



 Scrapy是一个Python开源爬虫框架,用于高效抓取网页并提取结构化数据。其基本原理是通过发送HTTP请求获取内容,使用Xpath或CSS选择器解析。框架核心组件包括引擎、调度器、下载器、爬虫和管道,以及下载和Spider中间件。Scrapy的工作流程涉及请求对象的调度、下载、解析、数据存储等步骤。该框架具有高度可扩展性和灵活性,支持异步IO和分布式爬虫。
Scrapy是一个Python开源爬虫框架,用于高效抓取网页并提取结构化数据。其基本原理是通过发送HTTP请求获取内容,使用Xpath或CSS选择器解析。框架核心组件包括引擎、调度器、下载器、爬虫和管道,以及下载和Spider中间件。Scrapy的工作流程涉及请求对象的调度、下载、解析、数据存储等步骤。该框架具有高度可扩展性和灵活性,支持异步IO和分布式爬虫。

**1、**Scrapy框架的介绍
Scrapy是一个基于Python的开源网络爬虫框架,是一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。它可以帮助开发者快速、高效地从网站上获取数据。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。
尽管Scrapy原本是设计用来屏幕抓取(更精确的说,是网络抓取),但它也可以用来访问API来提取数据。
2、Scrapy框架的基本原理
Scrapy框架的基本原理是通过发送HTTP请求获取网页内容,然后使用Xpath或CSS选择器等工具解析网页内容,最后新数据存储到数据库或文件中。
3、爬虫框架scrapy架构
scrapy框架的核心组件由五大组件引擎、调度器、下载器、爬虫、管道和中间件组成。
五大组件是调度器(Scheduler),下载器(Downloader),爬虫(Spider),实体管道(Item Pipeline),Scrapy引擎(Scrapy Fngine)。
3.1 Scrapy架构图
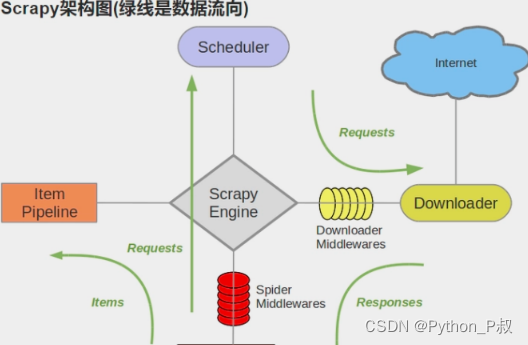
3.2 Scrapy五大组件及中间件
**(1)Scrapy Engine(引擎):**是整个框架的核心,它负责控制整个爬虫的流程,包括Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
**(2)Scheduler(调度器):**负责管理待爬取的URL队列,它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
**(3)Downloader(下载器):**下载器负责发送HTTP请求并获取网页内容,负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
**(4)Spider(爬虫):**负责解析网页内容并提取数据,它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
**(5)Item Pipeline(管道):**负责将爬取到的数据存储到数据库或文件中,处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
**(6)Downloader Middlewares(下载中间件):**一个可以自定义扩展下载功能的组件。
**(7)Spider Middlewares(Spider中间件):**一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
3.3 Scrapy工作流程
(1)spider中的url被封装成请求对象交给引擎(每一个对应一个请求对象)。
(2)引擎拿到请求对象之后,将全部交给调度器。
(3)调度器拿到所有请求对象后,通过内部的过滤器过滤掉重复的url,最后将去重后的所有url对应的请求对象压入到队列中,随后调度器调度出其中一个请求对象,并将其交给引擎。
(4)引擎将调度器调度出的请求对象交给下载器。
(5)下载器拿到该请求对象去互联网中下载数据。
(6)数据下载成功后会被封装到response中,随后response会被交给下载器。
(7)下载器将response交给引擎。
(8)引擎将response交给spiders。
(9)spiders拿到response后调用回调方法进行数据解析,解析成功后生成item,随后spiders将item交给引擎。
(10)引擎将item交给管道,管道拿到item后进行数据的持久化存储。
3.4 Scrapy框架的优点
Scrapy框架的优点在于它具有高度的可扩展性和灵活性。开发者可以根据自己的需求自定义爬虫、管道和中间件等组件,以满足不同的爬虫需求。此外,Scrapy框架还支持异步IO和分布式爬虫等功能,可能提高爬虫的效率和稳定性。
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉优快云大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板



















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









