"
fi
echo 'use venv path:' ${VENV_PREFIX}
# 设置生成的存放Python代码的proto文件夹的目录
target_p='grpc_example_common'
# 设置Proyobuf文件所在位置
source_p='protos'
# 设置生成protobuf代码文件的文件名
service_list=("book" "user")
# 清理之前生成的代码
rm -r "${target_p:?}/${source_p:?}"*
# 创建对应的文件夹
mkdir -p "${target_p:?}/${source_p:?}"
# 批处理
for service in "${service_list[@]}"
do
# 生成proto文件对应的Python代码逻辑,每个proto文件执行一次
mkdir -p "${target_p:?}/${source_p:?}/${service:?}"
echo "from proto file:" $source_p/"$service"/*.proto "gen proto py file to" $target_p/$source_p
${VENV_PREFIX}python -m grpc_tools.protoc \
--mypy_grpc_out=./$target_p \
--mypy_out=./$target_p \
--python_out=./$target_p \
--grpc_python_out=./$target_p \
-I. \
$source_p/"$service"/*.proto
# 创建一个__init__文件,这样一来这个文件夹就是一个包了,下面转换为from . import语句才能生效
touch $target_p/$source_p/"$service"/__init__.py
# fix grpc tools bug
sed -i "s/from protos.$service import/from . import/" $target_p/$source_p/$service/*.py
done
这样一来,我们通过Protobuf文件生成Python代码的操作就非常省心了,不管Protobuf文件有何改动,只要通过调用命令后就能在grpc_example_common.protos目录下看到已经生成的最新的Python代码,目前grpc_example_common的项目结构如下:
├── grpc_example_common # Python与gRPC相关的调用
│ ├── helper
│ ├── __init__.py
│ ├── interceptor
│ └── protos # 生成的对应Python代码
├── protos # Protobuf文件
│ ├── book
│ └── user
├──.flake8 # 格式化工具的配置
├──.pre-commit-config.yaml # 格式化工具的配置
├── gen_rpc.sh # 通过proto文件生成Python gRPC调用代码的脚本
├── mypy.ini # 格式化工具的配置
├── pyproject.toml # Python项目配置文件
├── README.md
├── requirements-dev.txt # 测试环境的依赖文件
├── requirements.txt # 正式环境的依赖文件
└── setup.py
通过项目结构可以看出还有其它的东西,这是我为了方便,我还在这个项目中添加一些Python与gRPC相关的调用封装,把它当做一个Python的自定义包。
需要注意的是,每修改一次Protobuf文件应该视为一次版本发布,当生成完Protobuf文件的对应代码后,我们需要提交代码并打上对应的tag,这样其它项目才能引用到对应的版本代码。
grpc_example_common目录下还有其它常用的封装,将会在后续章节介绍。
2.编写gRPC服务项目
目前这个演示的项目有两个子gRPC项目,他们的结构很像,所以这一节以来阐述如何创建一个gRPC服务。
该项目的代码结构如下:
├── tests # 存放测试用例
│ ├── __init__.py
│ └── test_user.py
├── user_grpc_service # 项目代码真正所在的位置
│ ├── dal # service代码,一般用于查询Mysql,Redis的逻辑
│ ├── handler # 业务逻辑代码,继承对应Protobuf文件生成的类
│ ├── helper # 其它代码封装。
│ └── __init__.py
├── app.py # 项目代码入口
├── mypy.ini # mypy配置文件
├── pyproject.toml # 项目配置文件
└── user.sql # 项目初始化SQL
首先,该项目会通过如下配置引入一些依赖:
[tool.poetry.dependencies]
python = "^3.8"
DBUtils = "^3.0.0"
PyMySQL = "^1.0.2"
c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1912
1912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









