




 本文详细介绍了StarRocks3.2版本中BucketShuffleJoin的实现原理,包括数据分区和分桶机制,以及它如何通过减少网络和内存开销,提升Join查询性能。特别强调了BucketShuffleJoin在等值Join条件下的优势和适用场景。
本文详细介绍了StarRocks3.2版本中BucketShuffleJoin的实现原理,包括数据分区和分桶机制,以及它如何通过减少网络和内存开销,提升Join查询性能。特别强调了BucketShuffleJoin在等值Join条件下的优势和适用场景。
目录
注:本篇文章阐述的是StarRocks-3.2版本的Bucket Shuffle Join
一、StarRocks数据划分
在介绍Bucket Shuffle Join之前,再回顾下StarRocks的数据划分及tablet多副本机制。
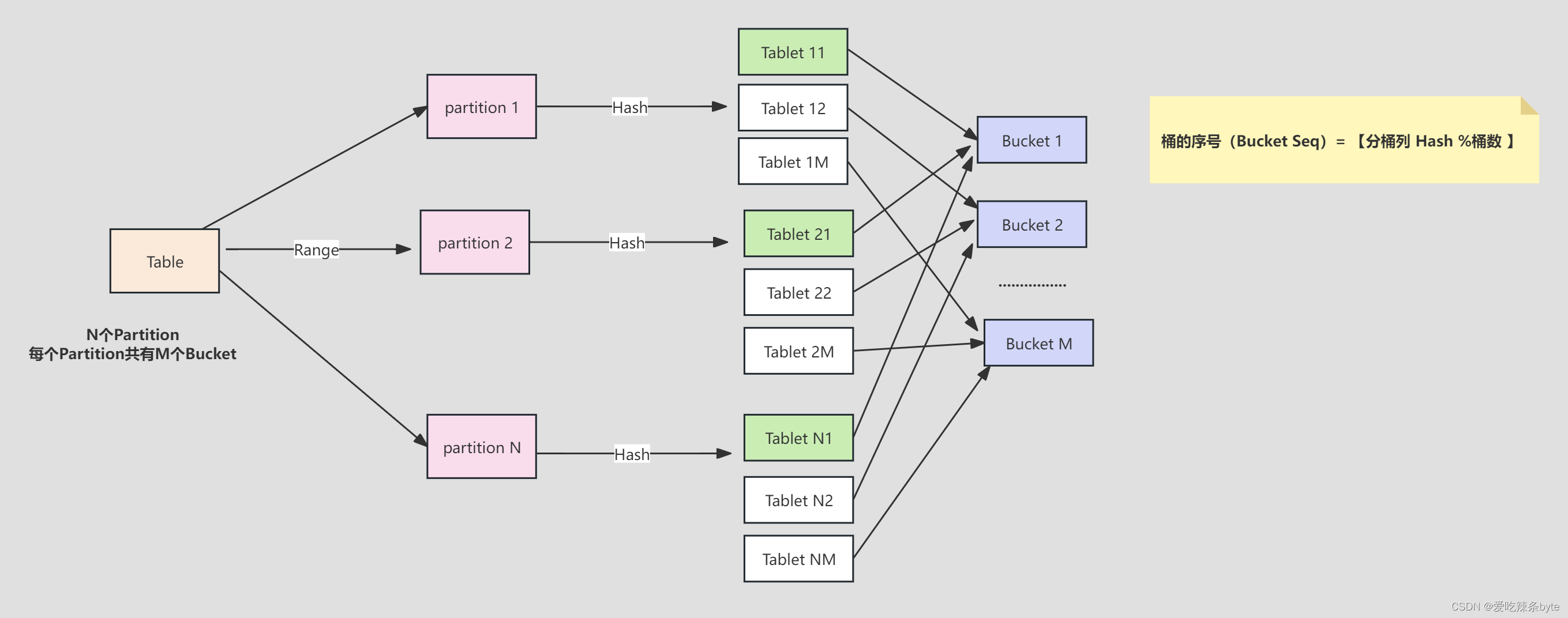
StarRocks支持两层的数据划分,第一层是Range Partition,第二层是Hash Bucket(Tablet)。 StarRocks的数据表按照分区分桶规则,被水平切分成若干个数据分片(Tablet,也称作数据分桶 Bucket)存储在不同的be节点上,每个tablet都有多个副本(默认是3副本)。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。Tablet 是数据移动、复制等操作的最小物理存储单元。 一个 Tablet 只属于一个数据分区(Partition),而一个 Partition 包含若干个 Tablet。
下图说明 Table、Partition、Bucket(Tablet) 的关系:
- Table按照Range的方式按照 date 字段进行分区,得到了 N 个Partition
- 每个 Partition 通过相同的 Hash 方式将其中的数据划分为 M个Bucket(Tablet)
- 从逻辑上来说,Bucket 1 可以包含 N 个 Partition 中划分得到的数据,比如下图中的 Tablet 11、Tablet 21、Tablet N1
1.1 分区
逻辑概念,分区用于将数据划分成不同的区间,主要作用是将一张表按照分区键拆分成不同的管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
1.2 分桶
物理概念,StarRocks一般采用Hash算法作为分桶算法。在同一分区内,分桶键哈希值相同的数据会划分到同一个tablet(数据分片),tablet以多副本冗余的形式存储,是数据均衡和恢复的最⼩单位,数据导入和查询最终都下沉到所涉及的 tablet副本上。
二、Bucket Shuffle Join实现原理
2.1 Bucket Shuffle Join概述
StarRocks支持
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









