



配置环境:
git clone https://github.com/lksky-kong/EVSSM.git
cd EVSSM
conda env create -f environment.yml
conda activate torch2.1
首先确认GPU驱动版本是否支持CUDA 12.1
nvidia-smi
命令行输出:NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2
,表明支持CUDA 12.1。
安装好其他所有依赖:
pip install -r requirements_basicsr.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
运行bash train.sh,报错核心:ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: '/home/zkk/miniconda3/envs/torch2.1/lib/python3.10/site-packages/torch/include/ATen/ATen.h'
这表示:pip 在安装或升级 torch 时,检测到旧的 torch 残留文件夹,但其中部分核心头文件(如 ATen.h)缺失,导致安装中断。也就是说环境里 torch 没完全卸载干净,pip 在覆盖时出错。要彻底清除旧的 PyTorch 文件夹后再装。
清除删除残留的torch:
步骤 1:彻底删除残留的 torch 目录
rm -rf /home/zkk/miniconda3/envs/torch2.1/lib/python3.10/site-packages/torch*
步骤2:确认删除成功
ls /home/zkk/miniconda3/envs/torch2.1/lib/python3.10/site-packages/ | grep torch
命令行输出:functorch(没有输出,说明清理干净)
说明当前 torch 主包确实已经被清理干净,只剩下 functorch(这是 PyTorch 的一个子包,没问题,可以保留)。
安装对应的Pytorch和CUDA:
在已经安装CUDA 12.1的系统中安装对应的PyTorch,以确保能够利用GPU进行计算
pip install torch==2.1.0+cu121 torchvision==0.16.0+cu121 torchaudio==2.1.0+cu121 -i https://download.pytorch.org/whl/cu121
命令行显示:Successfully installed torch-2.1.0+cu121 torchaudio-2.1.0+cu121 torchvision-0.16.0+cu121,即成功安装。
pip install git+https://github.com/state-spaces/mamba.git@v2.2.3 --no-build-isolation
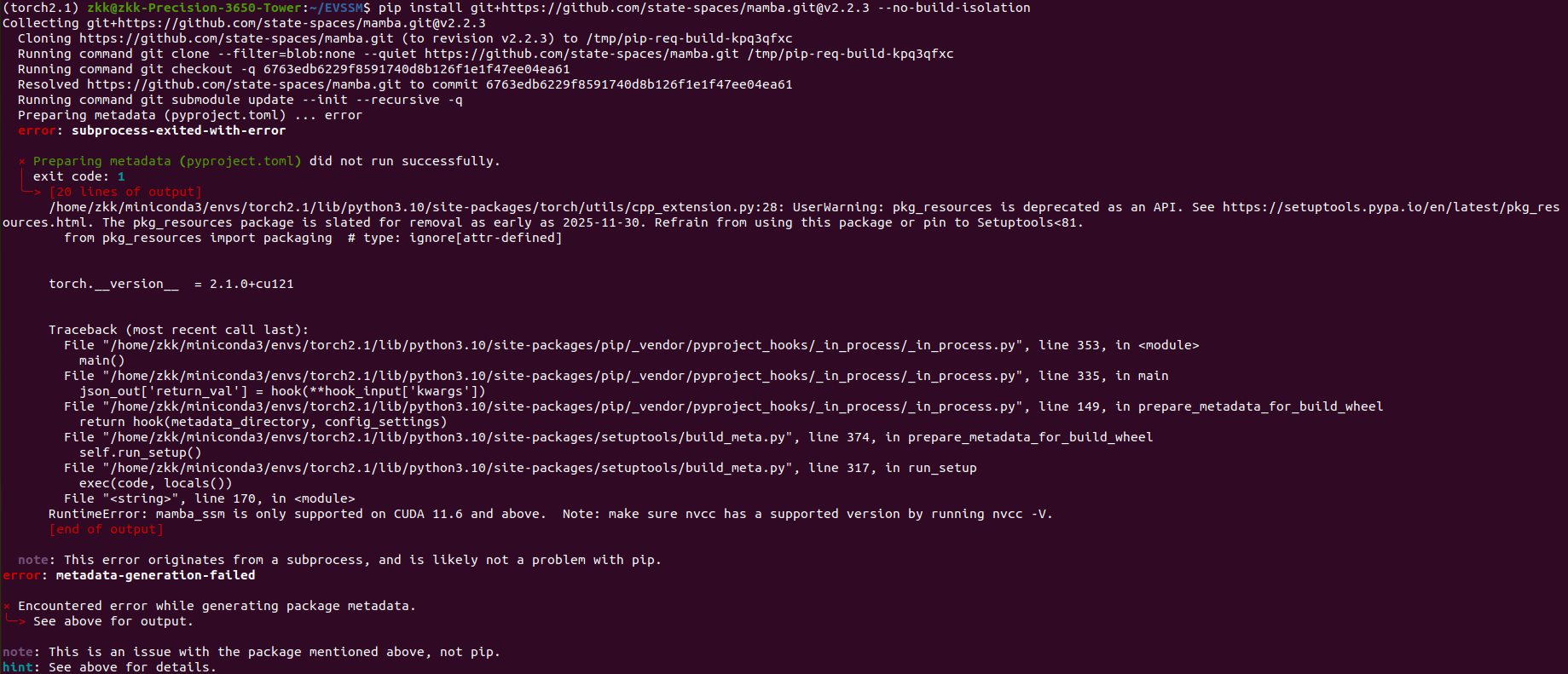
我当前CUDA 是 11.3,低于要求。虽然安装过12.1,
不同 CUDA 版本默认安装在不同路径下,系统只需要用一个“软链接” /usr/local/cuda 指向你想要使用的版本即可。
1️⃣ 添加 NVIDIA 官方 CUDA 12.1 仓库
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/3bf863cc.pub
sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
sudo apt update
2️⃣ 安装 CUDA 12.1 工具包
sudo apt install -y cuda-toolkit-12-1
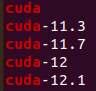
3️⃣ 查看所有 CUDA 版本
ls /usr/local | grep cuda
4️⃣ 指定当前要用的 CUDA 版本
例如:
想临时切换到 CUDA 12.1 进行编译:
sudo rm -f /usr/local/cuda
sudo ln -s /usr/local/cuda-12.1 /usr/local/cuda
如果以后想切回 CUDA 11.3:
sudo rm -f /usr/local/cuda
sudo ln -s /usr/local/cuda-11.3 /usr/local/cuda
5️⃣ 更新环境变量(建议加到 ~/.bashrc)
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
6️⃣ 验证
nvcc --version
确保输出中显示:Cuda compilation tools, release 12.1, V12.1.105
7️⃣ 重新安装 mamba-ssm
pip install "mamba-ssm==2.2.3.post2"
还是报错,错误原因不是 CUDA 版本低,而是安装时环境被误判或者缺少 numpy 等基础依赖导致构建失败。
① 清理上一次残留的构建缓存
pip cache purge
② 安装构建依赖与 numpy
在 mamba-ssm 编译时必须有 numpy 和 ninja:
pip install numpy ninja wheel setuptools cmake -U
③ 重新安装 mamba-ssm(加上显式 CUDA 版本标识)
pip install "mamba-ssm==2.2.3.post2" --no-build-isolation
仍然报错:RuntimeError: mamba_ssm is only supported on CUDA 11.6 and above.
硬件和软件环境完全满足 mamba-ssm 的要求(≥11.6)。但编译脚本检测错了 nvcc 路径,仍然认为你是旧版本(这在多版本 CUDA 并存时常见)。
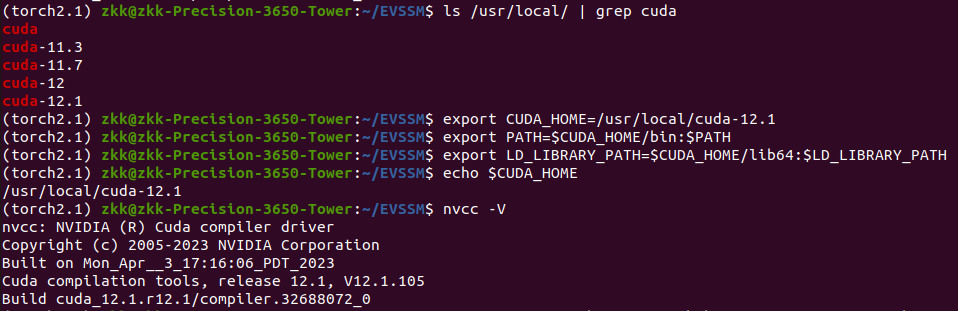
手动指定 CUDA 路径
export CUDA_HOME=/usr/local/cuda-12.1
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
确认生效(这两行输出中 CUDA_HOME=/usr/local/cuda-12.1 且 nvcc 版本仍为 12.1.105)
echo $CUDA_HOME
nvcc -V
然后,重新安装mamba_ssm
pip install git+https://github.com/state-spaces/mamba.git@v2.2.3 --no-build-isolation

运行:
python -c "import mamba_ssm; print(mamba_ssm.__version__)"
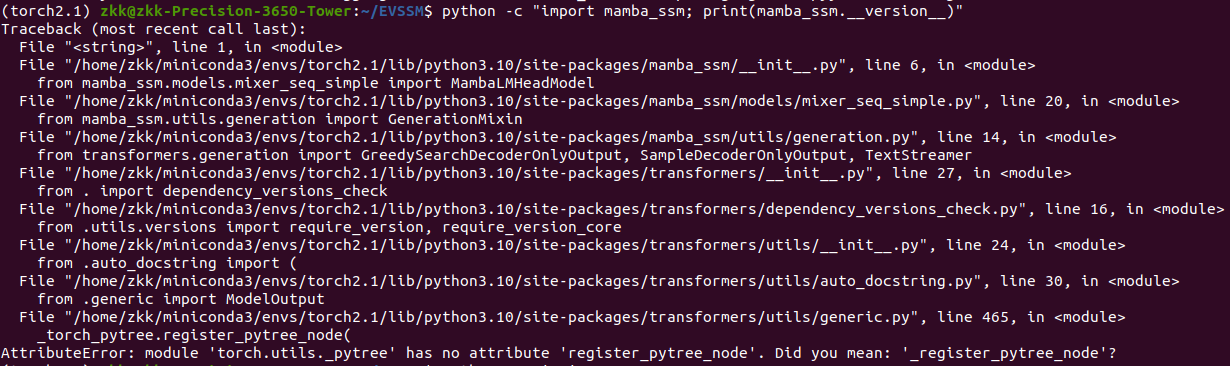
报错,PyTorch 2.1 没有公开函数 register_pytree_node,但 transformers 依赖它。手动给pytorch打补丁
python - <<'PY'
import torch.utils._pytree as pytree
if not hasattr(pytree, 'register_pytree_node'):
pytree.register_pytree_node = pytree._register_pytree_node
print("✅ Patched torch.utils._pytree.register_pytree_node successfully")
else:
print("Already has register_pytree_node")
PY
这只是运行时补丁,重启python还是会报错。
但暂时不想升级 PyTorch(怕破坏环境),于是在 sitecustomize.py 里“伪造”一个带参数的版本。
编辑:
nano ~/.local/lib/python3.10/site-packages/sitecustomize.py
改成如下内容(新的补丁版本 ):
import torch.utils._pytree as pytree
import inspect
if not hasattr(pytree, 'register_pytree_node'):
def _patched_register_pytree_node(node_type, flatten_fn, unflatten_fn, *, serialized_type_name=None, serialized_ref_fn=None):
# 忽略新参数,直接调用旧函数
return pytree._register_pytree_node(node_type, flatten_fn, unflatten_fn)
pytree.register_pytree_node = _patched_register_pytree_node
print("✅ Auto-patched pytree.register_pytree_node with new signature")
保存后重新运行,成功:
python -c "import mamba_ssm; print(mamba_ssm.__version__)"

数据预处理:
1.手动下载数据集(例如 GoPro 或 RealBlur)。
GoPro: https://seungjunnah.github.io/Datasets/gopro.html
RealBlur: https://cg.postech.ac.kr/research/realblur/
下载后,你会得到如下结构:
datasets/
├── GoPro/
│ ├── train/
│ │ ├── blur/
│ │ ├── sharp/
│ └── test/
│ ├── blur/
│ ├── sharp/
└── RealBlur/
├── train/
│ ├── blur/
│ ├── sharp/
└── test/
├── blur/
├── sharp/
2.裁剪子图(生成 subimages)
在 scripts/data_preparation/extract_subimages.py 中实现,先修改一下原代码中的路径,注释掉不需要的部分。

然后运行命令:
python scripts/data_preparation/extract_subimages.py
将每张高清图片裁成多个 480×480 小图;保证重叠 240 像素,避免边缘损失。

3.生成 meta_info 文件
在 scripts/data_preparation/generate_meta_info.py 中实现,先修改一下原代码中的路径
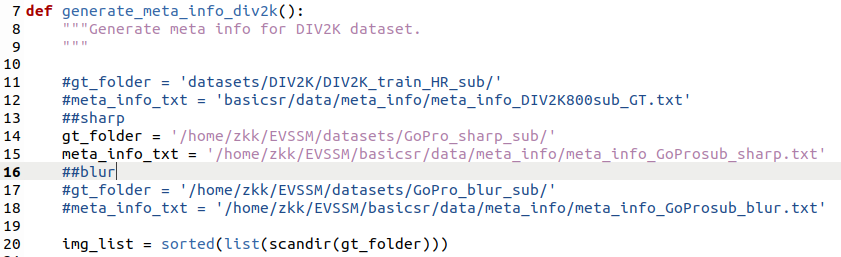
依次运行14,15行的sharp和17,18行的blur:
python scripts/data_preparation/generate_meta_info.py

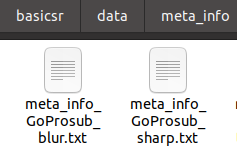
生成这两个meta_info文件:
4.生成 LMDB 数据库
在 scripts/data_preparation/create_lmdb.py 中实现,先修改一下原代码中的路径

运行:
python scripts/data_preparation/create_lmdb.py --dataset GoPro

5.配置 YAML 文件,修改GoPro.yml
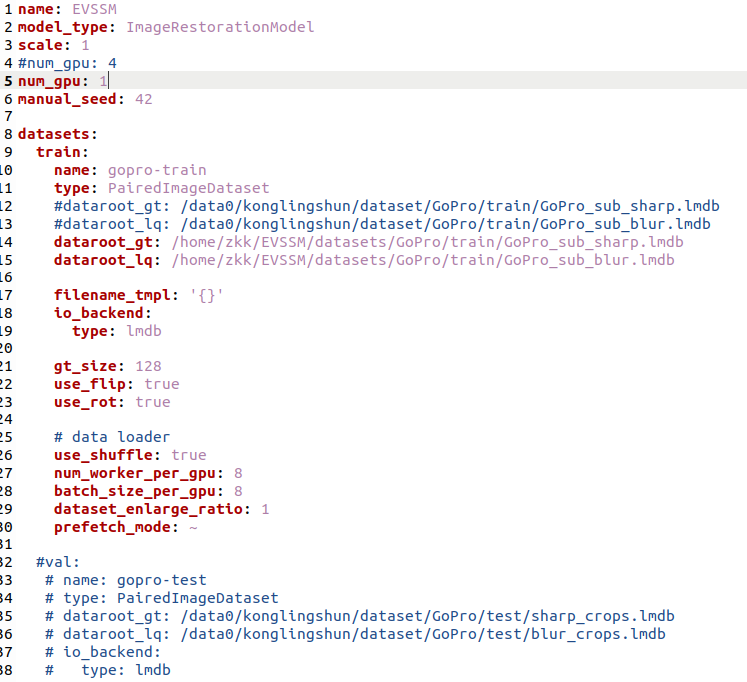
(验证集的数据处理类似。)
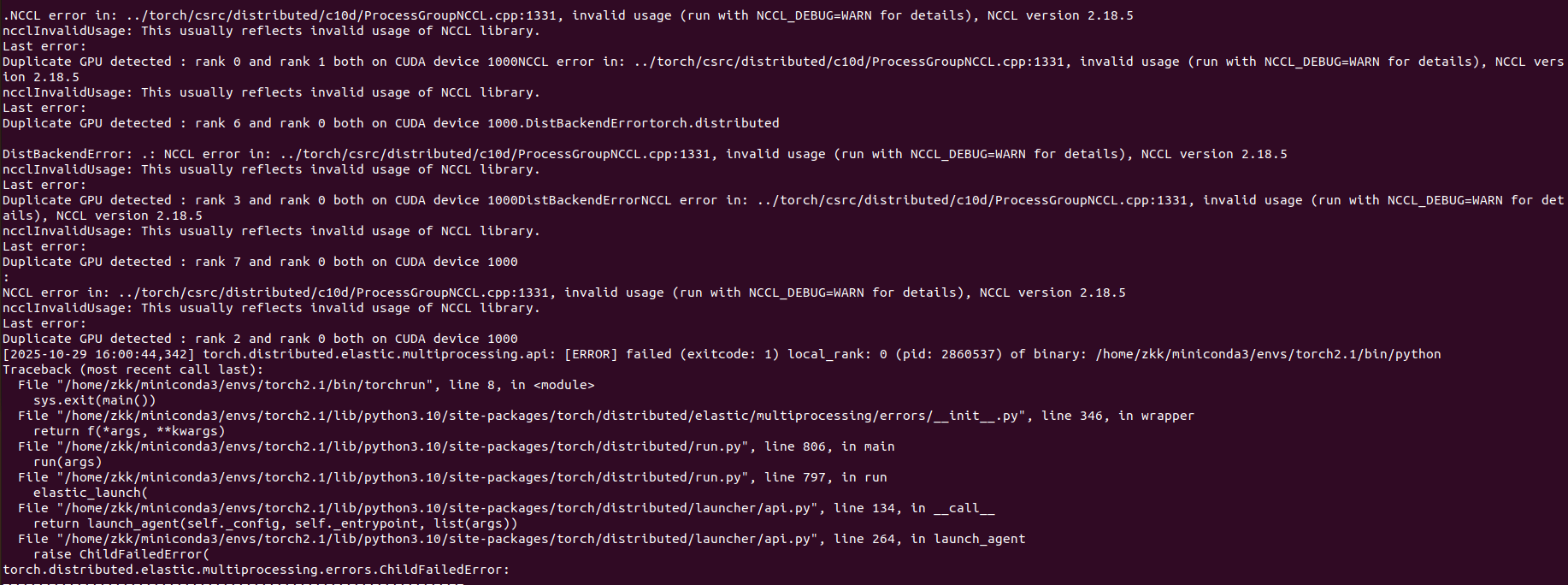
还是报错,PyTorch 认为有多个“训练进程”都在用同一个 GPU(重复设备 ID),核心问题不是代码逻辑,而是 分布式训练 (DDP) 初始化错误。
修改train.sh
vim train.sh
export NCCL_P2P_DISABLE=1
python setup.py develop --no_cuda_ext
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node=8 --master_port=4317 basicsr/train.py -opt options/train/GoPro.yml --launcher pytorch
~
在键盘上按i,进入插入模式,只修改最后一行,改成:
CUDA_VISIBLE_DEVICES=0 python basicsr/train.py -opt options/train/GoPro.yml
按 Esc 键,退出“插入模式”,回到命令模式。然后输入::wq,保存并退出。
训练:
最后,命令行输入:
bash train.sh
开始训练。


















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









