大家好,小编来为大家解答以下问题,python爬取新闻网站内容,python爬取新闻内容报告,现在让我们一起来看看吧!
Source code download: 本文相关源码
前言
🙉随机找了个网站爬爬,我们的目标是
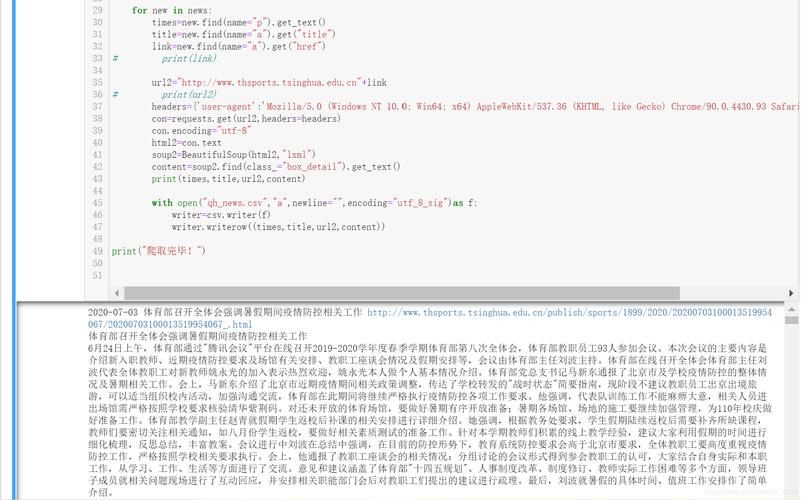
1.利用爬虫的re、xpath等知识,爬取到这个官网上的新闻,内容有:新闻标题, 发布时间, 新闻链接, 阅读次数, 新闻来源五个属性。
2.把我们爬到的数据放到一个csv的文件中!
那么我们下面开始!🌝
提示:爬虫不可用作违法活动,爬取时要设定休眠时间,不可过度爬取,造成服务器宕机,需付法律责任!!!
一、基本目标<

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+





