




Scrapy爬虫框架
1 工作流程

Scrapy Engine(引擎):负责各个组件之间通讯以及数据传递等
Scheduler(调度器):接收引擎传递过来的requests请求,按照一定的规则进行整理排列,当调度器需要使用到请求的时候,调度器会将请求还给引擎
Downloader(下载器):负责连接网络,根据传递过来的请求,发送所有的requests请求,将获取到的response交给引擎,再由引擎交给spiders进行下一轮处理
Spiders(爬虫):负责处理传递过来的response,先分析提取所需要的数据,如果有必要,会将下一步需要访问的URL传递给引擎,如果抛出item,获取到item,获取到items传递给管道
Item Pipeline(管道):负责将spider抛出的items进行后期的处理(需要分析,过滤,存储等)
2 创建scrapy项目
首先需要将scrapy进行安装
pip install scrapy
在anaconda可以进行项目的创建
cd到指定路径后,输入
scrapy startproject mySpider
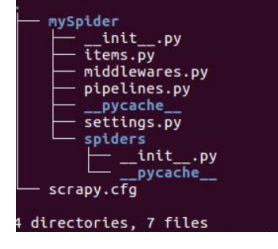
cd到mySpider文件下,可以查看该目录下的文件
tree
3 步骤
第一步:新建一个爬虫项目
第二步:在items.py文件里面,明确你需要的抓取目标
第三步:在spiders文件夹里面,创建py文件,用来创建新爬虫项目
scrapy genspider 项目名 "网址"
第四步:根据所需要的存储方式,在pipelines.py文件里面,进行items的存储
步:根据所需要的存储方式,在pipelines.py文件里面,进行items的存储

















 3989
3989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









