



 通过Python实现AlphaZero框架,涵盖抽象游戏规则、模型类、蒙特卡洛树等关键组件,成功应用于五子棋、四子棋及翻转棋AI,并在Unity中实现人机对战。
通过Python实现AlphaZero框架,涵盖抽象游戏规则、模型类、蒙特卡洛树等关键组件,成功应用于五子棋、四子棋及翻转棋AI,并在Unity中实现人机对战。
著名的围棋人工智能AlphaGo有多个版本。其中AlphaGo Zero纯靠增强学习算法击败了AlphaGo所有其它版本,其由论文Mastering the game of Go without human knowledge介绍。后来将这种纯增强学习算法推广,论文Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm提出的AlphaZero的概念,任何类似的博弈游戏都可以使用AlphaZero算法实现其人工智能。
我使用Python,实现了一个简单的AlphaZero框架,包括如下内容:
1.抽象的游戏规则:定义了一套游戏规则接口。
2.抽象的模型类:定义了模型的接口,包括神经网络的定义,保存读取,训练方法等。
3.蒙特卡洛树:实现了一个蒙特卡洛树及其搜索算法。
4.训练类:对AlphaZero增强学习算法过程的实现,其程序流程如图所示。
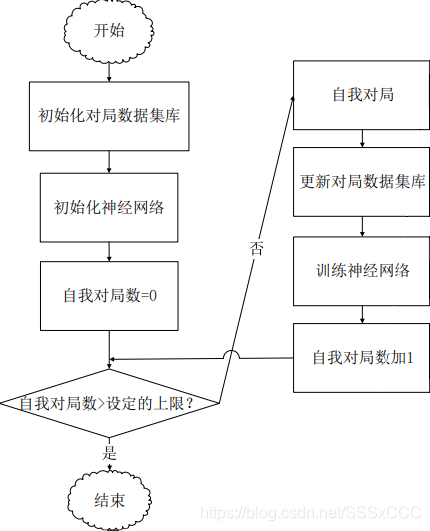
5.工具类:模型的打包,训练过程作图等方法。
我使用这个AlphaZero框架实现了五子棋AI,四子棋AI,翻转棋AI。并使用Unity实现了人和这些AI对战的小游戏,效果如下:


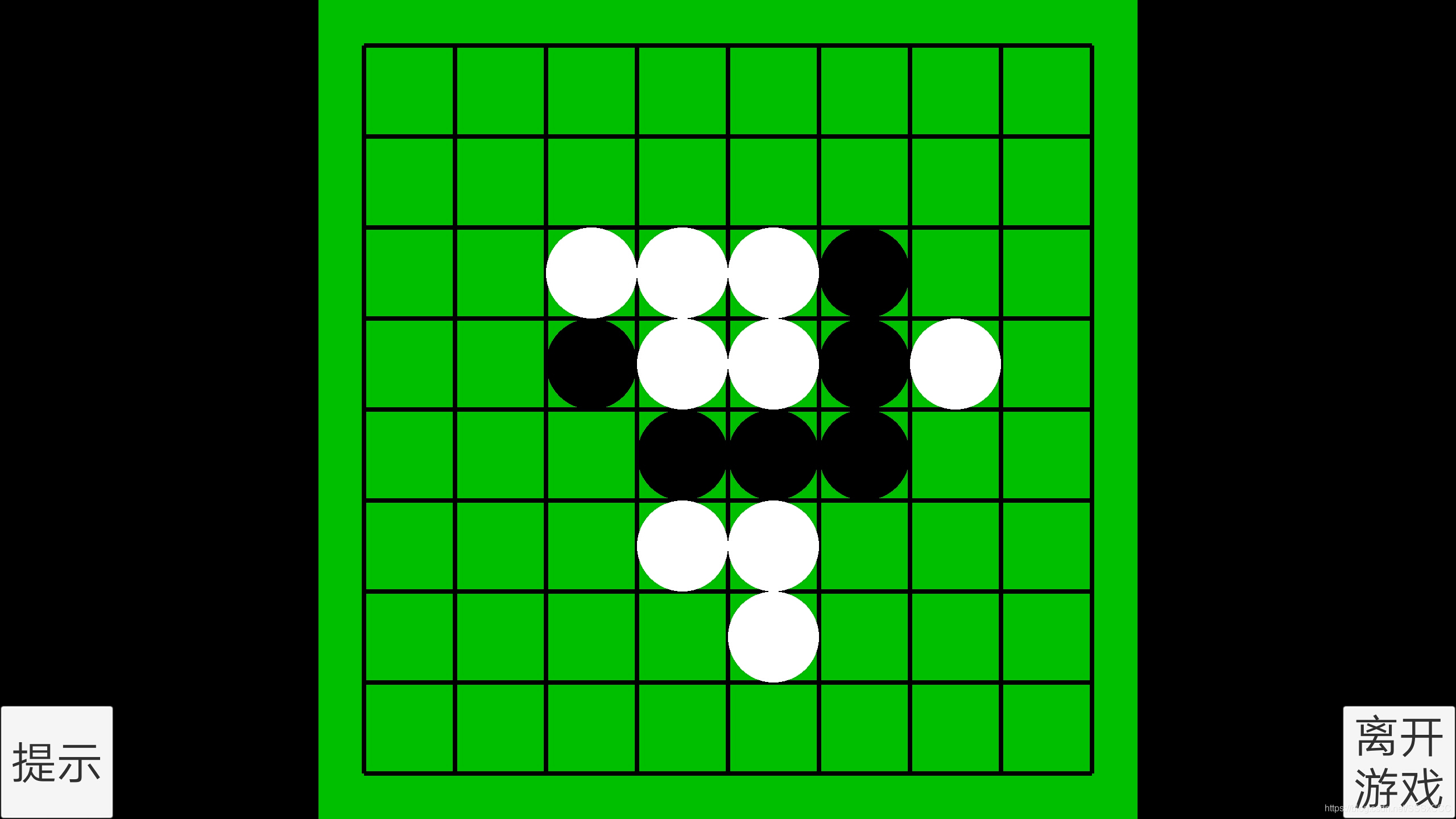

源代码及相应的介绍论文在此:https://github.com/SSSxCCC/AlphaZero-In-Unity



















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











