




 本文深入探讨了SparkStreaming这一实时大数据计算框架,它是基于SparkCore的内存计算模型,通过DStream概念封装,实现对大数据流的高效处理。文章强调了RDD作为Spark技术生态的核心,并指出掌握SparkCore对于使用SparkSQL和SparkStreaming至关重要。
本文深入探讨了SparkStreaming这一实时大数据计算框架,它是基于SparkCore的内存计算模型,通过DStream概念封装,实现对大数据流的高效处理。文章强调了RDD作为Spark技术生态的核心,并指出掌握SparkCore对于使用SparkSQL和SparkStreaming至关重要。
Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架。它的底层,其实,也是基于我们之前讲解的Spark Core的。基本的计算模型,还是基于内存的大数据实时计算模型。而且,它的底层的组件或者叫做概念,其实还是最核心的RDD。
只不过,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStream。之前的Spark SQL,它针对数据查询这种应用,提供了一种基于RDD之上的全新概念DataFrame,但是其底层还是基于RDD的。所以,RDD是整个Spark技术生态中的核心。要学好Spark在交互式查询(SparkSQL)、实时计算上(SparkStreaming)的应用技术和框架,必须掌握Spark核心编程,也就是Spark Core。
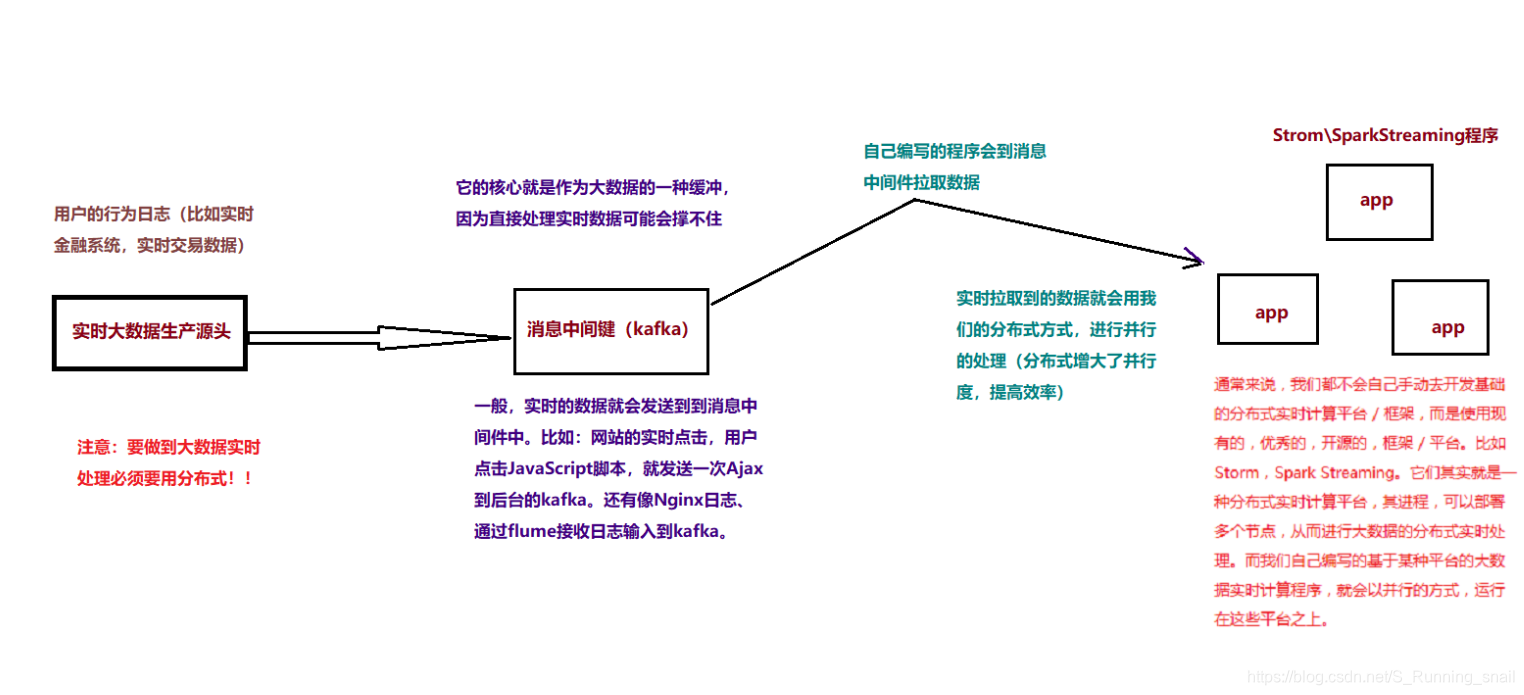
大数据实时计算原理

















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









