



 本文详细介绍了MyBatis中的SQL映射文件结构,包括select、insert、update、delete操作,参数传递方式(单个、多个和POJO对象),结果集映射(resultMap、association、collection),以及一级和二级缓存的工作原理和区别。
本文详细介绍了MyBatis中的SQL映射文件结构,包括select、insert、update、delete操作,参数传递方式(单个、多个和POJO对象),结果集映射(resultMap、association、collection),以及一级和二级缓存的工作原理和区别。
SQL映射文件
一、 SQL 映射文件主要元素
-
- <select>:用于执行查询操作。
<select id="getUserAndRole" resultMap="userAndRole"> select * from `user` </select> - <insert>:用于执行插入操作。
<insert id="insertAirinfo" parameterType="pojo.Airinfo"> INSERT INTO `airinfo` ( `flight_number`, `destination`, `filght_date`) VALUES (#{flightNumber},#{destination},#{filghtDate}) </insert> - <update>:用于执行更新操作。
<update id="updateAirinfo"> UPDATE `airinfo` SET `flight_number` =#{flightNumber}, `destination` = #{destination}, `filght_date` =#{filghtDate} WHERE `id` =#{id}; </update> - <delete>:用于执行删除操作。
<delete id="deleteAirinfo" parameterType="java.lang.Integer"> delete from airinfo where id=#{id} </delete> - <sql>:用于定义可重用的SQL片段。
<sql id="publicSQL"> select * from user </sql> - <resultMp>:用于定义结果集的映射关系。
<!--多表联查--> <resultMap id="userAndRole" type="pojo.User"> <id property="id" column="id"></id> <result property="userName" column="userName"/> <collection property="Role" javaType="pojo.Role"> <result property="roleName" column="roleName"/> </collection> </resultMap> - <parameterMap>:已过时,不推荐使用。
<parameterMap id="userMap" type="java.util.Map"> <parameter property="id" jdbcType="INTEGER" mode="IN" /> <parameter property="name" jdbcType="VARCHAR" mode="IN" /> </parameterMap> <select id="getUserList" parameterMap="userMap" resultType="User"> SELECT * FROM user WHERE id = #{id} AND name = #{name} </select> - <cache-ref>:用于引用其他命名空间中的缓存配置。
- <resultType>:用于指定结果集的返回类型。
- <parameterType>:用于指定参数的类型。
- <select>:用于执行查询操作。
二、参数传递
1)单个参数传递:
1、使用#{}占位符来引用参数;
2、使用@Param注解来指定参数名称。
public interface UserMapper {
User getUserById(Integer id);
}
// 使用#{}
@Select("SELECT * FROM user WHERE id = #{id}")
User getUserById(Integer id);
// 使用@Param
@Select("SELECT * FROM user WHERE id = #{userId}")
User getUserById(@Param("userId") Integer id);
2)多个参数传递:
1、使用#{}占位符来引用参数,参数会按顺序进行绑定;
2、使用@Param注解来指定参数名称,参数会按名称进行绑定;
3、使用Map或@Param注解的组合来传递多个参数。
public interface UserMapper {
List<User> getUsersByAgeAndGender(Integer age, String gender);
}
// 使用#{}
@Select("SELECT * FROM user WHERE age = #{0} AND gender = #{1}")
List<User> getUsersByAgeAndGender(Integer age, String gender);
// 使用@Param
@Select("SELECT * FROM user WHERE age = #{age} AND gender = #{gender}")
List<User> getUsersByAgeAndGender(@Param("age") Integer age, @Param("gender") String gender);
// 使用Map
@Select("SELECT * FROM user WHERE age = #{age} AND gender = #{gender}")
List<User> getUsersByAgeAndGender(Map<String, Object> params);
3)使用POJO类作为参数对象:
将多个参数封装为一个Java对象,然后将该对象作为方法的参数传入。
//接口
public interface UserMapper {
List<User> getUsersByAgeAndUsername(User user);
}
//xml
<mapper namespace="com.example.UserMapper">
<select id="getUsersByAgeAndUsername" resultType="User">
SELECT * FROM user
WHERE age = #{age} AND username = #{username}
</select>
</mapper>
//test
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = new User();
user.setAge(25);
user.setUsername("john");
List<User> userList = userMapper.getUsersByAgeAndUsername(user);
三、结果映射
1)resultMap
resultMap描述如何将结果集映射到Java对象
resultMap元素的属性:
id:resultMap的唯一标识
type:映射的结果类型
resultMap元素的子元素:
id:指定和数据表主键字段对应的标识属性(设置此项可提高MyBatis性能)
result:指定结果集字段和实体类属性的映射关系
association:映射“多对一”或“一对一”关系
collection:映射“一对多”关系
2)association
复杂的关联类型,映射一个嵌套JavaBean属性 ,多对一或一对一
属性:
property:用来映射查询结果子集的实体属性
javaType:完整Java类名或者别名
resultMap:引用外部resultMap
子元素: id ,result
3)collection
复杂类型集合,映射嵌套结果集到一个列表 一对多
属性:
property:实体类中用来映射查询结果子集的集合属性
ofType:集合中元素的类型,完整Java类名或者别名
resultMap:引用外部resultMap
子元素 :id ,result
4)resultType与resultMap
resultType :直接表示返回类型 ,适用于比较简单直接的数据封装场景
resultMap :是对外部resultMap的引用 ,能够处理结果集字段名与实体类属性名不一致、或者需要对连接查询结果使用嵌套映射等较为复杂的问题
二者本质上都是基于Map数据结构,不能同时使用
5)resultMap自动映射行为
自动映射的前提:属性名与字段名一致
自动映射级别:autoMappingBehavior
<settings>
<setting name="autoMappingBehavior"
value="[ NONE | PARTIAL | FULL ]" />
</settings>
|
自动映射行为 |
resultType (不支持嵌套映射) |
没有嵌套映射的resultMap |
有嵌套映射的resultMap |
|
NONE |
失效 |
手工映射 |
手工映射 |
|
PARTIAL |
自动映射 |
自动映射 |
手工映射 |
|
FULL |
自动映射 |
自动映射 |
自动映射 |
四、MyBatis缓存
1)一级缓存
一级缓存是基于 PerpetualCache(MyBatis自带)的 HashMap 本地缓存,作用范围为 session 域内。当 session flush(刷新)或者 close(关闭)之后,该 session 中所有的 cache(缓存)就会被清空。
在参数和 SQL 完全一样的情况下,我们使用同一个 SqlSession 对象调用同一个 mapper 的方法,往往只执行一次 SQL。因为使用 SqlSession 第一次查询后,MyBatis 会将其放在缓存中,再次查询时,如果没有刷新,并且缓存没有超时的情况下,SqlSession 会取出当前缓存的数据,而不会再次发送 SQL 到数据库。
由于 SqlSession 是相互隔离的,所以如果你使用不同的 SqlSession 对象,即使调用相同的 Mapper、参数和方法,MyBatis 还是会再次发送 SQL 到数据库执行,返回结果。
每一个 SqlSession 的内部都会有一个一级缓存对象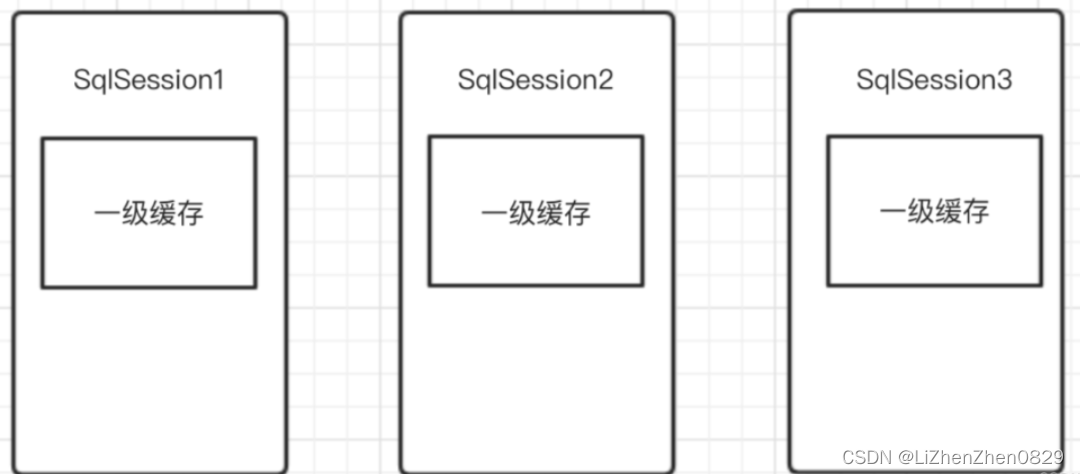
工作流程:
常见术语:
命中:需要的数据在缓存中找到结果
未命中:需要的数据在缓存中没有找到结果
流程:
1、对于某个 Select Statement,根据该 Statement 生成 key;
2、判断在Local Cache中,该key是否用对应的数据存在;
3、如果命中,则跳过查询数据库,继续往下走;
4、如果没命中,去数据库中查询数据,得到查询结果;
5、将key和查询到的结果作为 key 和value,放入Local Cache 中;
6、将查询结果返回
7、判断缓存级别是否为 STATEMENT级别,如果是的话,清空本地缓存;
测试类部分代码
SqlSession sqlSession = DaoUtil.getSqlSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student s1 = mapper.FindStudentBySid(4);
System.out.println(s1);
StudentMapper mapper1 = sqlSession.getMapper(StudentMapper.class);
Student s2 = mapper.FindStudentBySid(4);
System.out.println(s2);
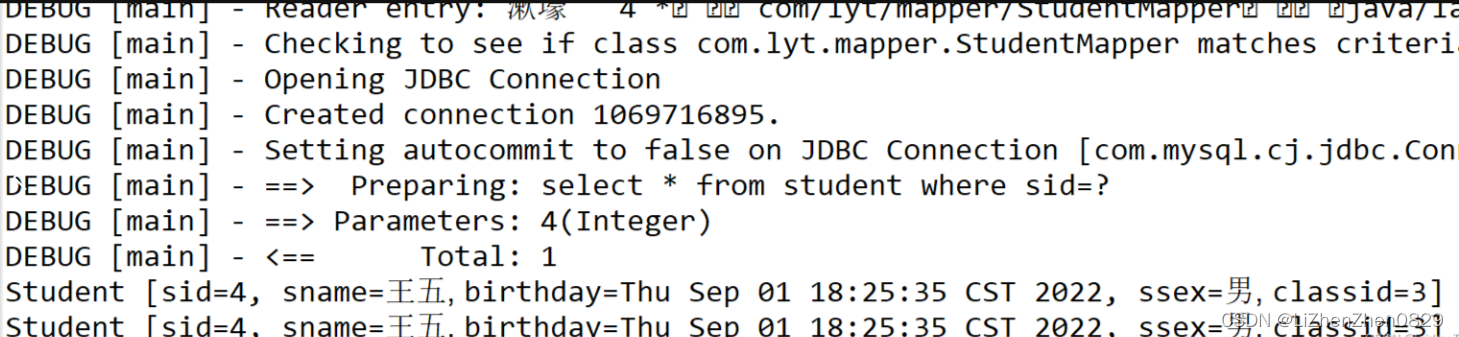
可以看出我们创建两个mapper对象,分别调用了根据学号查找学生的方法,但是结果显示只查询了一次,第一查询之后将结果放在了缓存中,所以第二次再次调用同样的方法,就会直接去内存中找,如果有,就直接输出结果。
2)二级缓存
二级缓存的配置
1)MyBatis的全局cache配置
<settings>
<setting name="cacheEnabled" value="true" />
</settings>
2)在SQL映射文件中设置缓存,默认情况下是没有开启缓存的
<cache eviction="FIFO" flushInterval="60000"
size="512" readOnly="true" />
3)在SQL映射文件配置支持cache后,如果需要对个别查询进行调整,可以单独设置
<select id="selectAll" resultType="SysUser"
useCache="true">
……
工作原理
底层是 HashMap 架构,二级缓存的作用域只在mapper级别的,也就是说无论你有多少个sqlSession去访问这个mapper,都会从缓存中获取到已有的数据mapper 对应的也就是 namespace,所以二级缓存是按照 namespace 进行区分的,如果两个 mapper 文件的 namespace 相同,那么这两个 mapper 中查出来的数据都会存在在这个 namespace 中
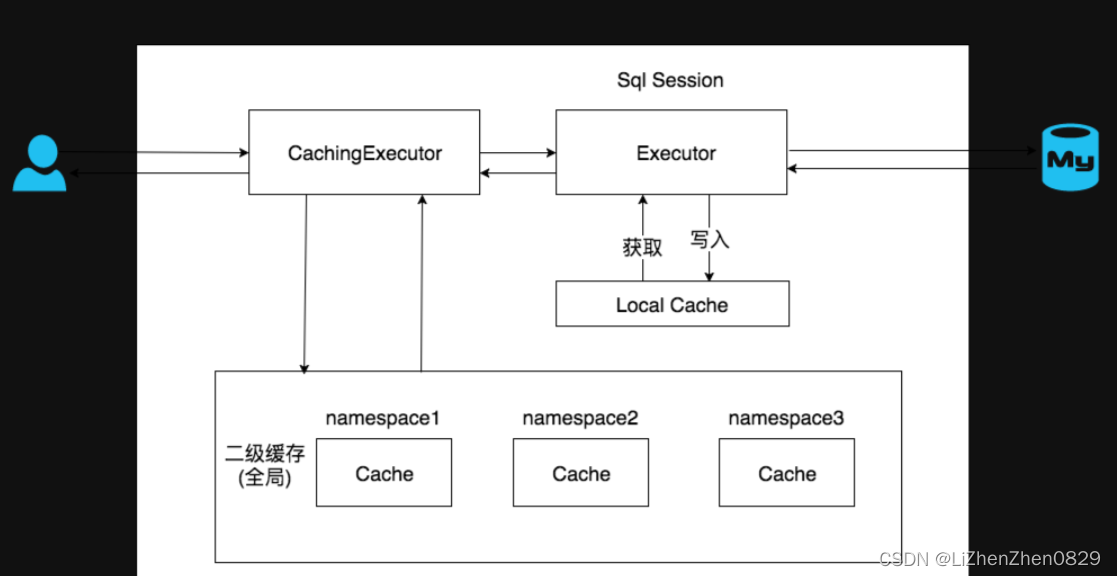
3)二级缓存和一级缓存的区别
- 一级是session级别的,二级是sessionFactory级别的
- 工作原理不同,二级缓存是直接将数据反序列化到磁盘上,而一级缓存,访问同一个对象时,不用再去访问数据库
- 二级缓存实现了缓存数据的共享,可控性更强,但容易出现错误数据,不推荐使用
总结:mybatis的一级缓存是SqlSession级别的缓存,一级缓存缓存的是对象,当SqlSession提交、关闭以及其他的更新数据库的操作发生后,一级缓存就会清空。二级缓存SqlSessionFactory级别的缓存,同一个SqlSessionFactory产生的SqlSession都共享一个二级缓存,二级缓存中存储的是数据,当命中二级缓存时,通过存储的数据构造对象返回。查询数据的时候,查询的流程是二级缓存>一级缓存>数据库


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









