




前言
今天给大家介绍的是Python爬取Top100电影榜单数据保存csv文件,在这里给需要的小伙伴们帮助,并且给出一点小心得。

开发工具
Python版本: 3.6
相关模块:
requests模块
time模块
parsel模块
csv模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
文中完整代码及文件,评论留言获取
思路分析
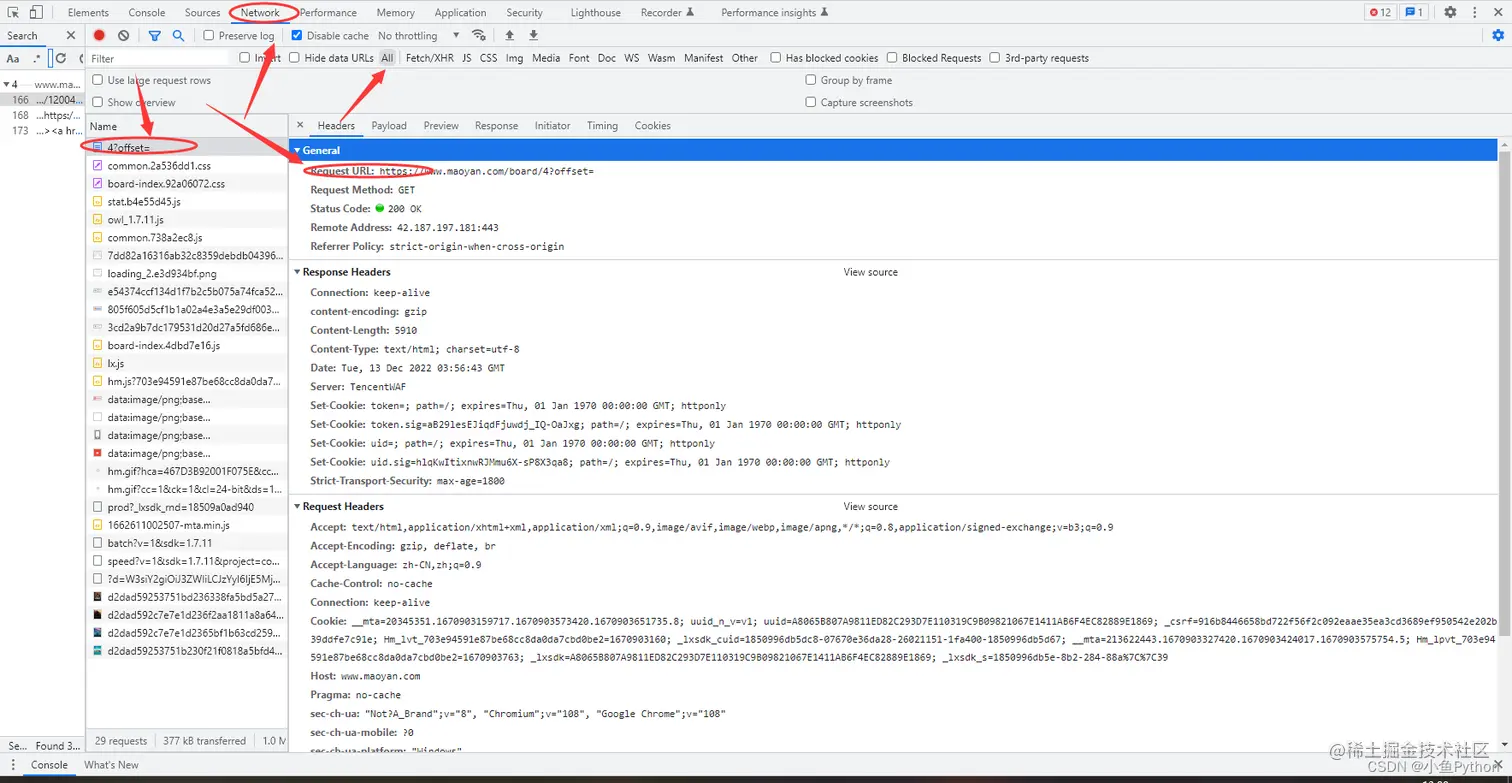
浏览器中打开我们要爬取的页面 按F12进入开发者工具,查看我们想要的Top100电影榜单数据在哪里 这里我们需要页面数据就可以了
代码实现
for page in range(0, 101, 10):
time.sleep(2)
url = 'https://maoyan.com/board/4?offset={}'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









