




 本文探讨了反爬虫技术中资源注册延迟生效的方法,及其如何增加爬虫开发难度。同时,介绍了爬虫方如何通过分池使用注册信息策略,实现在特定时间后有效抓取数据,绕过反爬机制。
本文探讨了反爬虫技术中资源注册延迟生效的方法,及其如何增加爬虫开发难度。同时,介绍了爬虫方如何通过分池使用注册信息策略,实现在特定时间后有效抓取数据,绕过反爬机制。
1 背景
爬虫在数据抓取时会先破解APP或PC上的数据请求流程。为了防御这种爬虫,通常在APP或PC页面上附带有指纹收集与设备注册的请求。只有指纹属于正常设备或注册信息发送后才能正常访问数据。否则请求方收到的就是虚假数据。作为反爬方,目标就是就要增加爬虫开发者的破解及开发难度。因此使用资源延迟是一种干扰爬虫开发者的有效手段。
2 资源注册延迟生效
在APP启动或PC页面打开时,会向后台发送设备或浏览器信息。爬虫开发者为了破解会模拟这些请求的发送。为了增加爬虫开发者时间,可以在系统中增加上传信息延迟生效的功能。即收到APP或PC上报信息后,只有过了指定的时间才让注册信息生效。在指定时间之前抓取者尝试访问或测试收到的均是虚假数据。而对于登陆用户熟客则不设置这种限制。这样增加爬虫开发与测试的时间消耗。
3 注册信息延迟生效的应对
爬虫方为了处理这种上报信息在一段事件后才生效的情况,可以采用延迟生使用注册信息的功能来解决。
例如,抓取APP数据,需要预先请求APP的ID生成与注册接口。拿到ID后过了一段时间,使用这些ID才能抓取真实数据。
首先假定ID生效需要等待10分钟,那么使用如下方式绕过。
- 准备两个ID池
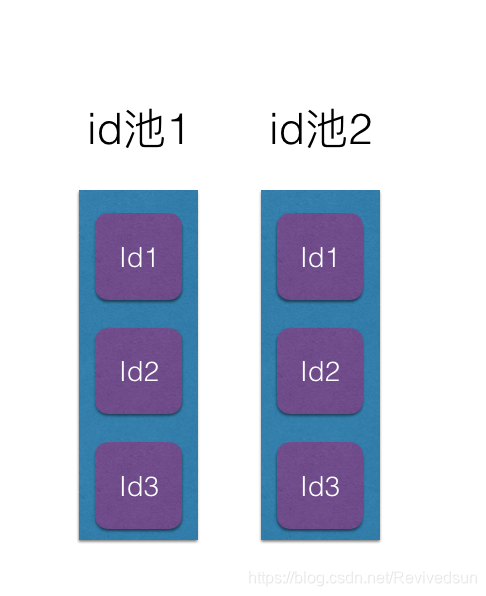
- 每10分钟内,仅使用一个ID池内的数据。此时定时任务则对未使用的ID池数据进行补充。经过一到两轮预热,此后使用的ID均是10分钟前注册的ID。
具体实现
当前使用ID池索引 = (系统运行分钟/10)%2
定时任务待补充的ID索引 = {ID1索引,ID2索引} - {当前使用ID索引}
确定好这两个值,定时任务和爬虫任务分别选择使用即可。
时间段就是选择一个总时间,然后若干段,每段10分钟,每过一段切换一次。
ID结构:
class ID {
private String value;
/**
* 已使用次数
*/
private int usedTimes;
/**
* 最大使用次数
*/
private Integer max;
/**
* 单位毫秒
*/
private long lastUpdateTime;
}
定时器ID补充生成:
每次生成ID时,设定好ID的最大使用次数。在使用时更新已使用次数。当已使用次数超过最大使用次数,则将这个ID丢弃,不再使用。
if(usedTimes > max) {
丢弃
}
定时器补充时需要检查当前剩余可使用次数是否小于可用次数阈值。当小于时,才会去补充新的ID,并更新剩余可用次数。
剩余可用次数 = ID1使用次数 + ID2使用次数 + ......+ IDn使用次数
当每使用一次ID,剩余可用次数减1。由于ID内部记录了ID最大使用次数。当调整可用次数阈值阈值,剩余可用次数不受影响,无需重新计算。
剩余可用次数可以存储在redis或db中。在redis中批量操作可以通过pipeline来完成。
4 总结
通过分池使用的方式,配置好每个池子的切换时间即可在任意时间间隔后使用注册数据。这样就可以绕过这种反爬场景。

















 1858
1858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









