




1. 情境
业务需要获取1千万DOI对应的PDF文档,存在则下载,不存在则标识
2. 任务
自动化爬取文献,下载PDF, 并标识对应关系
3. 行动
3.1 解析need_poi.txt至MongoDB
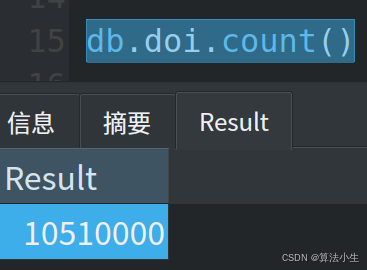
3.2 将信息发送至Kafka供多个消费者消费
我们预期可以用6个消费者,我们主题创建时指定6个分区(分区数限制同一消费者组最大消费者数),我们先用2个分区演示
./bin/kafka-topics.sh --create --topic doi --bootstrap-server localhost:9092 --partitions 2 --replication-factor 1
# 查看分区情况
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group doi-consumer-group --describe
3.3 启动消费者进行消费抓取PMID与not found标识
在消费的时候,我发现CURRENT-OFFSET增加的异常快,但实际任务抓取是缓慢的,经分析是多线程任务执行时自动提交偏移量导致,优化后核心代码如下
consumer = KafkaConsumer(
'doi',
bootstrap_servers='localhost:9092',
auto_offset_reset='latest',
enable_auto_commit=False, # 禁止自动提交
group_id='doi-consumer-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8')),
session_timeout_ms=30000, # 30秒 防止过短时间导致消费者被剔除,再平衡
heartbeat_interval_ms=10000, # 10秒
max_poll_interval_ms=600000 # 10分钟
)
# 消费消息并进行预测
with ThreadPoolExecutor(max_workers=4) as executor:
while True:
# 批量拉取消息
messages = consumer.poll(timeout_ms=1000, max_records=100)
if not messages:
logger.info("No messages received, continuing to poll...")
continue
futures = []
offsets = {}
for topic_partition, partition_messages in messages.items():
for message in partition_messages:
# 爬虫解析,返回结果,在解析的时候同步更新MongoDB库
futures.append(executor.submit(parse, message.value))
leader_epoch = message.leader_epoch if hasattr(message, 'leader_epoch') else None
offsets[topic_partition] = OffsetAndMetadata(offset=message.offset + 1, metadata="doi_metadata", leader_epoch=leader_epoch)
success = True
for future in futures:
try:
result = future.result()
if not result:
success = False
except AssertionError as e:
logger.error(f"AssertionError in task: {e}")
success = False
except Exception as e:
logger.error(f"Task failed: {e}")
success = False
if success and offsets:
# 手动提交偏移量
consumer.commit(offsets=offsets)
executor.shutdown()


3.4 其他任务抓取PDF
PDF下载存在反爬机制,首先解决反爬,攻克下载后在文件重命名时,存在失败问题,经分析是由于多线程下载存在名称相同问题
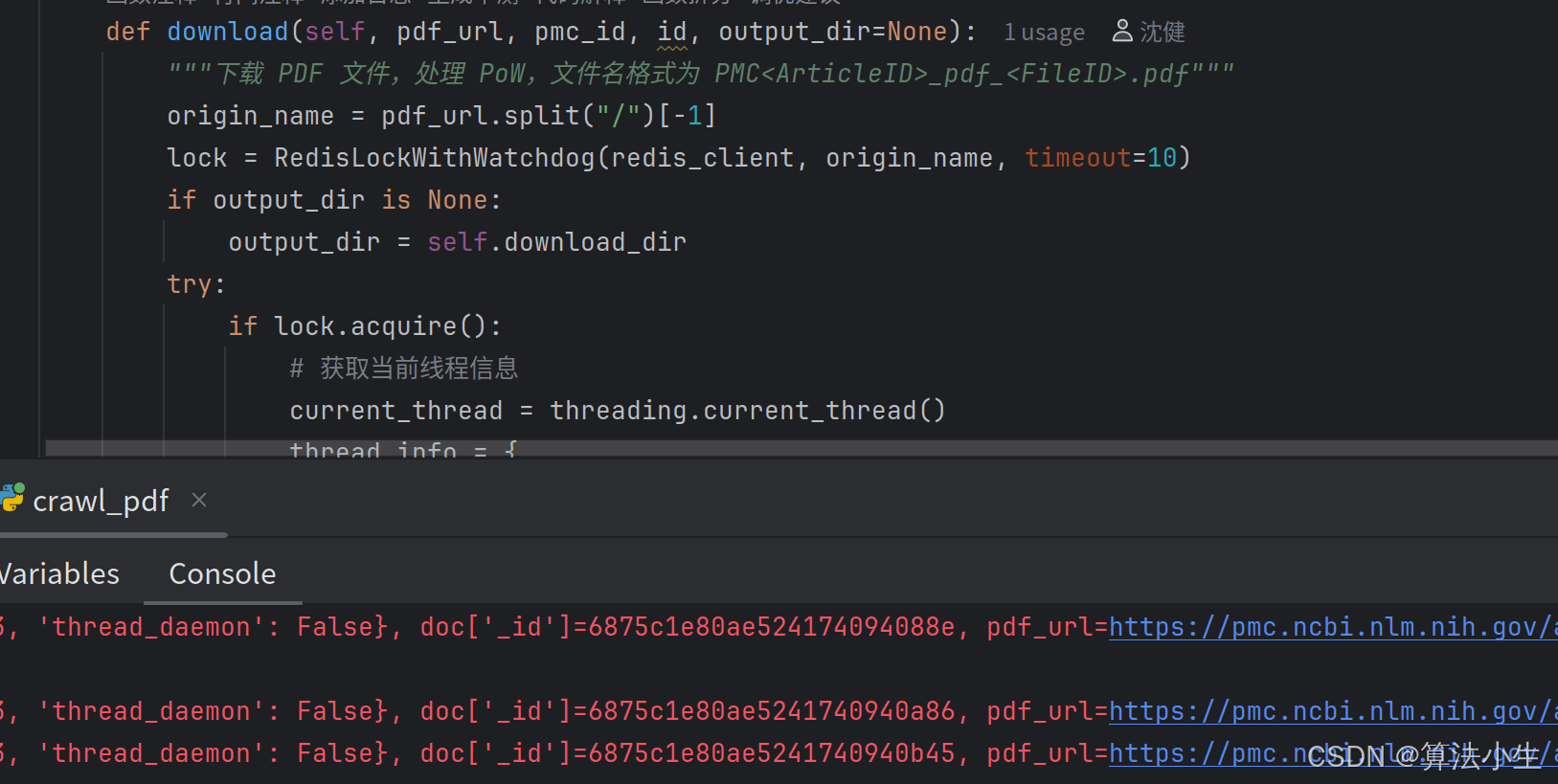
我们通过分布式锁进行解决,下载的文件名上锁,只有获取到锁的线程才可以下载,重命名操作, 另外同名的历史已下载url需要删除,防止url与实际下载pmid报告内容不一致问题

3.5 7天后日志无法消费问题
查看当前偏移量明明未消费完,但是无法继续消费,默认日志保留策略是7天,导致未消费的日志清理了,我们延长日志保留时间
# server.properties
log.retention.hours=672
4. 结果
爬取任务从最初2个月优化至9天,如果Key足够多,可优化至甚至更短时间



















 1570
1570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











