




 本文围绕Linux系统下的MySQL展开,介绍了仓库、本地、容器三种安装方式,阐述了其体系结构,包含连接层、SQL层等。详细讲解库表操作、DML数据操纵语言,如插入、查询等语句。还给出常见面试题解答,如InnoDB与MyISAM区别、count函数差异等。
本文围绕Linux系统下的MySQL展开,介绍了仓库、本地、容器三种安装方式,阐述了其体系结构,包含连接层、SQL层等。详细讲解库表操作、DML数据操纵语言,如插入、查询等语句。还给出常见面试题解答,如InnoDB与MyISAM区别、count函数差异等。
目录
1、为什么InnoDB的批量插入速度相较于MyISAM和Memory来说会低呢?
count(*)和count(1)和count(列名)的区别
MySQL安装(Linux)
1、仓库安装
cd /etc/yum.repos.d
vim mysql-community.repo
[mysql80-community] name=MySQL 8.0 Community Server
baseurl=Index of /232905/yum/mysql-8.0-community/el/8$basearch/
enabled=1
gpgcheck=0
保存并退出
执行 yum makecache去制作缓存
安装:yum install mysql-community-server -y
启动服务:systemctl restart mysqld
访问:获取临时生成密码 grep 'temporary password' /var/log/mysqld.log # 去找密码
登录:mysql -uroot -p
2、本地安装
获取安装包:wget https://repo.mysql.com//mysql80-community-release-el9-5.noarch.rpm
安装:yum install mysql80-community-release-el9-5.noarch.rpm
安装之后会在/etc/yum.repo.d/下产生三个文件
->mysql-community-debuginfo.repo
->mysql-community.repo
->mysql-community-source.repo
然后yum makecache制作缓存
yum install mysql-community-server -y
重启 systemctl restart mysqld.server
访问:获取临时生成密码 grep 'temporary password' /var/log/mysqld.log # 去找密码
登录:mysql -uroot -p
3、容器安装
cd /etc/yum.repo.d/
获取dockerrepo包:wget https://download.docker.com/linux/centos/docker-ce.repo
制作高速缓存:yum makecache
安装docker:yum install docker-ce -y
重启docker服务:systemctl restart docker
创建一个docker数据库:
docker run --name mysql1 -e MYSQL_ROOT_PASSWORD=123456 mysql
#后台运行
#run == create && create; -e 指变量;
#最后一个mysql是要用的mysql镜像,第一次使用需要拉取镜像
docker ps #查看正在运行的容器
进入容器:docker exec -it mysql1 /bin/bash
在容器中登录mysql:mysql -uroot -p
密码:123456
MySQL体系结构
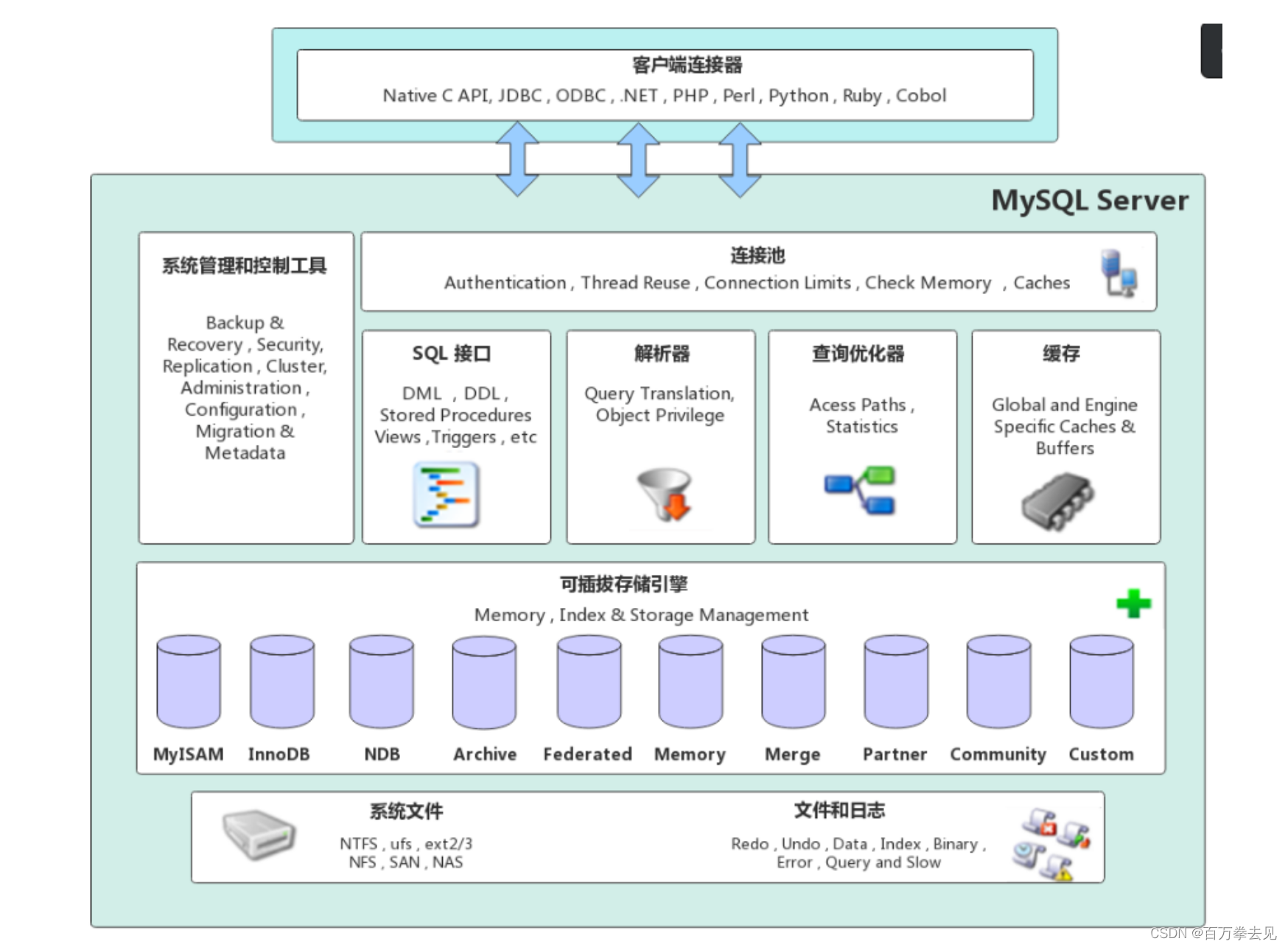
由图可见:MySQL体系结构有上层客户端和下层服务器,下层服务器由连接层、Server层、存储引擎层,系统文件构成
- 用户:连接使用数据库的人
- 客户端连接器:即一个接口,是第三方语言支持提供与数据库连接的接口,常见的有jdbc,obdc,c的标准api函数等
连接层
连接层:提供与用户的连接服务,用于验证登录服务
连接池:管理、缓冲用户的连接,接受客户端的连接,线程处理等需要缓存的需求;连接池的作用就是创建多条连接,当用户需要连接时,分配给用户一条连接,当用户不用时,收回连接,连接复用,提高连接速率,提升服务器性能
SQL层
SQL层:完成大多数的核心服务功能。
系统管理和控制工具:Backup&Recovery(备份和恢复)、Security(安全)、Replication(复制)、Cluster(集群)、Adminstration(管理员)、Configuration(配置)、Migration(迁移)、Metedate(元数据)
sql接口:接受用户的sql命令,并返回用户的需要的查询结果
解析器:主要是将输入sql指令分解为语法单元,先后经过词法分析、语法分析、语义分析,将这些语法单元转换为内部表示的数据结构,最终生成一个可以执行的查询文件。
优化器:会将sql语句在查询之前使用优化查询器对该查询进行优化
存储器:查询缓存,如果查询缓存命中了,查询语句则可直接去缓存中取数据
存储引擎层
真正的负责MySQL数据的存储和提取,服务器通过API和存储引擎进行通信,不同的存储引擎功能不同,这样可以根据不同的需求选取合适的存储系统。存储系统是可插拔式的,可以扩展。索引是在存储系统实现的,不同的存储系统索引结果是不同的。MyISAM是MySQL5.5之前的默认存储引擎,InnoDB是MySQL5.5之后的默认存储引擎
MySQL存储引擎的介绍
对于MySQL而言,数据是存储在文件系统上的,不同的存储引擎会有不同的文件格式和组织形式
MySQL存储引擎的概念
- Mysql数据库使用不同的机制存储表文件,机制的差别在于不同的存储方式,索引技巧,锁定水平以及广泛的不同的功能和能力,在MySQL中,将这些不同的技术及配套的功能称为存储引擎
- 存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方法
- 存储引擎是基于表的,而不是基于库的,所以存储引擎也被称为表类型
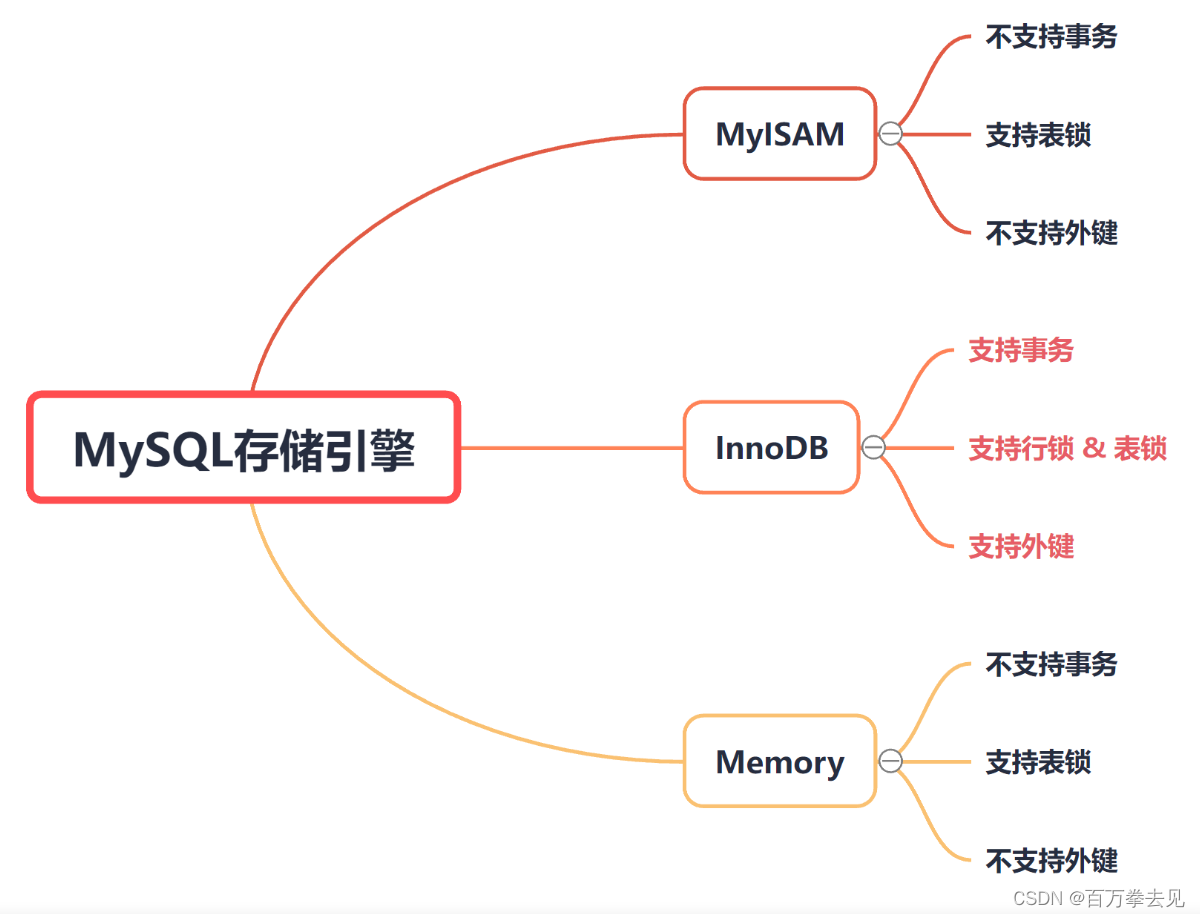
MySQL支持的比较常用的存储引擎:InnoDB、MyISAM、Memory
常用存储引擎的特性比对
常用存储引擎特性比对 特性 MyISAM InnoDB(重点) Memory 存储限制 有(平台对文件系统大小的限制) 64TB 有(平台的内存限制) 事务安全 不支持 支持 不支持 锁机制 表锁 表锁/行锁 表锁 B+Tree索引 支持 支持 支持 哈希索引 不支持 不支持 支持 全文索引 支持 支持 不支持 集群索引 不支持 支持 不支持 数据索引 不支持 支持 支持 数据缓存 不支持 支持 N/A 索引缓存 支持 支持 N/A 数据可压缩 支持 不支持 不支持 空间使用 低 高 N/A 内存使用 低 高 中等 批量插入速度 高 低 高 外键 不支持 支持 不支持
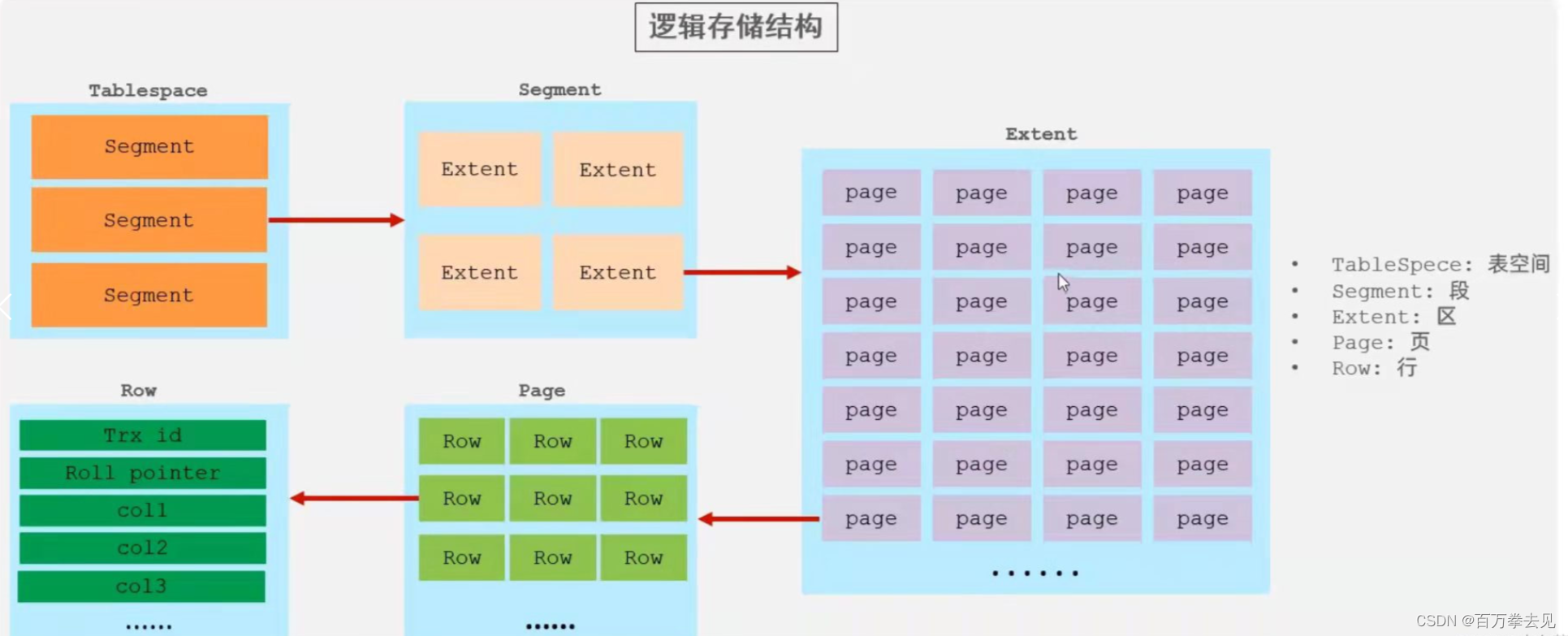
InnoDB的逻辑存储结构
即.ibd文件内部的磁盘存储结构
- Tablespace表空间:表空间时InnoDB存储引擎逻辑结构的最高层,.ibd文件其实就是表空间文件,在表空间中可以包含多个Segment段。对于InnoDB而言,数据时存储在表空间当中的,表空间时InnoDB抽象出来的一个概念,它对应着磁盘上的一个或多个文件!MyISAM没有表空间的概念!
- Sgement:表空间是由段组成的,常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段包含256哥区(256M大小)
- Extent区:区是表空间的单元结构,每个区的大小为1M。默认情况下,InnoDB存储引擎页大小为16K,即一个区中一共有64个连续的页
- Page页:页是组成区的最小单元,页也是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎每次从磁盘申请4-5个区。连续的64个Page页就是一个Extent区
- Row行:InnoDB存储引擎是面向行的,也就是说数据是按行进行存放的,行当中存放的就是一个一个的字段值。
系统文件层
主要将数据存储在文件系统上,并完成与存储引擎的交互,存储具体的数据,包含一系列的日志、数据、索引等
MySQL库表操作
库操作
如何查看当前数据库:select database();
如何创建数据库: create database 数据库名如何删除数据库:drop database [if exists] 数据库名
如何切换数据库:use 数据库名;
创建数据库时可指定字符集和校验规则:create database 数据库名 character set 字符集 collate 校验规则
如何修改数据库的字符集和校验规则:alter database mydb2 character set utf8mb4 collate utf8mb4_0900_ai_ci;
如何展示所有数据库:show databases;
如何查看当前数据库版本:select version();
如何查看当前用户:select user();
如何查看字符集:show variables like '%character%';
如何查看校对规则:show collation;collation中: ci:忽略大小写 cs:不忽略大小写 bin:二进制
表操作
创建表
(指定有哪些列及其类型)
在表这个级别设置存储引擎,默认的存储引擎:InnoDB
也可以指定字符集:默认使用数据库的字符集
例:create table stu_info(id int,name varchar(30)engine=InnoDB;查看表
如何查看数据库中有多少表:show tables;
如何查看表的结构:desc 表名;show columns from 表名;
如何查看创建表的语句:show create table 表名;删除表
如何删除一个表:drop table 表名;
修改表结构
修改列类型:alter table 表名 modify 列名 列类型
增加列:alter table 表名 add 列名 列属性
删除列:alter table 表名 drop 列名
列改名:alter table 表名 change 旧列名 新列名 列属性
表改名:alter table 表名 to 新表名复制表结构
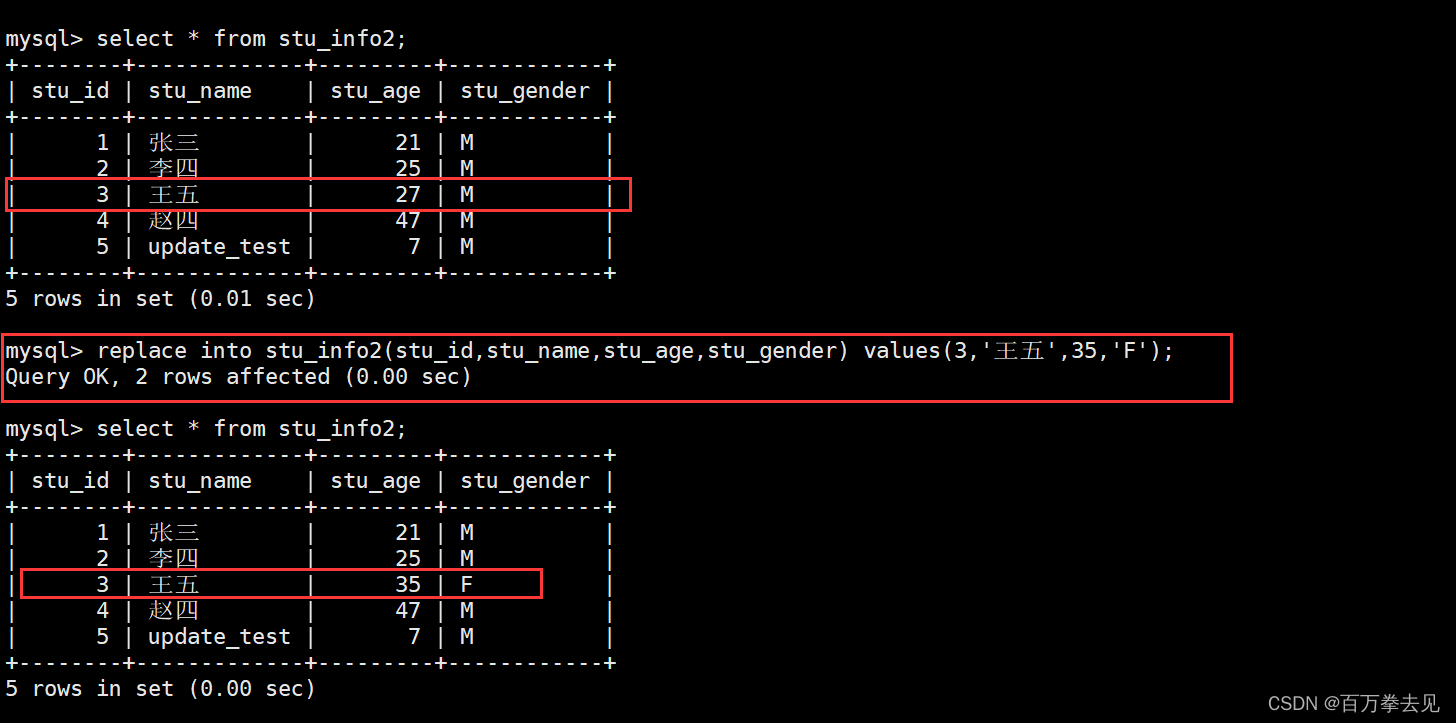
如何复制一个表的结构不复刻数据:create table stu_info2 like stu_info; #表stu_info2复制表stu_info的结构
如何复制一个表的结构连带复刻数据:create table stu_info3 like stu_info;#表stu_info3获得表stu_info的结构和数据
如何给stu_info2中插入stu_info的数据(stu_info和stu_info2结构一致):insert into stu_info2 select * from stu_info
表的约束
NOT NULL 非空
UNIQUE KEY 唯一键:可以为空
PRIMARY KEY 主键: 唯一标识,不可以为空
FOREIGN KEY 外键:
CHECK检查
DEFAULT默认值成员运算符:in/not in
身份运算符:is/is not创建表时创建约束
CREATE TABLE
stu_info(
stu_idint NOT NULL AUTO_INCREMENT COMMENT '学号',
stu_namevarchar(30) NOT NULL COMMENT '姓名',
stu_agetinyint NOT NULL COMMENT '年龄',
stu_genderchar(1) NOT NULL DEFAULT 'M' COMMENT '性别',
stu_addrvarchar(200) NOT NULL COMMENT '地址',
stu_classint NOT NULL, PRIMARY KEY (stu_id),
UNIQUE KEYstu_addr_u(stu_addr),
KEYstu_class_id_fk(stu_class),
CONSTRAINTstu_class_id_fkFOREIGN KEY (stu_class) REFERENCESclass(class_id),
CONSTRAINTstu_chk_1CHECK ((stu_age>= 18)),
CONSTRAINTstu_chk_2CHECK ((stu_genderin (gbk'M',gbk'F')))) ENGINE=InnoDB AUTO_INCREMENT=10009 DEFAULT CHARSET=gbk
设置地址或外键失败,auto_increment仍会自增
创建表后添加约束
CREATE TABLE
stu_info3(
stu_idint DEFAULT NULL,
stu_namevarchar(30) DEFAULT NULL,
stu_agetinyint DEFAULT NULL,
stu_genderchar(1) DEFAULT NULL,
stu_addrvarchar(200) DEFAULT NULL,
stu_classint DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gbk如何将stu_id设为主键:alter table stu_info3 add constraint primary key(stu_id);
如何将stu_name设为不为空:alter table stu_info3 modify stu_name varchar(30) not null;
如何将给age一个检查:alter table stu_info3 add constraint check (age >= 0 && age <130); 如何给gender赋约束:alter table stu_info3 modify stu_gender char(1) default 'M'; alter table stu_info3 add constraint check (stu_gender in ('M','F'));
如何给stu_gender赋unique约束:alter table stu_info3 add constraint unique key(stu_addr); 如何给stu_class赋外键约束:alter table stu_info3 add constraint foreign key(stu_class) references class(class_id);
如何给stu_age设置默认自增值:alter table stu_info3 modify stu_id int auto_increment ; alter table stu_info3 auto_increment = 10001;如何给表将约束去除
CREATE TABLE
stu_info(
stu_idint NOT NULL AUTO_INCREMENT COMMENT '学号',
stu_namevarchar(30) NOT NULL COMMENT '姓名',
stu_agetinyint NOT NULL COMMENT '年龄',
stu_genderchar(1) NOT NULL DEFAULT 'M' COMMENT '性别',
stu_addrvarchar(200) NOT NULL COMMENT '地址',
stu_classint NOT NULL, PRIMARY KEY (stu_id),
UNIQUE KEYstu_addr_u(stu_addr),
KEYstu_class_id_fk(stu_class),
CONSTRAINTstu_class_id_fkFOREIGN KEY (stu_class) REFERENCESclass(class_id),
CONSTRAINTstu_chk_1CHECK ((stu_age>= 18)),
CONSTRAINTstu_chk_2CHECK ((stu_genderin (gbk'M',gbk'F')))
) ENGINE=InnoDB DEFAULT CHARSET=gbk如何删除主键约束(若主键有自增则不能删除,要删除主键第一步要移除自增)
如何移除自增:alter table stu_info modify stu_id int comment '学号';
接着移除主键约束:alter table stu_info drop primary key;
如何移除not null约束:alter table stu_info modify stu_name varchar(30) comment '姓名';
如何移除check约束:alter table stu_info drop check stu_chk_1;
如何移除default约束:alter table stu_info modify stu_gender char(1) comment '性别';
如何移除外键约束:alter table stu_info drop constraint stu_class_id_fk;
alter table stu_info drop key stu_info_class_id_fk;
如何移除unique约束:alter table stu_info drop key stu_addr_u;修改mysql密码策略
临时修改
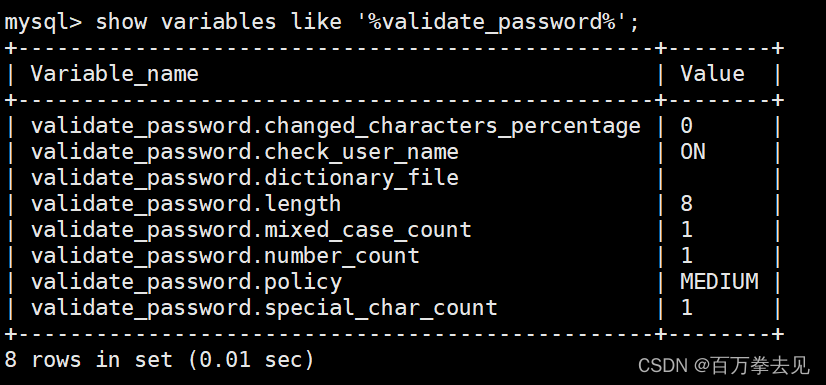
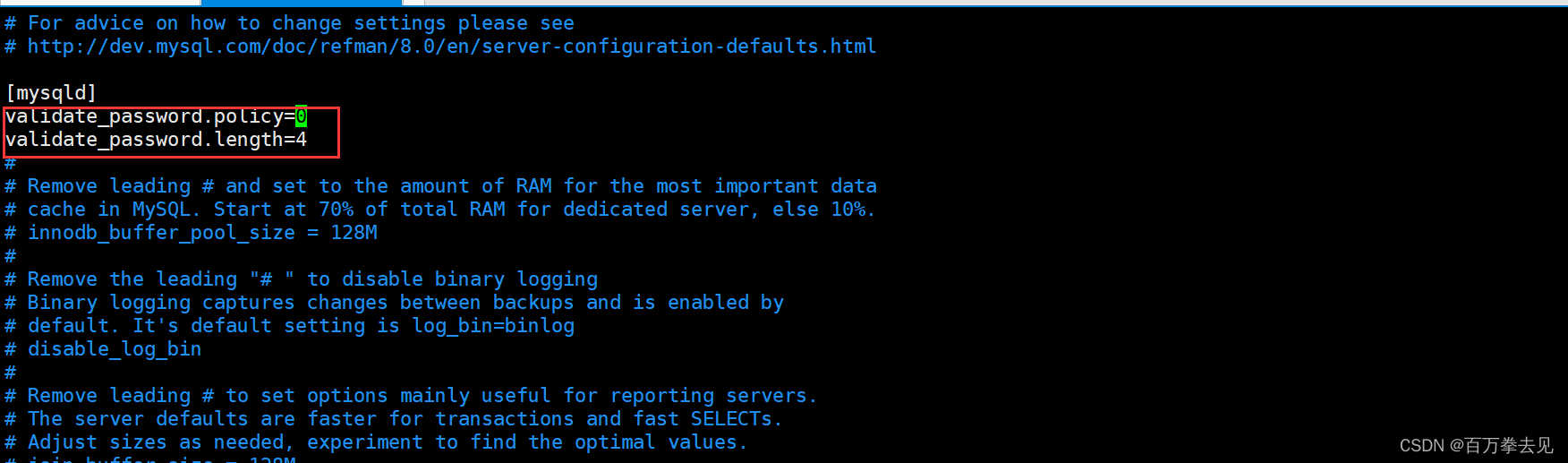
查看原先密码策略:show variables like '%validate_password%';
修改密码策略等级:set global validate_password.policy=0
注:0=low(只限制长度),1=medium(限制长度、字符、数字、大小写)、2=strong(?) 修改密码长度:set global validate_password.length=4 注:密码长度最短为4位
修改密码大小写:set global validate_password.mixed_case_count= 数值;
修改密码字符限制:set global validate_password.sepcial_char_count=数值;
修改密码数字限制:set global validate_password.number_count=数值;
永久修改
需要将要修改的内容写入/etc/my.cnf配置文件中
注:配置文件中,最后不用加";"敲mysql习惯了,会习惯给配置文件后也加一个";"
配置完成后使用:systemctl restart mysqld 重启MySQL即可管理权限
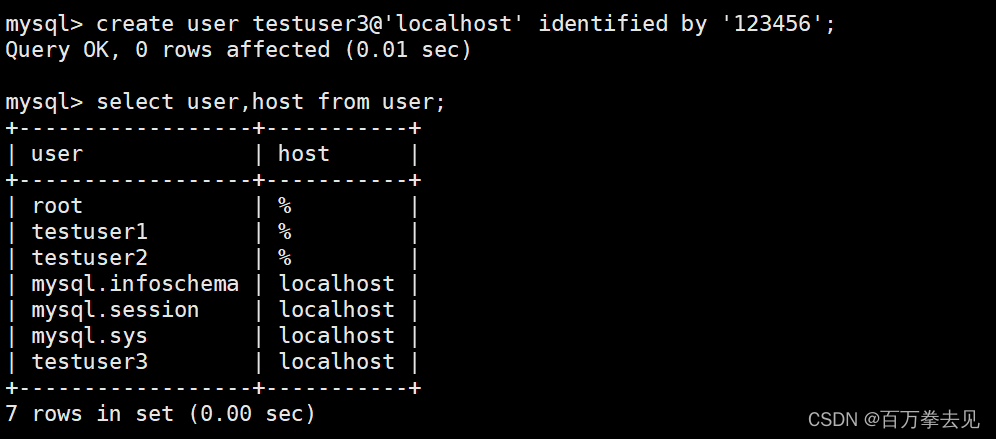
如何创建用户:create user testuser1@'localhost' identified by '密码';
注:@后标注的是哪个主机可以登录,可是是域名,可以是ip,密码的设定要根据密码策略
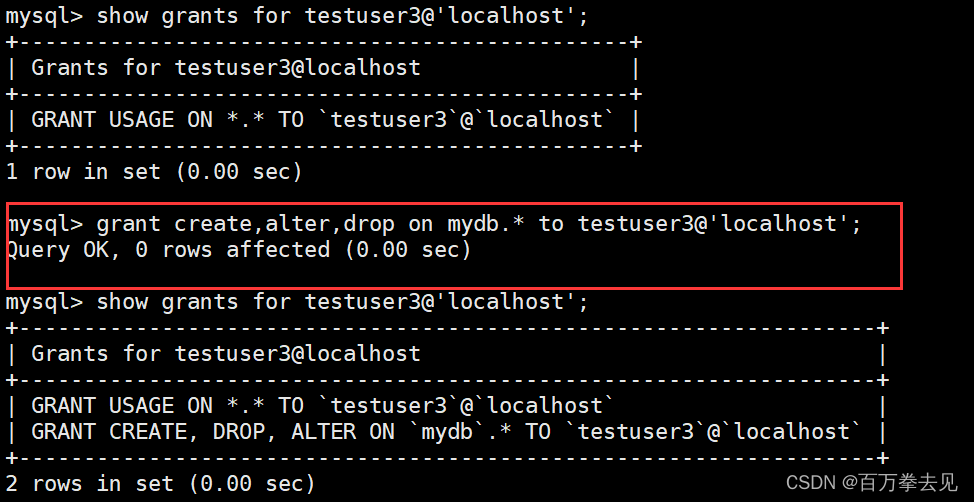
如何查询用户的权限:show grants for 用户名;例查询root用户的权限:show grants for root@localhost
给用户授权:grant 权限的列表(如果是多个权限,用逗号进行分隔) on (库).(表) to username@host
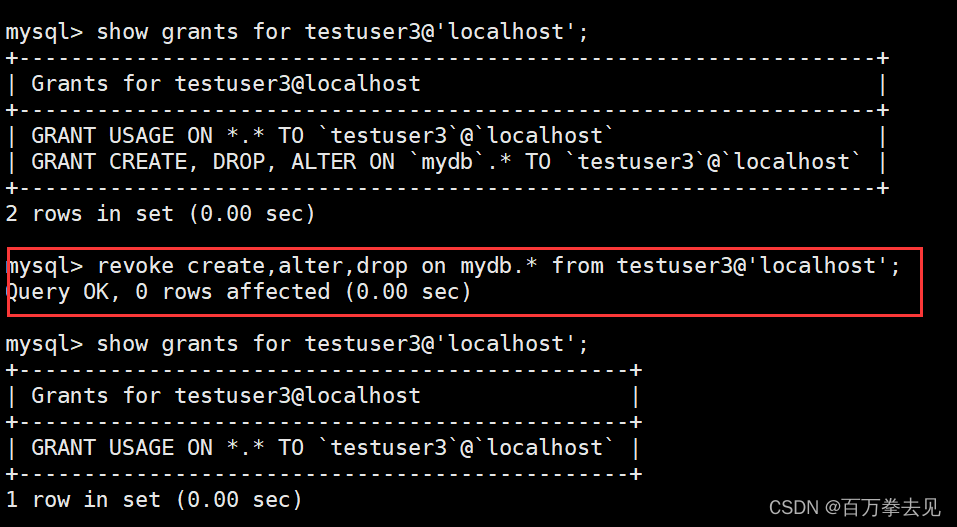
注:在8.x的版本中,不能为未创建的用户授权收回用户授权:revoke 权限的列表(如果是多个权限,用逗号进行分隔) on (库).(表) from username@host

DML:数据操纵语言
insert插入语句
语法格式1:insert into 表名 values(字段1,字段2...)
语法格式2:insert into 表名(字段1,字段3,字段4) values(字段1,字段3,字段4)
语法格式3:insert into 表名 values(字段1,字段2...),(字段1,字段2...),(字段1,字段2...)
语法格式4:insert into 表名 select 字段名 from 表名示例
CREATE TABLE
stu_info2(stu_idint NOT NULL AUTO_INCREMENT COMMENT '学号',stu_namevarchar(30) DEFAULT NULL COMMENT '姓名',stu_agetinyint NOT NULL COMMENT '年龄',stu_genderchar(1) DEFAULT 'M',
PRIMARY KEY (stu_id),
CONSTRAINTstu_info2_chk_1CHECK ((stu_genderin (gbk'M',gbk'F')))
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=gbk格式1:insert into stu_info2 values(null,'张三',15,'F');
格式2:insert into stu_info2(stu_name,stu_age) values('李四',21);
格式3:insert into stu_info2 values(null,'王五',30,'F'),(null,'兰竹',19,'M');
格式4:需要重新创建一个表,这个表的字段是stu_info2的子集
CREATE TABLEstu_info4(
stu_idint NOT NULL AUTO_INCREMENT COMMENT '学号',
stu_namevarchar(30) DEFAULT NULL COMMENT '姓名',
stu_agetinyint NOT NULL COMMENT '年龄',
PRIMARY KEY (stu_id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=gbk然后将stu_info2中的数据插入到stu_info4里
insert into stu_info4 select stu_id,stu_name,stu_age from stu_info2;replace替换语句
语法格式:replace into 表名 [(字段列表)] values(值列表)
示例
格式:replace into stu_info2(stu_id,stu_name,stu_age,stu_gender) values(3,'王五',27,'M');
replace与insert语句的区别
使用replace语句向表插入新纪录时,如果新纪录的主键值或者唯一性约束的字段值与已有记录相同,则已有记录先被删除(注:已有记录删除时也不能违背外键约束条件)然后再插入新纪录
使用replace的最大好处就是可以将delete和insert合二为一(效果相当于更新),形成一个原子操作,这样就无需将delete和insert操作置于事务中了
update更新语句
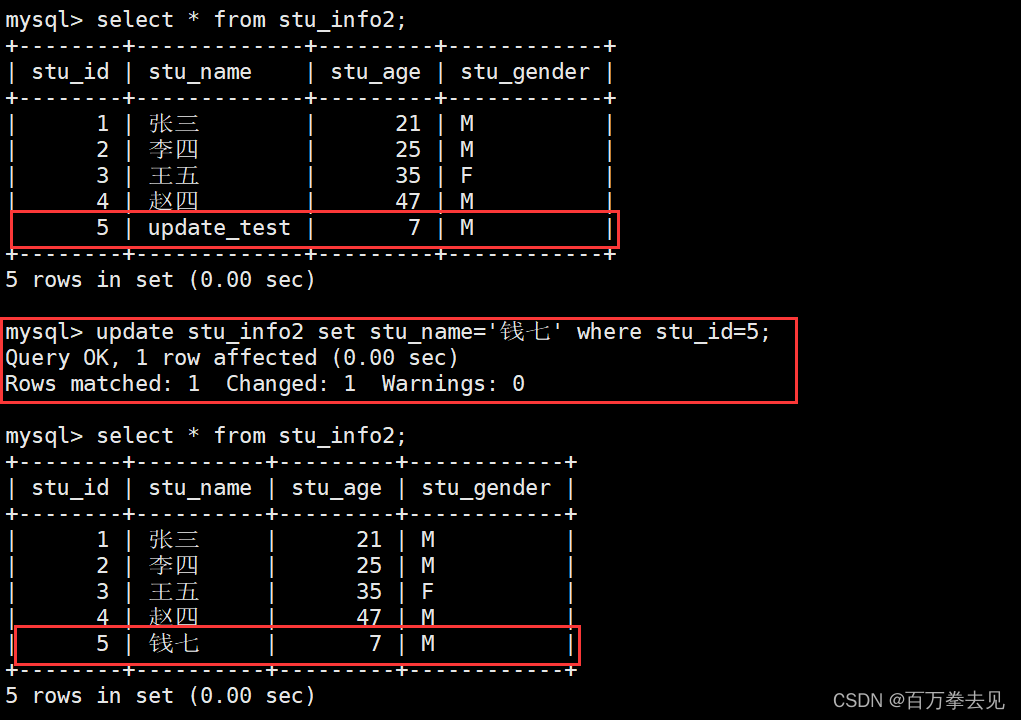
语法格式:update 表名 set 字段1=值 where condition
示例:update stu_info2 set stu_name='钱七' where stu_id=5;
delete删除语句和truncate语句
delete语法格式:delete from 表名 [where condition] # 若没where判断,则全部删除 truncate语法格式:truncate table 表名
drop、truncate、delete的区别
delete:删除数据,保留表结构,最小以行为删除单位,可以回滚,如果数据量大,很慢
truncate:删除所有数据,保留表结构,不可以回滚,速度相对delete很快
drop:删除所有数据和表结构,删除速度最快。
select查询语句
语法格式:select 字段列表 from 表名 [where condition]
where后可跟比较运算符(>、>=、<、<=、=、<=>、!=),逻辑运算符(and、or、not),成员运算符(in、not in),身份运算符(is、not is),模糊(like),正则表达式(regexp),between and select和from中间可以跟*、部分字段、算数表达式、distinct、别名(字段 as 别名)
示例
select * from stu_info2 #查询stu_info2中的所有数据
select 10+10 as num_sum,t1.stu_name,t2.stu_name from stu_info2 as t1,stu_info2 as t2;#可以给字段或表名起别名
select stu_id, distinct stu_name from stu_info2# 对名字重复的行去重
select * from stu_info2 where stu_age between 7 and 47 # 查询年龄在[7,47]之间的所有字段 select * from stu_info2 where stu_name regexp '^张'; #匹配以张开头的所有字段;regexp 正则表达式
select * from stu_info2 where stu_id in(1,3,5); #查询stu_id是1,3,5的所有字段
select * from stu_info2 where stu_name is null; #查询stu_name是null的所有字段
select * from stu_info2 where stu_name like '%张'; #查询所有姓张的所有字段
group by 分组语句
group by自居的真正作用在于与各种聚合函数配合使用,它用来对查询出来的数据进行分组。
分组的含义是:把该列具有相同值的多条记录当成一组记录来处理,最后只输出一条记录 分组函数忽略空值
结果集隐式按升序排列
语法格式:select 查询字段列表 from table_name where condition group by 分组字段列表 查询字段列表:
1、分组字段
2、聚合函数
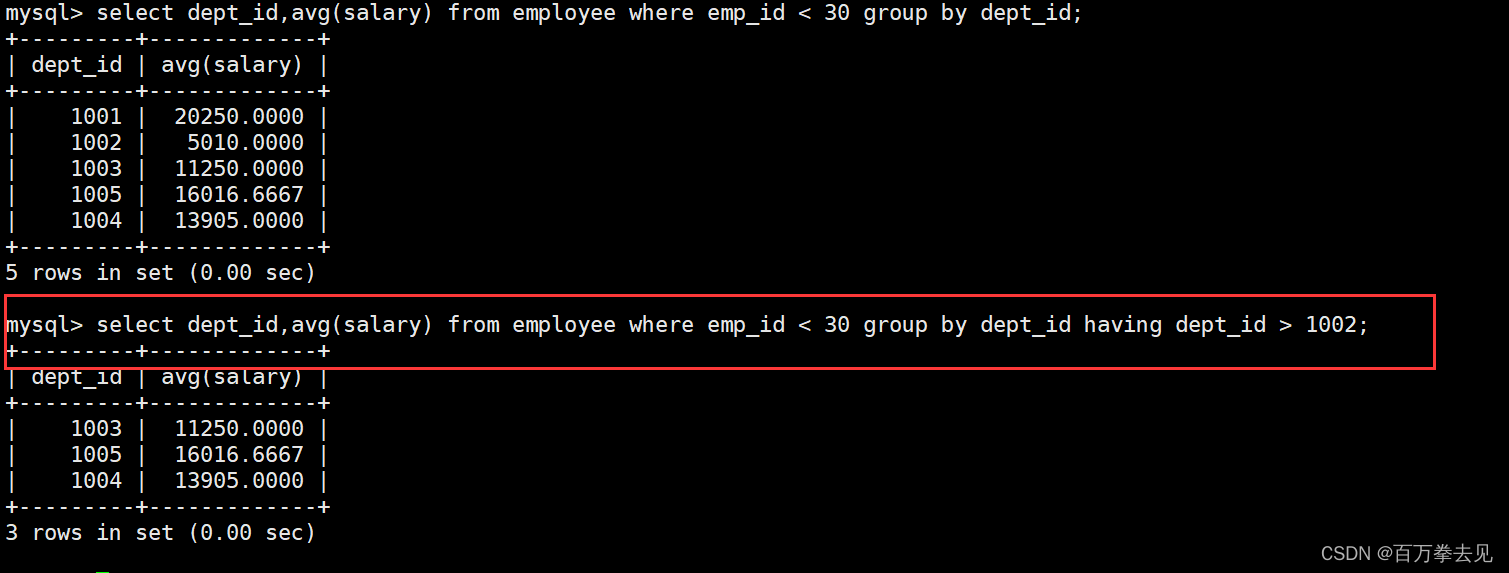
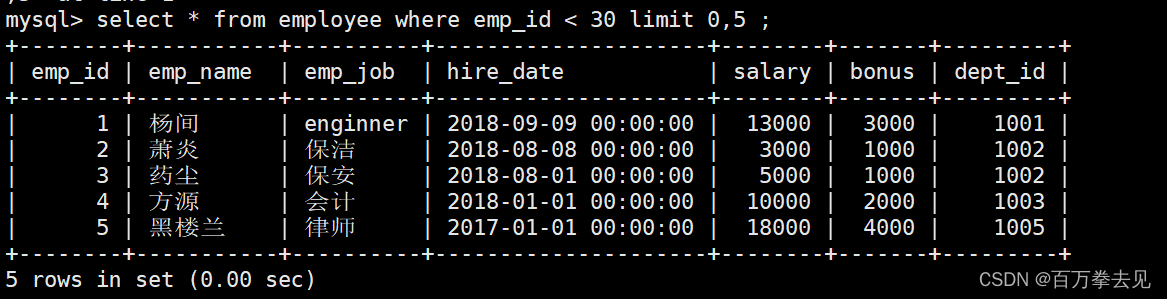
示例: select dept_id avg(salary) from employee where emp_id < 30 group by dept_id
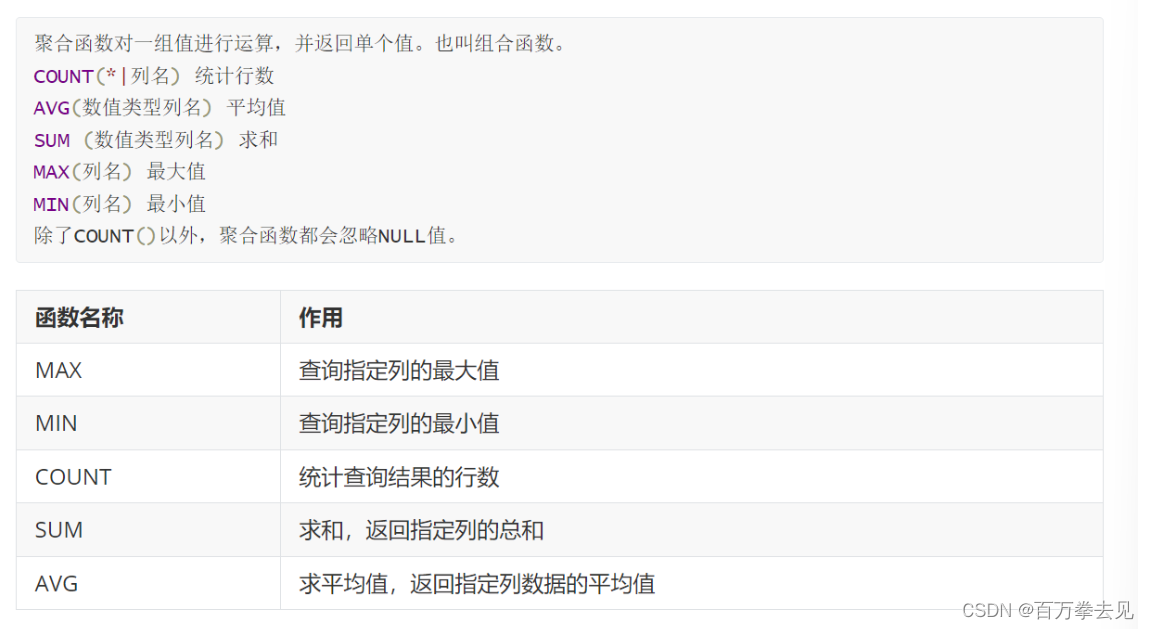
聚合函数
max(列名)
最大值 min(列名)
最小值 count(*|列名)
统计行数 avg(数值类型列名)
平均值 sum(数值类型列名)求和
having语句
where语句的区别:where语句用于过滤分组前的数据行,过滤字段可以为表中的任意字段,having用于过滤分组后的数据行,having的过滤字段列表只能为select 中的查询字段列表中的字段
示例:
group_concat()多行数据合并内聚函数
order by 排序语句
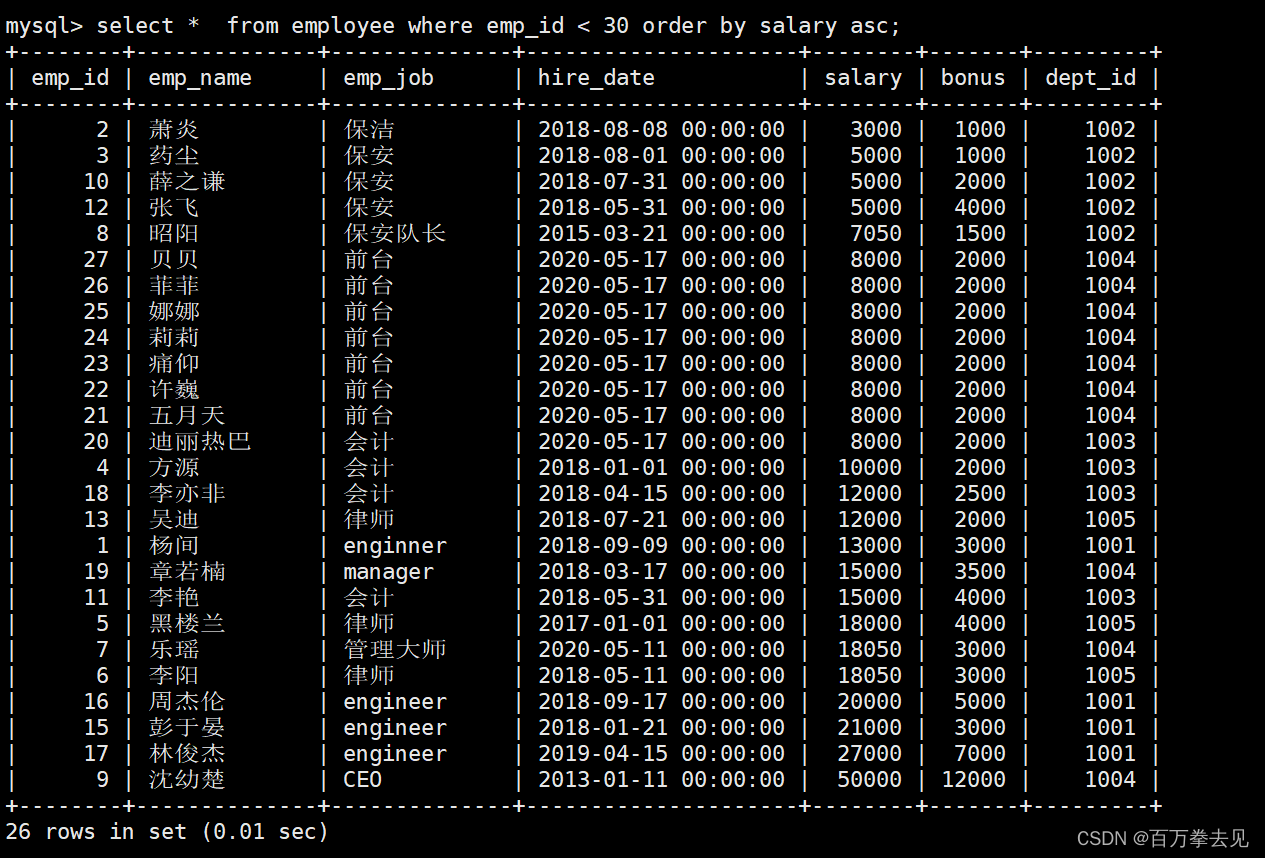
语法格式:select * from table_name order by 字段列表 asc #默认asc升序排序
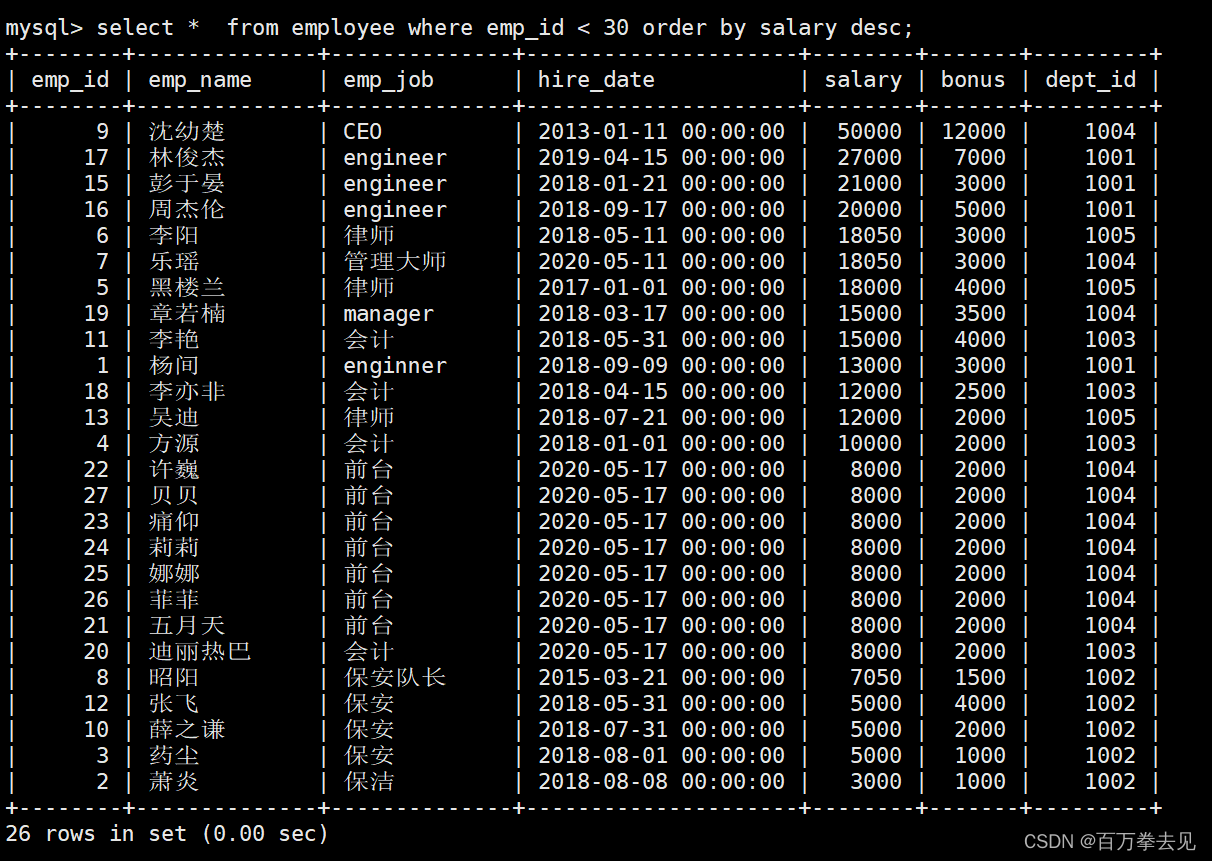
select * from table_name order by 字段列表 desc #desc 降序排序
示例:升序排序
示例:降序排序
union联合查询语句
语法格式:select 查询语句1 union select查询语句2
示例:
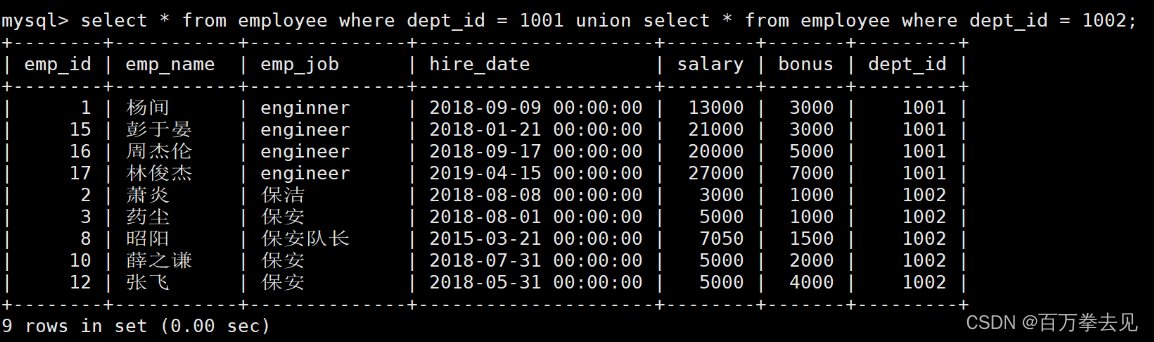
union:过滤重复数据行 union all: 不过滤重复数据行
如何查看查询计划:在select 前加explain
limit 分页语句
语法格式:select 查询字段列表 from table_name limit offset_start,row_count
注:offset_start(偏移量)可以省略不写,不写默认从0开始;row_count规定每次展示几行
多表关联查询
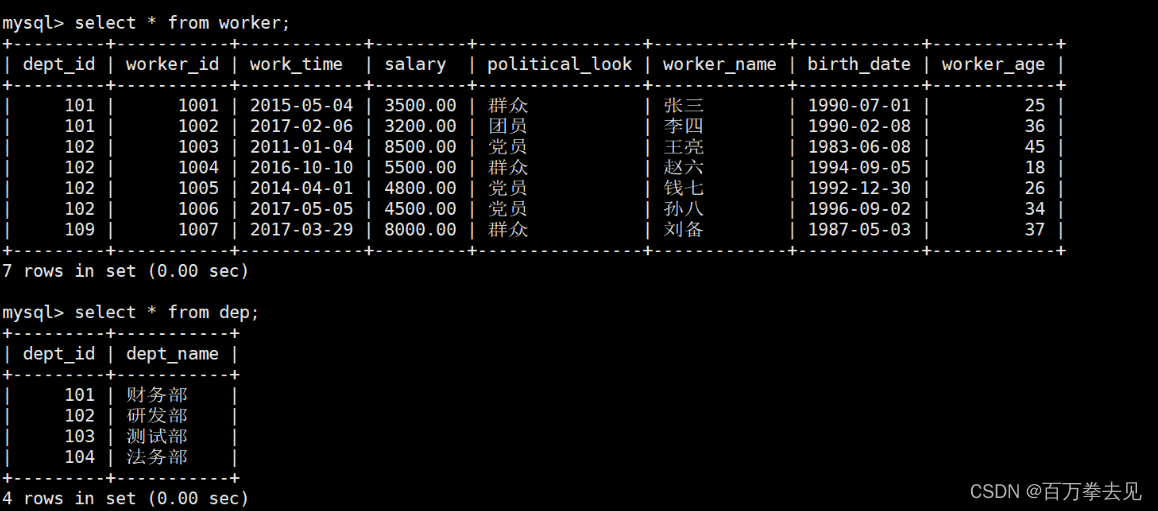
初始完整数据
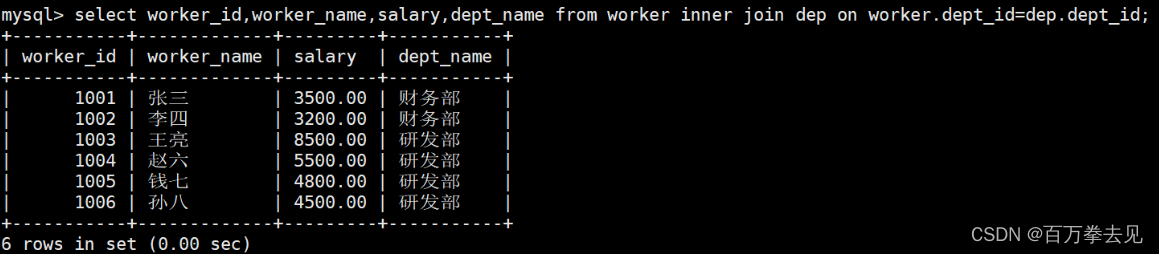
1、inner join
根据on之后的判断条件寻找两个表的交叉部分,然后查询相应的查询字段列表 语法格式:select 表1.字段,表2.字段 ... from 表1 inner join 表2 on 表1.字段=表2.字段 [where 条件语句]; 注:表1.字段=表2.字段 #共同的字段
示例:查询worker_id,worker_name,salary,dept_name;
2、left_join
代表选择的是表1的全部,若表1中的数据在表2没有对应部分,则置为null 示例:
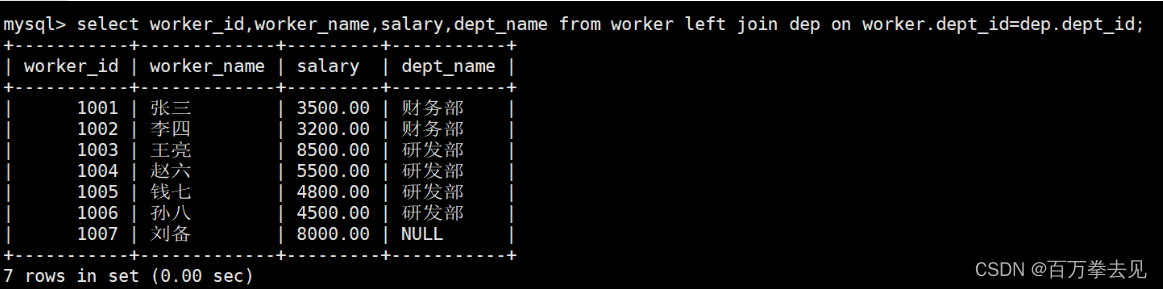
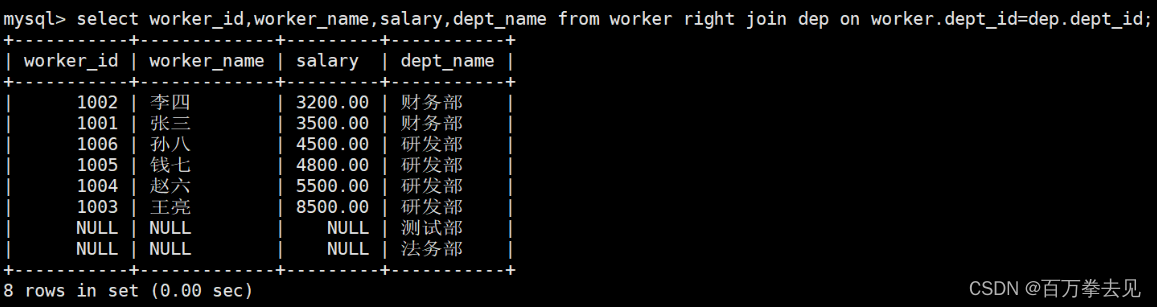
3、right join
代表选择的是表2的全部,若表2的数据在表1中没有对应部分,则置为null 示例:
4、自连接
自己跟自己连接,参与连接的表都是同一张表(通过给表名取别名虚拟实现)
示例:

5、交叉连接
不适用任何匹配条件。生成笛卡尔积


sql的语句执行顺序
from > on > join > where > group by > AGG_FUNC > with > having > selsect > union > distinct > order by > limit #AGG_FUNC是聚合函数
子查询
1、子查询是将一个查询语句嵌套在另一个查询语句中。内部嵌套其他select语句的查询,称为外查询或主查询
2、内层查询语句的查询结果,可以为外层查询语句提供查询条件
3、子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和NOT EXISTS等关键字
4、还可以包含比较运算符:=、!=、>、< 5、子查询应注意有效使用范围
6、主查询中在select和from之间内部嵌套的查询切忌一次查出多个字段
7、子查询要包含在括号内
示例:#查询国家及国家下的省份 select (select t1.name from zone as t1 where t1.id = t2.parent_id) as 国家,t2.name as 省份 from zone as t2 where t2.parent_id in (select t3.id from zone as t3 where t3.parent_id is null);
#select 和 from之间的子查询只能一次查出一个字段,因此只能将国家写为子查询,因为一个省份只对应着一个国家,我们可以根据一个省份去找到一个国家,但是一个国家对应着许多的省份,我们不能根据一个国家去找到目标省份

SQL函数大全
函数方法详解见:MySQL函数大全-优快云博客
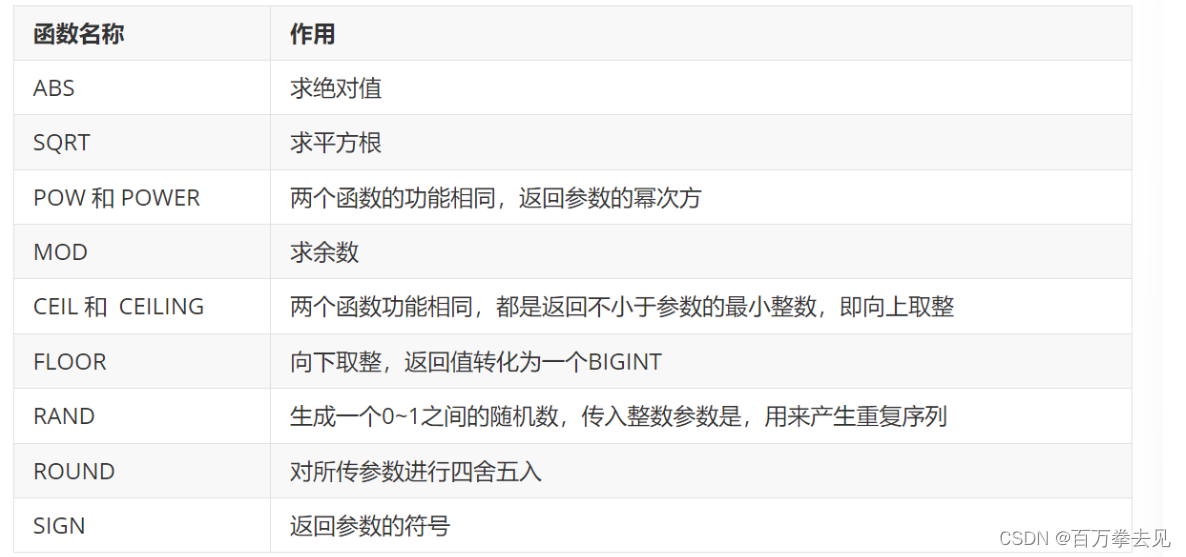
数值型函数
聚合函数
字符串函数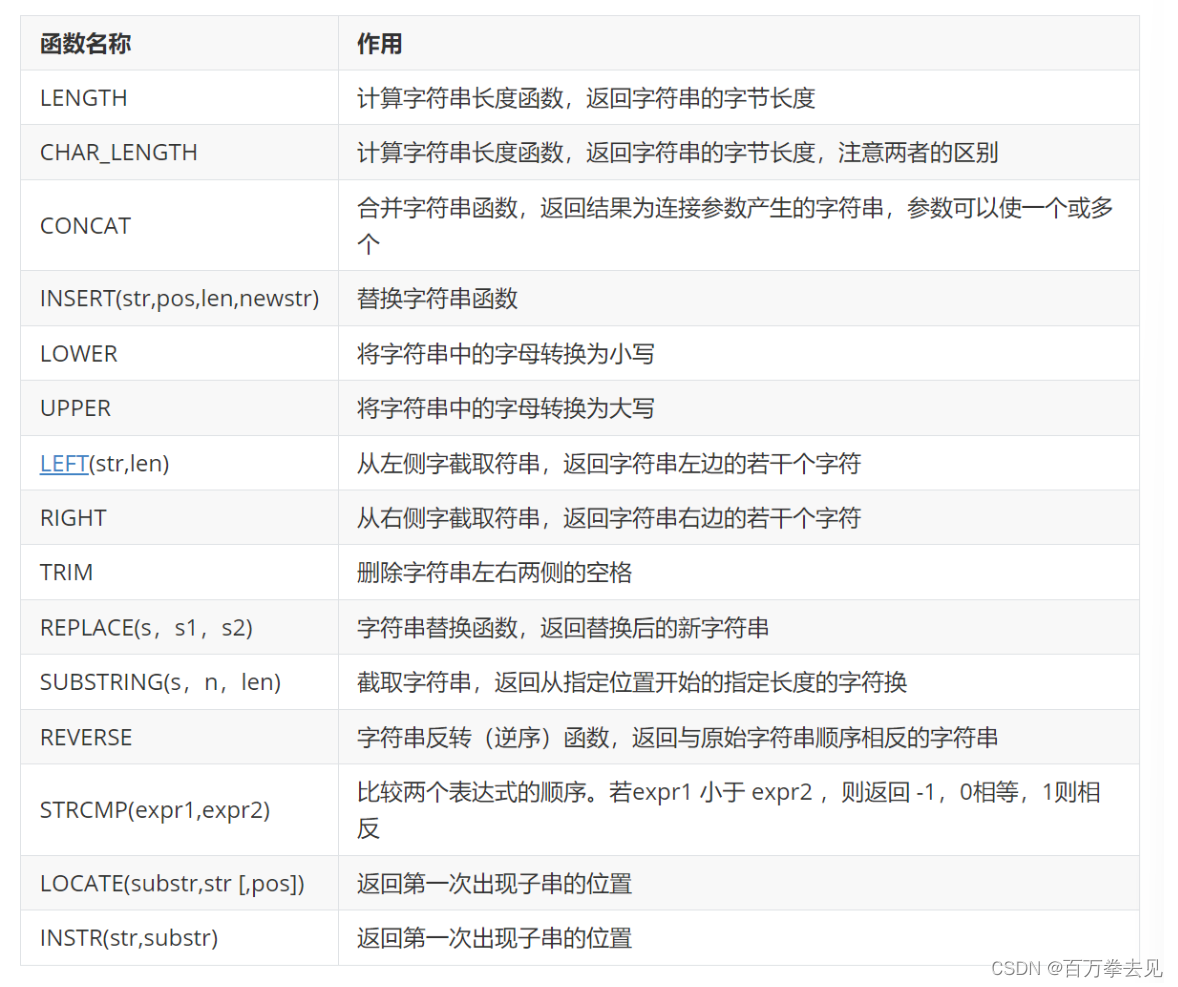
日期和时间函数

流程控制函数
IF(判断式,v1,v2):当判断式为真则返回v1,当判断式为假则返回v2
IFNULL(v1,v2):判断是否为空,若v1不为null,则返回v1,反之返回v2
CASE:搜索语句,将表达式的值逐一和每个when跟的<值>作比较,若相等,则执行后续操作,若所有的when的值都不匹配,则执行else的操作
语法格式:case <表达式> when <值1> then <操作> when <值2> then <操作> ... else <操作> end
面试题
1、为什么InnoDB的批量插入速度相较于MyISAM和Memory来说会低呢?
答:因为InnoDB它是支持事务的,当你在执行DML语句时,在执行之前InnoDB底层会自动的开启事务,操作完成之后底层会自动的提交事务,因此InnoDB的增删改查速率较低
2、InnoDB引擎和MyISAM引擎的区别
- InnoDB支持事务,MyISAM不支持;
- InnoDB支持行锁,MyISAM只支持表锁
- InnoDB支持外键,MyISAM不支持外键
- 聚集索引只有在InnoDB中存储引擎中才存在,而在MyISAM中时不存在的,即MyISAM和InnoDB实现B+Tree的索引方式不同,MyISAM将数据文件和索引文件分开存储,数据文件保存在.myd文件中,索引文件保存在.myi文件中;而InnnoDB将数据文件和索引文件一并存储在同一个.ibd文件中
数据库最多存储两千万条数据吗?
答:不是的,数据库存储的结构是B+数,B+树只有叶子节点可以存储数据。第三层可以存储两千万条数据,但B+树可以不止有三层,数据库一次IO可以查询一页也就是16KB的数据,三层的B+树,就只需要三次IO就可以查到数据;考虑查询速度和存储数量的平衡,数据库存储的最优解就是三层,即是两千万条数据
count(1)和count(字段)的区别:count(1):在统计时,会统计null的记录 count(字段):在统计个数时,不会统计字段为null的记录
count(*)和count(1)和count(列名)的区别
从执行效果上
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表码行,在统计结果时,不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果时,会忽略列值为NULL的个数
从执行效率上
列名为主键:count(列名)会比count(1)快
列名不为主键:count(1)会比count(列名)快
如果表多个列并且没有主键,则count(1)的执行效率是最快的
如果有主键:count(主键)是最快的
如果表只有一个字段,则count(*)最快

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









