




 本文深入探讨了大数据领域的关键技术,包括HDFS的大吞吐量特性,HBase作为NoSQL数据库在PB级数据存储上的优势,以及YARN资源管理、MapReduce、Spark和Flink在大规模数据分析与流处理方面的应用。
本文深入探讨了大数据领域的关键技术,包括HDFS的大吞吐量特性,HBase作为NoSQL数据库在PB级数据存储上的优势,以及YARN资源管理、MapReduce、Spark和Flink在大规模数据分析与流处理方面的应用。
HDFS
不适合交互场景;
大吞吐量;
HBase
Key-Value Store, 适合存储半结构化数据,例如: 图片数据 ;
对于同一个key, Value可以具有多个列column, 每个列可以具有不同时间纬度下的值,也就是说可以拿到某个key 对应value随时间变化的值;
HBase适合大数据场景存储,数据量要足够大, PB级别;
Nosql数据库,不支持sql 作为查询语言;
强一致性支持;
YARN
资源管理系统
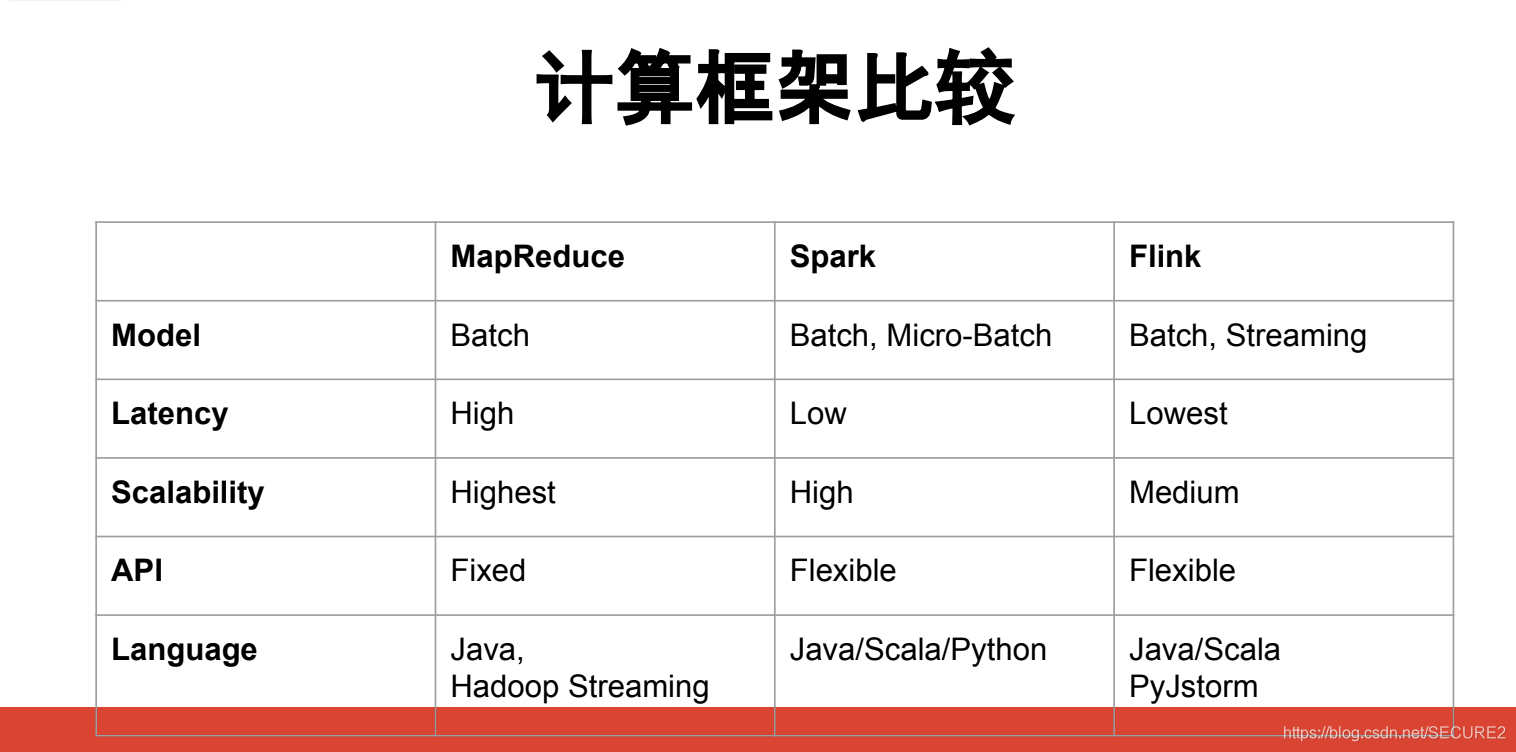
MapReduce
Highly Scalable, fault-tolerant;
SQL support throught Hive;
PB规模数据分析;
Spark
Functional Programing(Scala);
10~100倍 speed up over MapReduce;
Flink
流式处理;

















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









