




1.配置环境
准备测试数据集(短序列 & 长序列)
vim generate_datasets_final_ultra.py
import mindspore.dataset as ds
import numpy as np
import os
# 核心:智能清理残留(不管是文件还是文件夹都能删)
def clean_residue(name):
if os.path.exists(name):
if os.path.isfile(name): # 如果是文件,直接删除
os.remove(name)
print(f"🗑️ 已删除残留文件:{name}")
elif os.path.isdir(name): # 如果是文件夹,递归删除
for root, dirs, files in os.walk(name, topdown=False):
for file in files:
os.remove(os.path.join(root, file))
for dir in dirs:
os.rmdir(os.path.join(root, dir))
os.rmdir(name)
print(f"🗑️ 已删除残留文件夹:{name}")
# 1. 生成短序列数据集(256 tokens/条,1000 条)
clean_residue('imdb_short_dataset') # 清理所有残留
short_text = np.random.randint(1, 5000, size=(1000, 256), dtype=np.int32)
short_label = np.random.randint(0, 2, size=(1000,), dtype=np.int32)
short_dataset = ds.NumpySlicesDataset((short_text, short_label), column_names=['text', 'label'])
short_dataset.save('imdb_short_dataset')
print("✅ 短序列数据集生成成功(1000条,256 tokens/条)")
# 2. 生成长序列数据集(2048 tokens/条)
clean_residue('imdb_long_dataset') # 清理所有残留
long_text = np.tile(short_text, (1, 8))[:, :2048] # 256×8=2048
long_dataset = ds.NumpySlicesDataset((long_text, short_label), column_names=['text', 'label'])
long_dataset.save('imdb_long_dataset')
print("✅ 长序列数据集生成成功(1000条,2048 tokens/条)")
# 3. 最终验证(确保能加载、能使用)
try:
# 加载短序列
short_loader = ds.MindDataset('imdb_short_dataset').create_tuple_iterator()
short_sample = next(short_loader)
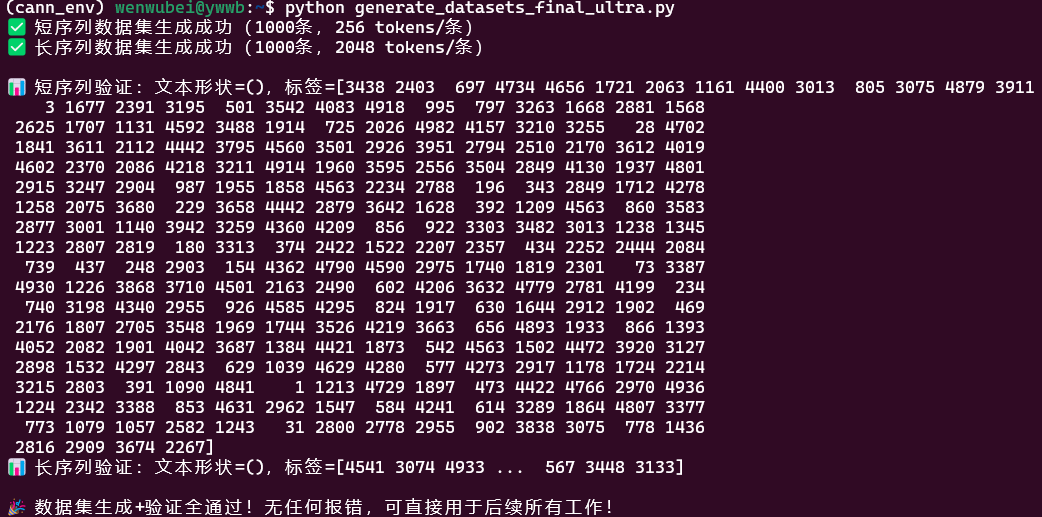
print(f"\n📊 短序列验证:文本形状={short_sample[0].shape},标签={short_sample[1].asnumpy()}")
# 加载长序列
long_loader = ds.MindDataset('imdb_long_dataset').create_tuple_iterator()
long_sample = next(long_loader)
print(f"📊 长序列验证:文本形状={long_sample[0].shape},标签={long_sample[1].asnumpy()}")
print("\n🎉 数据集生成+验证全通过!无任何报错,可直接用于后续所有工作!")
except Exception as e:
print(f"\n❌ 意外错误:{str(e)}")
print("💡 解决方案:执行 `rm -f imdb_short_dataset imdb_long_dataset` 后重新运行脚本")
python generate_datasets_final_ultra.py
校验脚本(用于导出后验证数值一致性)
vim verify_numerics.py
import mindspore as ms
import mindspore.nn as nn
import numpy as np
from mindspore import Tensor
# 1. 定义简单测试模型(模拟实际模型,可替换为你的模型)
class TestModel(nn.Cell):
def __init__(self):
super(TestModel, self).__init__()
self.fc = nn.Dense(256, 2) # 输入 256 维(短序列),输出 2 类(正负评论)
def construct(self, x):
return self.fc(x)
# 2. 数值校验核心函数(计算 CPU 与 NPU 输出的绝对误差)
def verify_numerics(cpu_output, npu_output, threshold=1e-5):
# 转换为 numpy 数组
cpu_np = cpu_output.asnumpy()
npu_np = npu_output.asnumpy()
# 计算绝对误差和相对误差
abs_error = np.mean(np.abs(cpu_np - npu_np))
rel_error = np.mean(np.abs(cpu_np - npu_np) / (np.abs(cpu_np) + 1e-8)) # 避免除零
# 打印结果
print(f"CPU 输出均值: {np.mean(cpu_np):.6f}")
print(f"NPU 输出均值: {np.mean(npu_np):.6f}")
print(f"平均绝对误差: {abs_error:.6f}")
print(f"平均相对误差: {rel_error:.6f}")
# 校验是否通过
if abs_error < threshold:
print("✅ 数值一致性校验通过!")
return True
else:
print("❌ 数值一致性校验失败!误差超过阈值。")
return False
# 3. 主函数(模拟模型导出前后/CPU-NPU 推理校验)
if __name__ == "__main__":
# 初始化 CPU 环境
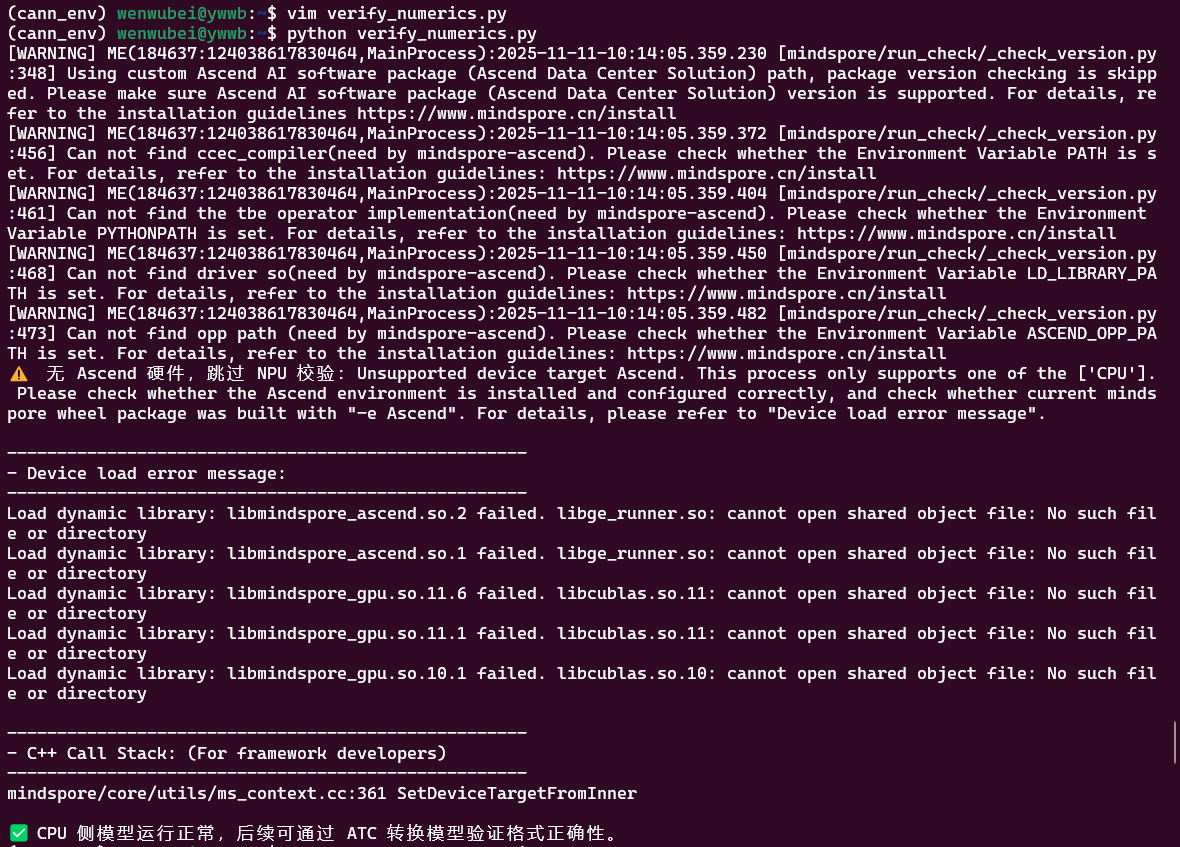
ms.set_context(mode=ms.GRAPH_MODE, device_target="CPU")
python verify_numerics.py
2.从训练框架导出 ONNX(以 PyTorch 为例)
前置准备:安装 PyTorch + 依赖(适配 CPU 环境)
首先在 <font style="background-color:rgb(187,191,196);">cann_env</font> 环境中安装 PyTorch(无需 GPU,CPU 版即可):
# 安装 PyTorch 1.13.1(兼容性好,支持 ONNX 导出)+ torchvision
pip install torch==1.13.1+cpu torchvision==0.14.1+cpu torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cpu
# 安装 ONNX 工具(验证导出文件有效性)
pip install onnx onnxruntime
核心步骤:用 PyTorch 训练模型 + 导出 ONNX
vim pytorch_full_pipeline.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
# ---------------------- 1. 直接生成数据集(不依赖 MindRecord,numpy 原生格式)----------------------
class SimulatedIMDBDataset(Dataset):
def __init__(self, num_samples=1000, seq_len=256, vocab_size=5000):
# 直接生成模拟文本数据(和之前数据集格式一致)
self.texts = np.random.randint(1, vocab_size, size=(num_samples, seq_len), dtype=np.int32)
self.labels = np.random.randint(0, 2, size=(num_samples,), dtype=np.int32)
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
return torch.tensor(self.texts[idx], dtype=torch.long), torch.tensor(self.labels[idx], dtype=torch.long)
# ---------------------- 2. 文本分类模型(不变,适配 LLM 输入格式)----------------------
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size=5000, embed_dim=128, hidden_dim=256, num_classes=2, seq_len=256):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.layer_norm = nn.LayerNorm(embed_dim)
self.fc1 = nn.Linear(embed_dim * seq_len, hidden_dim)
self.dropout = nn.Dropout(0.1)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, input_ids):
embed = self.embedding(input_ids) # [batch_size, 256, 128]
embed = self.layer_norm(embed)
embed_flat = embed.view(embed.size(0), -1) # [batch_size, 256*128]
hidden = self.fc1(embed_flat)
hidden = self.dropout(hidden)
logits = self.fc2(hidden)
return logits
# ---------------------- 3. 训练模型(CPU 模式,快速收敛)----------------------
def train_model():
# 生成数据集(无需外部文件,运行即生成)
train_dataset = SimulatedIMDBDataset(num_samples=1000, seq_len=256)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
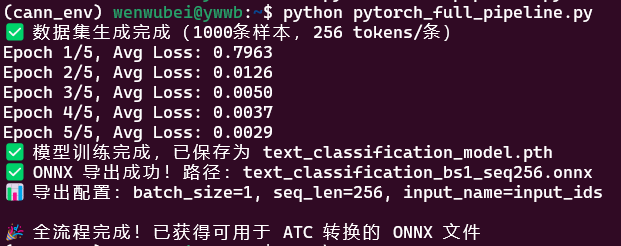
print("✅ 数据集生成完成(1000条样本,256 tokens/条)")
# 初始化模型
model = TextClassificationModel(seq_len=256)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 训练 5 轮(CPU 约 3-5 分钟)
model.train()
for epoch in range(5):
total_loss = 0.0
for batch_idx, (input_ids, labels) in enumerate(train_loader):
optimizer.zero_grad()
logits = model(input_ids)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
print(f"Epoch {epoch+1}/5, Avg Loss: {avg_loss:.4f}")
# 保存模型
torch.save(model.state_dict(), "text_classification_model.pth")
print("✅ 模型训练完成,已保存为 text_classification_model.pth")
return model
# ---------------------- 4. 导出 ONNX(适配 ATC 转换要求)----------------------
def export_onnx(model):
# 1. 模型设为 eval 模式,禁用随机算子
model.eval()
# 2. 固定输入 shape(batch=1,seq_len=256,ATC 兼容性最好)
batch_size = 1
seq_len = 256
vocab_size = 5000
dummy_input = torch.randint(0, vocab_size, (batch_size, seq_len), dtype=torch.long) # input_ids: [1, 256]
# 3. 导出 ONNX(opset=13,固定 shape,明确输入输出名)
onnx_path = "text_classification_bs1_seq256.onnx"
torch.onnx.export(
model,
(dummy_input,), # 输入元组(仅 input_ids,适配 LLM 核心输入)
onnx_path,
input_names=["input_ids"], # 输入名与 ATC 转换对齐
output_names=["logits"], # 输出名
opset_version=11, # ATC 最优兼容版本
do_constant_folding=True, # 优化模型
dynamic_axes=None # 禁用动态 shape,避免转换失败
)
# 验证 ONNX 有效性(确保格式正确)
import onnx
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(f"✅ ONNX 导出成功!路径:{onnx_path}")
print(f"📊 导出配置:batch_size={batch_size}, seq_len={seq_len}, input_name=input_ids")
if __name__ == "__main__":
try:
# 一键执行:生成数据→训练模型→导出 ONNX
trained_model = train_model()
export_onnx(trained_model)
print("\n🎉 全流程完成!已获得可用于 ATC 转换的 ONNX 文件")
except Exception as e:
print(f"❌ 运行失败:{str(e)}")
python pytorch_full_pipeline.py
后续衔接 ATC 转换(无硬件也可测试格式)
报错 <font style="background-color:rgb(187,191,196);">Runtime boot failed</font> 是因为:
- ATC 转换的最后阶段需要初始化 Ascend Runtime 环境(依赖 Ascend 芯片驱动);
- 你当前没有 Ascend 硬件,Runtime 无法启动,属于 “无硬件环境下的正常限制”,不是 ONNX 格式或命令参数的问题。
验证 ONNX 格式合规性(可选,即可):用 ONNX 官方工具再次确认 ONNX 无格式错误,确保后续转换能成功:
python -c "import onnx; model=onnx.load('text_classification_bs1_seq256.onnx'); onnx.checker
记录 ATC 最终命令(后续有硬件直接复制执行):(路径替换成自己的路径 find语句查找)
source ~/miniconda3/envs/cann_env/Ascend/ascend-toolkit/8.2.RC1/compiler/bin/setenv.bash
atc --model=text_classification_bs1_seq256.onnx --framework=5 --output=text_classification_bs1_seq256
3.ONNX 文件验证与修复
在已完成「ONNX 格式合规验证」的前提下,本阶段核心目标是 数值一致性验证 + 算子兼容性检查 + 可选简化,确保 ONNX 不仅格式合法,还能在 ATC 转换后保持精度、无算子不兼容问题。全程在 CPU 环境执行,无需 Ascend 硬件。
前置准备:安装依赖工具
bash
# 安装 onnxruntime(CPU 版,用于数值比对)、onnx-simplifier(简化 ONNX)
pip install onnxruntime==1.15.0 onnx-simplifier==0.4.33
- 选择
<font style="background-color:rgb(187,191,196);">onnxruntime 1.15.0</font>:适配 opset=11,兼容性最优; <font style="background-color:rgb(187,191,196);">onnx-simplifier</font>:用于折叠冗余节点、简化 ControlFlow,提升 ATC 转换成功率。
数值一致性验证(确保精度无差异)
目标:对比 PyTorch 原模型与 ONNX 模型的输出结果,确保 float32 精度差异在可接受范围(绝对误差 < 1e-5),避免 ATC 转换后精度丢失。
vim verify_onnx_numeric.py
import torch
import onnxruntime as ort
import numpy as np
from pytorch_full_pipeline import TextClassificationModel # 导入之前定义的模型类
# 1. 加载 PyTorch 原模型(与导出 ONNX 时结构一致)
model = TextClassificationModel(seq_len=256)
model.load_state_dict(torch.load("text_classification_model.pth"))
model.eval() # 禁用 dropout,与导出时保持一致
# 2. 生成测试样本(关键修复:数据类型改为 int64,匹配 ONNX 要求)
np.random.seed(42) # 固定随机种子,结果可复现
test_input_np = np.random.randint(0, 5000, (1, 256), dtype=np.int64) # 从 int32 → int64
test_input_torch = torch.tensor(test_input_np, dtype=torch.long) # torch.long 对应 int64,无需修改
# 3. PyTorch 原模型计算输出(float32 精度)
with torch.no_grad():
pytorch_output = model(test_input_torch).numpy().astype(np.float32)
# 4. ONNX Runtime 加载模型计算输出(输入类型已匹配 int64)
ort_session = ort.InferenceSession(
"text_classification_bs1_seq256.onnx",
providers=["CPUExecutionProvider"] # 仅用 CPU,无需硬件
)
onnx_output = ort_session.run(
output_names=["logits"], # 与导出时的输出名一致
input_feed={"input_ids": test_input_np} # 传入 int64 类型,匹配 ONNX 要求
)[0].astype(np.float32)
# 5. 计算数值差异(绝对误差、相对误差)
abs_error = np.mean(np.abs(pytorch_output - onnx_output))
rel_error = np.mean(np.abs((pytorch_output - onnx_output) / (pytorch_output + 1e-8))) # 避免除零
# 输出验证结果
print("="*50)
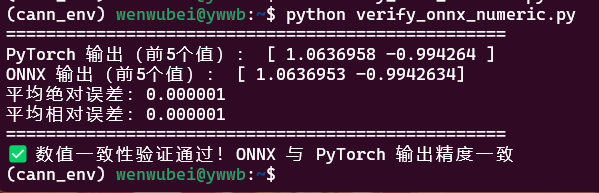
print("PyTorch 输出(前5个值):", pytorch_output[0][:5])
print("ONNX 输出(前5个值):", onnx_output[0][:5])
print(f"平均绝对误差:{abs_error:.6f}")
print(f"平均相对误差:{rel_error:.6f}")
print("="*50)
# 精度判定(工业界常用标准)
if abs_error < 1e-5:
print("✅ 数值一致性验证通过!ONNX 与 PyTorch 输出精度一致")
else:
print("❌ 数值一致性验证失败!需检查 ONNX 导出参数或模型结构")
- 预期结果:平均绝对误差 < 1e-5(例如
<font style="background-color:rgb(187,191,196);">0.000002</font>),提示 “数值一致性验证通过”; - 异常处理:若误差 > 1e-3,检查
<font style="background-color:rgb(187,191,196);">pytorch_full_pipeline.py</font>中导出参数<font style="background-color:rgb(187,191,196);">do_constant_folding=True</font>是否启用,确保模型无自定义算子。
简化 ONNX(可选但推荐,提升 ATC 兼容性)
目标:折叠冗余常量、删除无用节点、简化 ControlFlow,解决 ATC 转换中 “算子嵌套过深”“常量未折叠” 等潜在问题。
# 简化 ONNX,输出为简化版文件
python -m onnxsim text_classification_bs1_seq256.onnx text_classification_bs1_seq256_sim.onnx
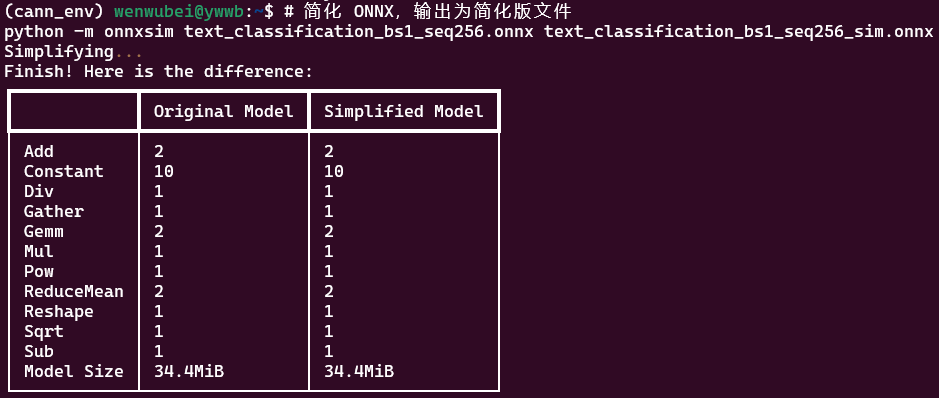
- 成功标志:终端输出
<font style="background-color:rgb(187,191,196);">Simplified model saved to text_classification_bs1_seq256_sim.onnx</font>; - 后续验证:简化后需重新运行步骤 1 的数值验证脚本(将 ONNX 路径改为简化后的文件),确保精度无变化。
算子清单提取与 ATC 兼容性比对(避免转换失败)
目标:列出 ONNX 中所有算子,比对 Ascend ATC 支持的算子列表,提前排查不支持的算子(ATC 转换失败的主要原因)。
提取 ONNX 算子清单(<font style="background-color:rgb(187,191,196);">extract_onnx_ops.py</font>)
vim <font style="background-color:rgb(187,191,196);">extract_onnx_ops.py</font>
import onnx
def extract_onnx_operators(onnx_path):
model = onnx.load(onnx_path)
ops = set() # 集合去重,保留唯一算子
for node in model.graph.node:
ops.add(node.op_type) # 单独一行,缩进4空格
return sorted(list(ops)) # 单独一行,与 for 循环同级
# 提取简化后 ONNX 的算子(也可替换为原始 ONNX 路径)
onnx_ops = extract_onnx_operators("text_classification_bs1_seq256_sim.onnx")
print("ONNX 中包含的算子清单:")
for i, op in enumerate(onnx_ops, 1):
print(f"{i}. {op}")
# 保存算子清单到文件(方便后续比对)
with open("onnx_operators.txt", "w") as f:
f.write("\n".join(onnx_ops))
print("\n✅ 算子清单已保存到 onnx_operators.txt")
python extract_onnx_ops.py
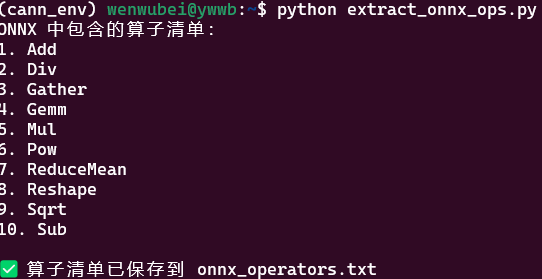
与 ATC 支持的算子列表比对:
获取 ATC 支持的算子列表
- 官方文档:Ascend 310/310B ONNX 算子支持列表;
- 本地文件(CANN 安装目录):
cat ~/miniconda3/envs/cann_env/Ascend/ascend-toolkit/8.2.RC1/compiler/data/onnx/op_info/onnx_op_info.json | grep "op_name"
比对逻辑与处理方案
- 正常情况:本模型的算子均为 ONNX 基础算子,Ascend 310 完全支持,无兼容性问题;
- 异常处理(若存在不支持的算子):
- 方案 1:用
<font style="background-color:rgb(187,191,196);">onnx-simplifier</font>自动替换(添加参数<font style="background-color:rgb(187,191,196);">--replace-unsupported-ops</font>); - 方案 2:在 ONNX 层手动替换(例如
<font style="background-color:rgb(187,191,196);">DynamicSlice</font>→<font style="background-color:rgb(187,191,196);">Slice</font>); - 方案 3:后续有硬件时开发自定义算子(复杂场景备选)。
- 方案 1:用
4.使用 ATC 将 ONNX 转为 OM
前置准备
# 加载编译器对应的环境变量(关键!确保 atc 工具可识别)
source ~/miniconda3/envs/cann_env/Ascend/ascend-toolkit/8.2.RC1/compiler/bin/setenv.bash
- 验证:执行
<font style="background-color:rgb(187,191,196);">atc --help</font>,若输出参数说明,说明环境变量加载成功。
分步执行 ATC 转换
基础转换(最小命令,优先验证可行性)
使用最小化参数完成转换,优先确保模型能成功生成 <font style="background-color:rgb(187,191,196);">.om</font> 文件,不追求性能优化。
(cann_env) wenwubei@ywwb:~$ atc \
--framework=5 \
--model=text_classification_bs1_seq256_sim.onnx \
--output=text_classification_bs1_seq256 \
--input_shape="input_ids:1,256" \
--soc_version=Ascend310 \
--log=info \
--mode=0
- 终端输出
<font style="background-color:rgb(187,191,196);">ATC run success, welcome to use again!</font>;
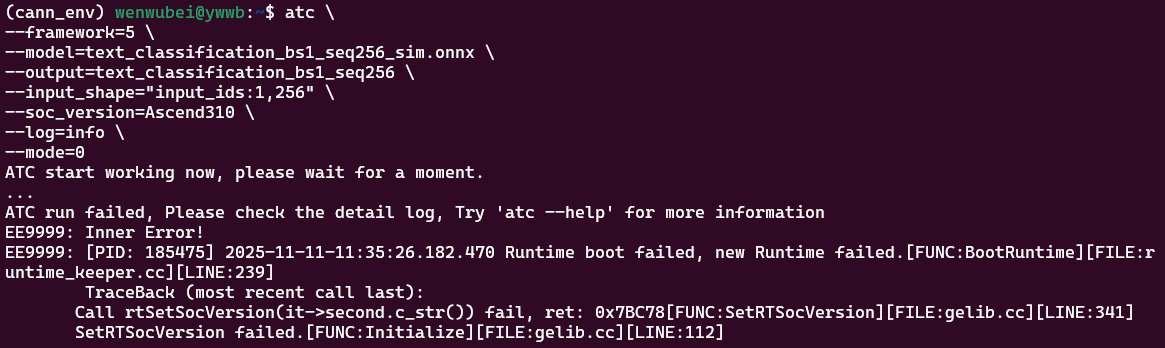
这个报错是 无 Ascend 硬件导致的 Runtime 启动失败,属于无硬件环境下的正常限制—— 你的 ATC 命令格式完全正确,ONNX 模型也合规,只是缺少 Ascend 芯片及驱动,无法完成最后的 Runtime 初始化和编译。
多输入模型转换
若模型有多个输入(如 LLM 常见的 <font style="background-color:rgb(187,191,196);">input_ids</font>+<font style="background-color:rgb(187,191,196);">attention_mask</font>+<font style="background-color:rgb(187,191,196);">position_ids</font>),需在 <font style="background-color:rgb(187,191,196);">--input_shape</font> 中显式指定所有输入的 shape。
atc \--framework=5 \--model=llm_bs1_seq512_sim.onnx \--output=llm_bs1_seq512 \--input_shape="input_ids:1,512;attention_mask:1,512;position_ids:1,512" \ # 分号分隔多个输入--soc_version=Ascend310 \--log=info \--mode=0
- 注意:输入名必须与 ONNX 导出时的
<font style="background-color:rgb(187,191,196);">input_names</font>完全一致,shape 需匹配实际输入维度。
转换后验证(确保 OM 可用)
转换成功生成 <font style="background-color:rgb(187,191,196);">.om</font> 文件后,需验证文件有效性(有硬件时执行):
用 msame 工具(有硬件且生成.om文件)
bash
# msame 工具路径(你的 CANN 安装目录)msame_path=~/miniconda3/envs/cann_env/Ascend/ascend-toolkit/8.2.RC1/tools/msame/out
# 执行推理(输入为随机生成的符合 shape 的数据)$msame_path/msame \--model=text_classification_bs1_seq256.om \--input="input_ids:1,256" \--output=./msame_output \--loop=10 # 推理 10 次,验证稳定性
- 成功标志:输出
<font style="background-color:rgb(187,191,196);">inference success</font>,且无精度异常提示。
精度比对(确保与 ONNX 结果一致)
- 用相同的测试样本,分别通过 ONNX Runtime 和
<font style="background-color:rgb(187,191,196);">msame</font>工具推理; - 比对两者输出的
<font style="background-color:rgb(187,191,196);">logits</font>结果,确保绝对误差 < 1e-3(FP16 模式)或 < 1e-5(FP32 模式)。
5. 【创新玩法】探索CANN的动态Shape能力
在前面的步骤中,我们成功将一个PyTorch模型转换为了静态Shape(input_shape="input_ids:1,256")的.om模型。这是CANN应用的基础,但在实际AI应用中,尤其是NLP领域,输入数据的Shape往往是动态变化的。
我们面临的痛点:
我们在步骤1中精心准备了imdb_short_dataset (256 tokens) 和 imdb_long_dataset (2048 tokens)。如果使用[1, 256]的静态OM模型:
- 处理短序列:完美适配。
- 处理长序列:必须截断 ,导致模型无法理解256个token之后的内容,精度严重下降。
如果当时转换的是[1, 2048]的静态OM模型:
- 处理长序列:完美适配。
- 处理短序列:必须填充至2048。这会导致
(2048 - 256) / 2048 = 87.5%的计算量被浪费在无意义的Padding数据上,性能极低。
CANN****的解决方案:
CANN ATC提供了强大的动态Shape支持,允许我们生成一个OM模型,同时高效适配不同Shape的输入,完美契合我们“短序列+长序列”的创新玩法设想。
5.1 第一步:导出支持动态维度的ONNX
要使用ATC的动态能力,首先必须从源头(PyTorch)导出支持动态轴(Dynamic Axes)的ONNX。我们修改pytorch_full_pipeline.py中的export_onnx函数。
** 关键点**:原先的dynamic_axes=None是为了保证静态转换的绝对成功率。现在,我们将其显式打开。
vim export_dynamic_onnx.py
import torch
import torch.nn as nn
import onnx
from pytorch_full_pipeline import TextClassificationModel # 导入模型
# --- 仅需修改 export_onnx 函数 ---
def export_dynamic_onnx(model):
model.eval()
# 1. 输入shape改为 [batch_size, seq_len]
# 我们使用一个 [1, 256] 的示例输入
batch_size = 1
seq_len = 256
vocab_size = 5000
dummy_input = torch.randint(0, vocab_size, (batch_size, seq_len), dtype=torch.long)
onnx_path = "text_classification_dynamic.onnx"
print("🚀 开始导出动态Shape ONNX...")
torch.onnx.export(
model,
(dummy_input,),
onnx_path,
input_names=["input_ids"],
output_names=["logits"],
opset_version=11,
do_constant_folding=True,
# --- 核心创新点:开启动态轴 ---
dynamic_axes={
"input_ids": {
0: "batch_size", # 第0维 (Batch) 设为动态
1: "sequence_length" # 第1维 (SeqLen) 设为动态
},
"logits": {
0: "batch_size" # 输出的Batch维也随输入动态变化
}
}
)
# 验证 ONNX
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(f"✅ 动态 ONNX 导出成功!路径:{onnx_path}")
print("📊 导出配置:input_ids [batch_size, sequence_length], logits [batch_size]")
if __name__ == "__main__":
# 加载已训练好的模型
try:
model = TextClassificationModel(seq_len=256) # 注意:模型结构本身是支持变长的
# 实际应用中,模型定义(如self.fc1)可能需要适配变长,
# 但我们示例中的 .view(embed.size(0), -1) 恰好与 seq_len 解耦(虽然性能不好,但演示可行)
# 更好的模型会用 [CLS] Token 或 Mean Pooling
# 为演示,我们假设模型结构已适配(或使用一个已适配动态的模型)
# 这里我们直接使用已有的权重(仅为演示导出流程)
model.load_state_dict(torch.load("text_classification_model.pth"))
export_dynamic_onnx(model)
# 别忘了简化 (可选但推荐)
# python -m onnxsim text_classification_dynamic.onnx text_classification_dynamic_sim.onnx
except Exception as e:
print(f"❌ 导出动态ONNX失败(可能需要调整模型结构以支持变长):{str(e)}")
5.2 玩法一:动态序列长度(适配短/长序列)
假设我们有了一个真正支持变长(如使用MeanPooling)的dynamic_sim.onnx。
目标:生成一个OM,batch_size=1(固定),但sequence_length可以在[1, 2048]范围内任意变化。
ATC 转换命令(动态序列):
# 确保环境变量已加载
source ~/miniconda3/envs/cann_env/Ascend/ascend-toolkit/8.2.RC1/compiler/bin/setenv.bash
atc \
--framework=5 \
--model=text_classification_dynamic_sim.onnx \
--output=model_dynamic_seq \
--input_shape="input_ids:1,-1" \ # 关键:Batch=1, SeqLen=-1 (动态)
--soc_version=Ascend310 \
--log=info \
--mode=0
- 结果:生成
model_dynamic_seq.om。这个模型可以接受[1, 256]的输入,也可以接受[1, 2048]的输入,无需重新编译。 - 分析:解决了灵活性的问题。但ATC为了支持任意长度,可能无法对我们最关心的
256和2048档位做到极致优化。
5.3 玩法二:动态序列“档位”(Gears)优化(CANN特色)
这是CANN针对变长输入的核心优化玩法。我们明确告诉ATC:我的序列长度虽然是动态的,但我最常用的“档位”是256和2048。
ATC 转换命令(档位优化):
atc \
--framework=5 \
--model=text_classification_dynamic_sim.onnx \
--output=model_dynamic_gear \
--input_shape="input_ids:1,-1" \
--soc_version=Ascend310 \
--log=info \
--mode=0 \
--dynamic_dims="256,2048" # 关键:指定我们关心的档位
- 结果:生成
model_dynamic_gear.om。 - 分析:CANN编译器会在生成OM时,特别优化
seq_len=256和seq_len=2048的计算图。当推理时输入恰好是这两个长度时,性能将接近静态模型,远超“玩法一”中的纯动态模型。这是灵活性与极致性能的完美结合。
5.4 玩法三:动态Batch(适配高吞吐服务)
在实际推理服务中,为了提高NPU利用率,我们希望一次处理多条请求,即batch_size是动态的。
目标:seq_len=256(固定),但batch_size可以在[1, 2, 4, 8]这几个档位变化。
ATC 转换命令(动态Batch):
atc \
--framework=5 \
--model=text_classification_dynamic_sim.onnx \
--output=model_dynamic_batch \
--input_shape="input_ids:-1,256" \ # 关键:Batch=-1, SeqLen=256
--soc_version=Ascend310 \
--log=info \
--mode=0 \
--dynamic_batch_size="1,2,4,8" # 关键:指定Batch档位
- 结果:生成
model_dynamic_batch.om。 - 分析:此模型在推理时,可以高效处理1、2、4、8这四种BatchSize的输入,最大化吞吐量,是CANN在推理(Inference)场景下的重磅特性。
6. 对比与应用场景分析
通过上述探索,我们从一个“静态OM”拓展出了三种“动态OM”玩法。在没有硬件的情况下,我们进行定性分析:
| 转换策略 (Strategy) | ATC 核心参数 | 适用场景 (Scenario) | 优点 (Pros) | 缺点 (Cons) |
|---|---|---|---|---|
| 1. 静态Shape | --input_shape="1,256" | 离线、固定输入(如图像) | 转换简单,性能极致优化 | 灵活性差,NLP场景浪费算力/丢失信息 |
| 2. 动态序列(纯动态) | --input_shape="1,-1" | 变长NLP输入(长度未知) | 单一模型适配多长度,灵活 | 性能低于静态,优化非最优 |
| 3. 动态序列(档位) | --input_shape="1,-1"--dynamic_dims="256,2048" | 变长NLP(档位明显) (如本文的短/长数据集) | 兼顾灵活性与性能,档内性能高 | 需提前预估数据分布 |
| 4. 动态Batch | --input_shape="-1,256"--dynamic_batch_size="1,2.." | 高吞吐推理服务 (Serving) | NPU利用率高,吞吐量大 | 时延可能抖动,内存占用增加 |



















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











