



企业在数字化转型过程中,会面临数据孤岛及格式异构的双重挑战。传统方法处理JSON、XML、CSV等数十种混合格式时,常受限于解析效率低、转换逻辑复杂及数据质量参差等问题。而ETL工具凭借系统化数据治理能力,正成为数据资产化转型的关键技术。
一、ETL实现的文件格式处理过程
从技术架构看,现代ETL工具通过三阶段机制实现高效处理:
抽取阶段:内置解析引擎支持超200种格式自动识别,包括通过正则表达式解析非结构化日志、XSD Schema验证XML结构完整性,以及处理多层嵌套JSON数据。
转换阶段:基于元数据驱动的框架支持150余种操作,如字段映射、数据清洗及类型转换,例如将Excel日期统一为ISO标准,或利用机器学习修复CSV缺失值。
加载阶段:通过并行写入技术实现毫秒级延迟,确保数据以高时效性写入关系型数据库、数据仓库或大数据平台。
该架构通过标准化流程与自动化技术,系统性解决异构数据治理难题,支撑企业数据资产化战略落地。
二、复杂文件格式处理的痛点
-
数据多样性:企业日常运营中会产生大量不同类型的文件,如 Excel、CSV、JSON、XML 等,这些文件的结构和格式各有不同,数据存储方式也千差万别,给统一处理带来了很大困难。
-
数据关联复杂:多个文件之间可能存在关联关系,需要进行数据整合和关联分析,但手动处理这些复杂关联费时费力且易出错。
三、ETL工具一站式解决复杂文件格式处理问题
1.创建离线同步流程
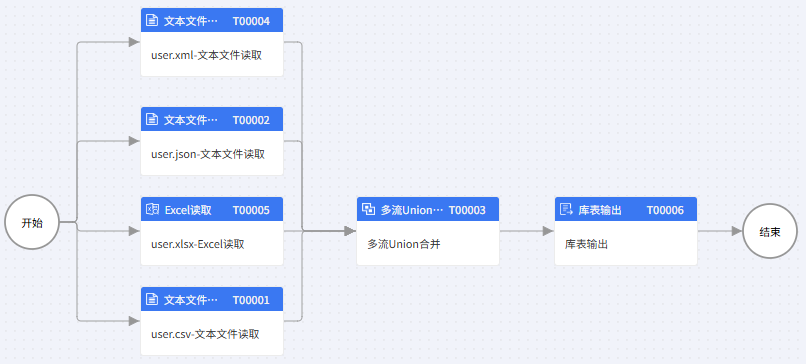
user.xml-文本文件读取配置:
基本属性
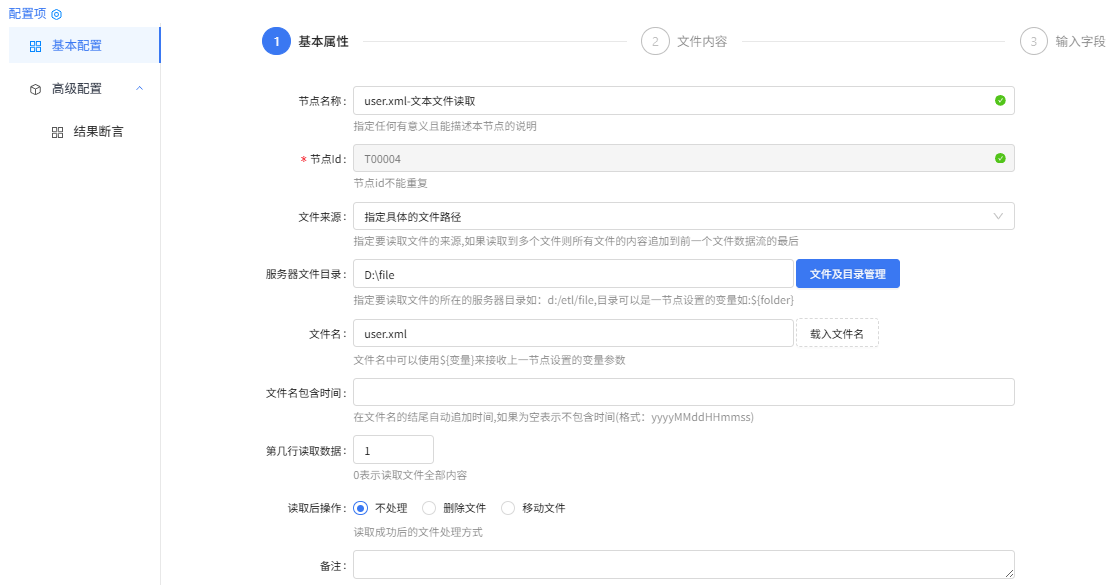
文件内容
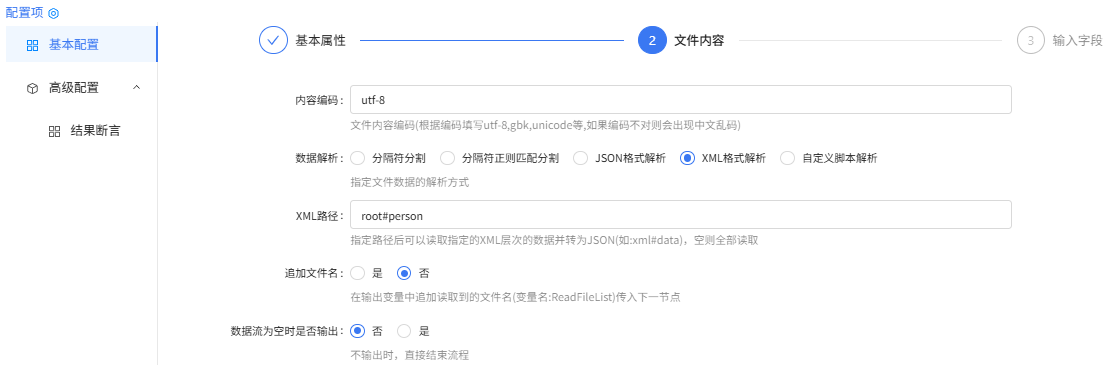
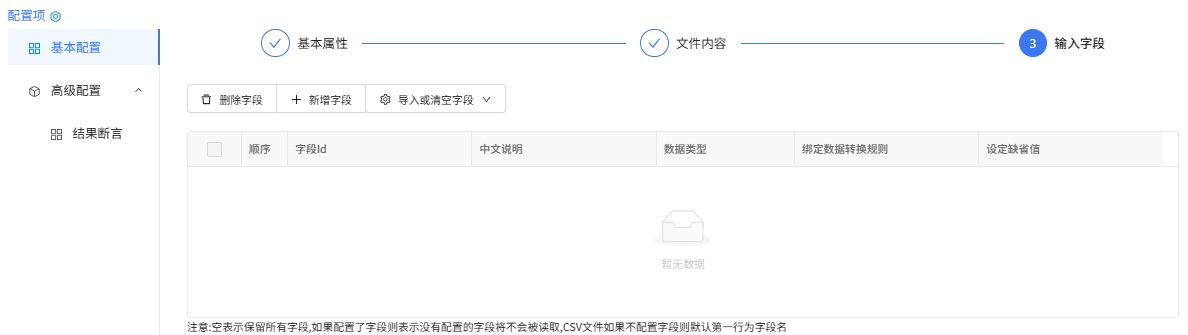
输入字段
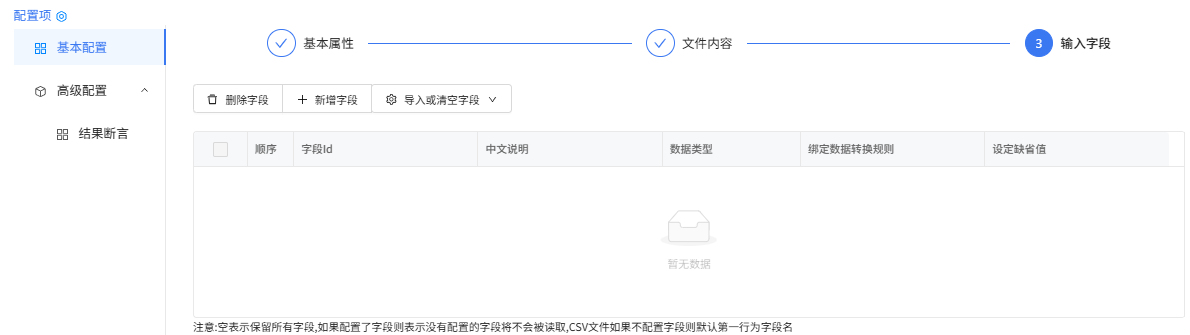
user.json-文本文件读取组件配置:
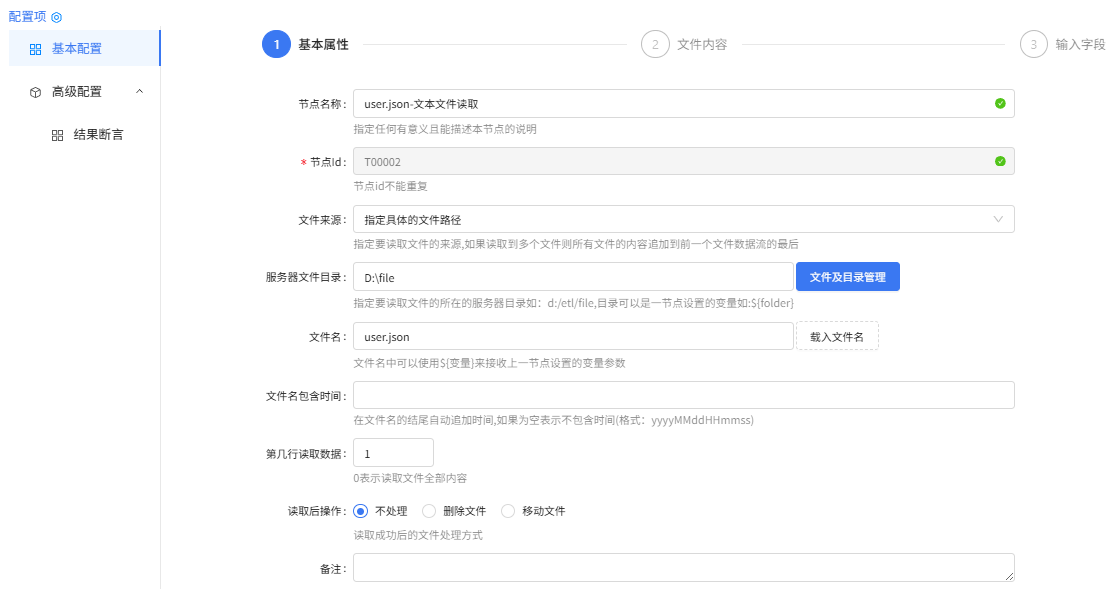
文件内容
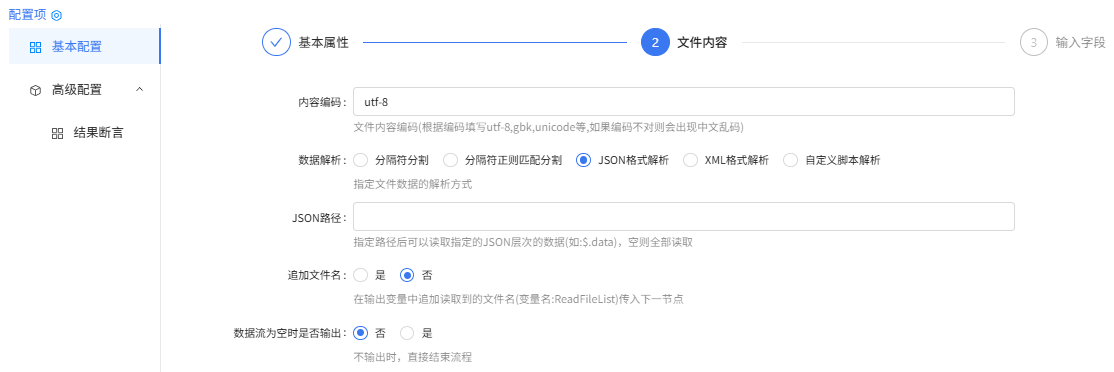
输入字段
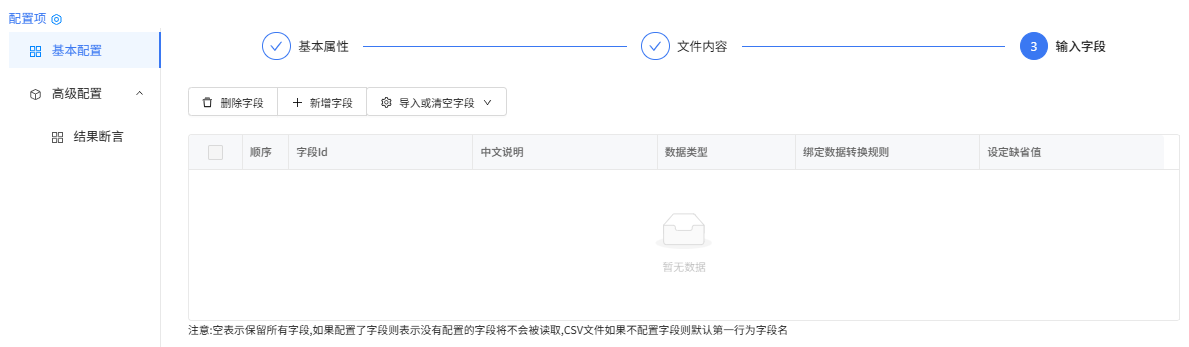
user.xlsx-Excel读取组件配置:
基本属性
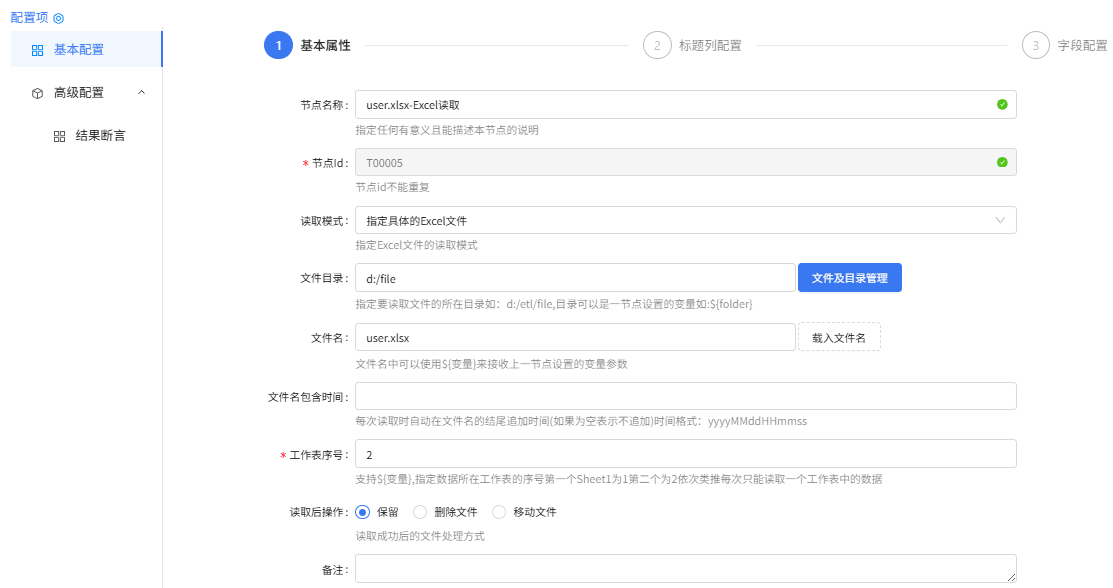
标题列配置
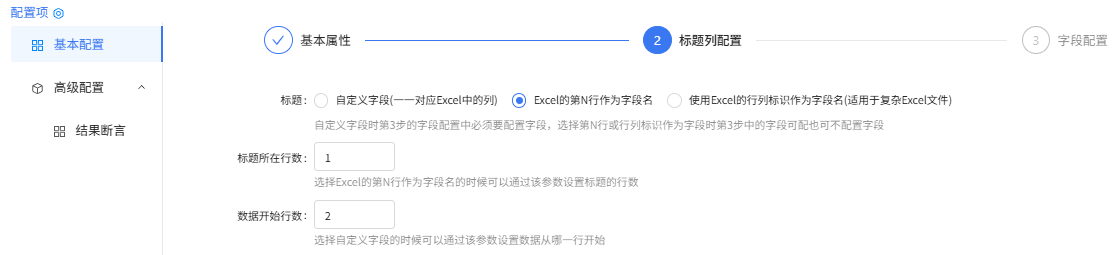
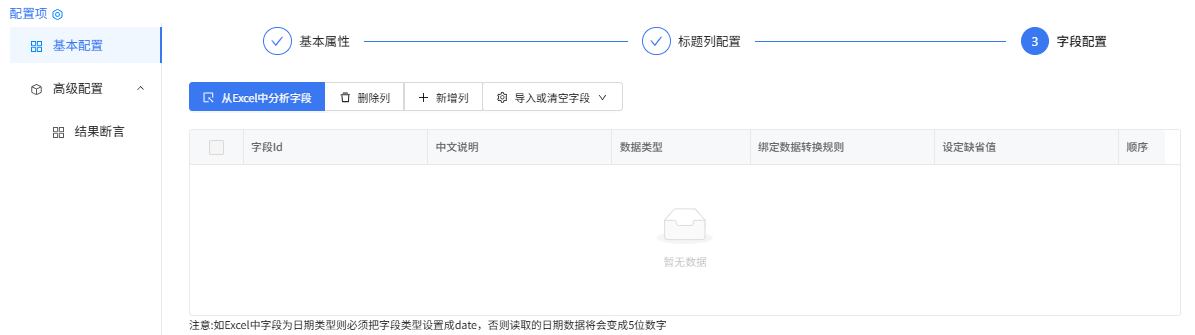
字段配置
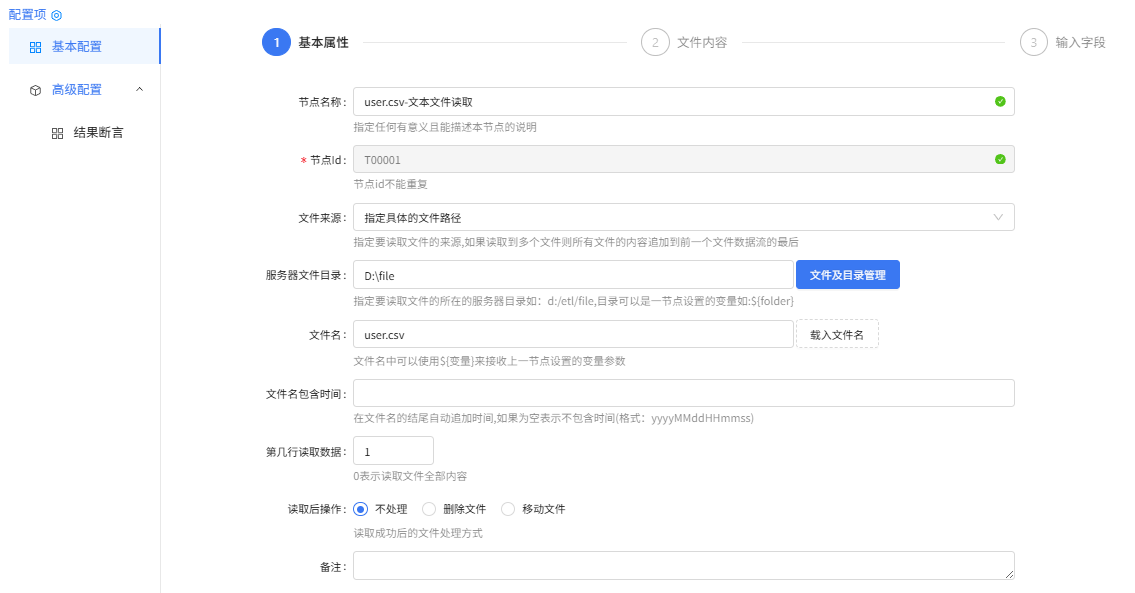
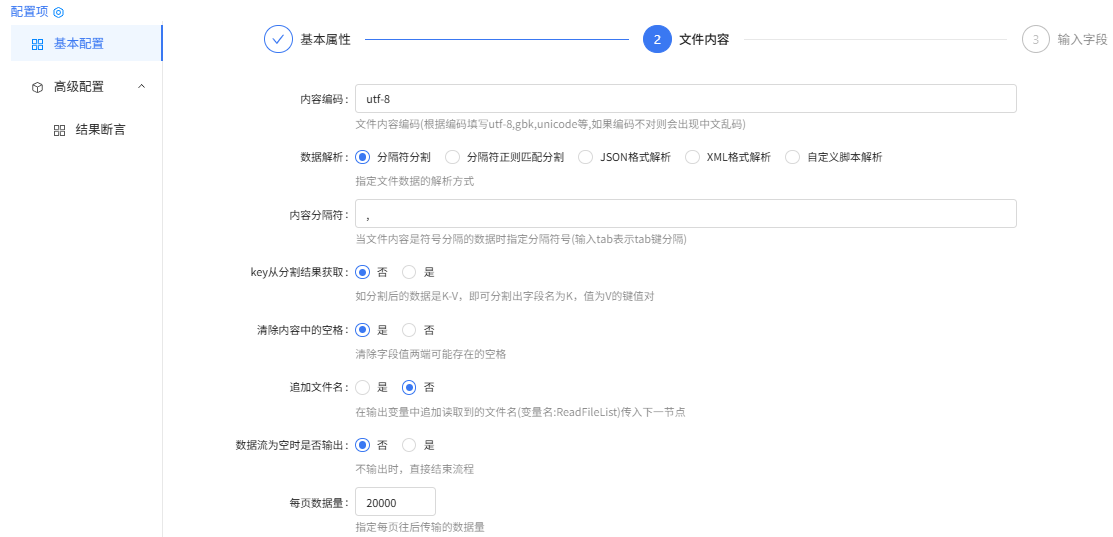
user.csv-文本文件读取配置:
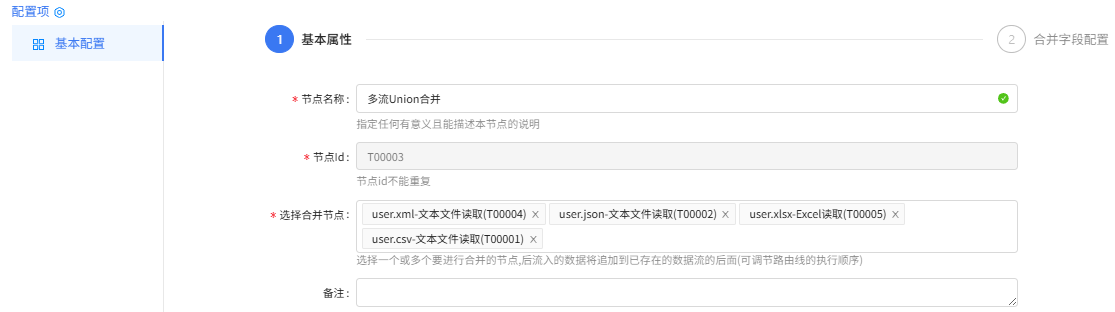
多流Union合并配置
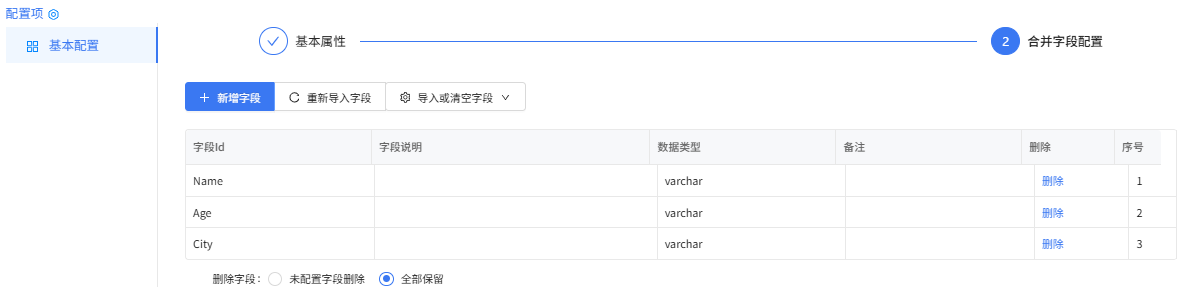
合并字段配置
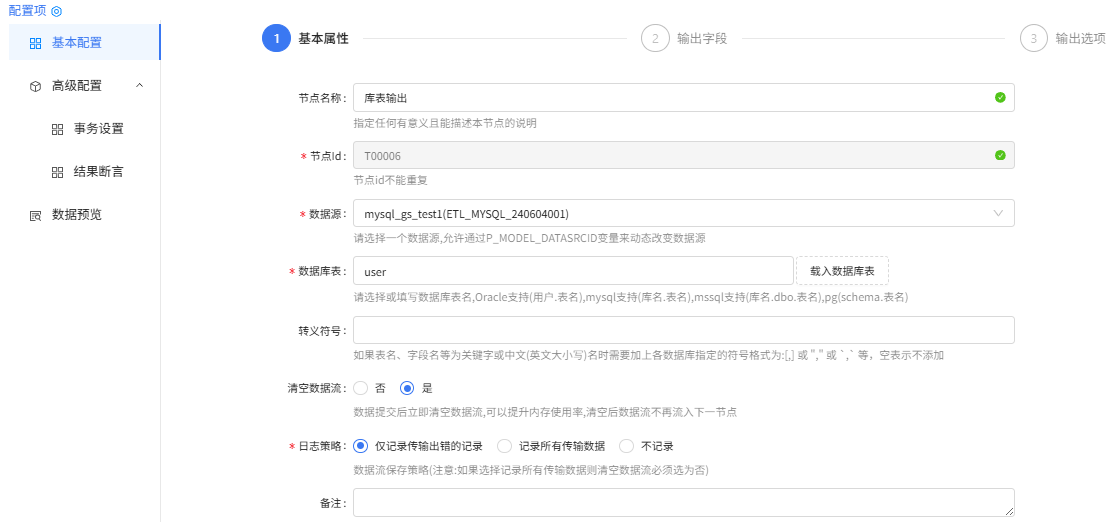
库表输出配置
基本属性
输出字段
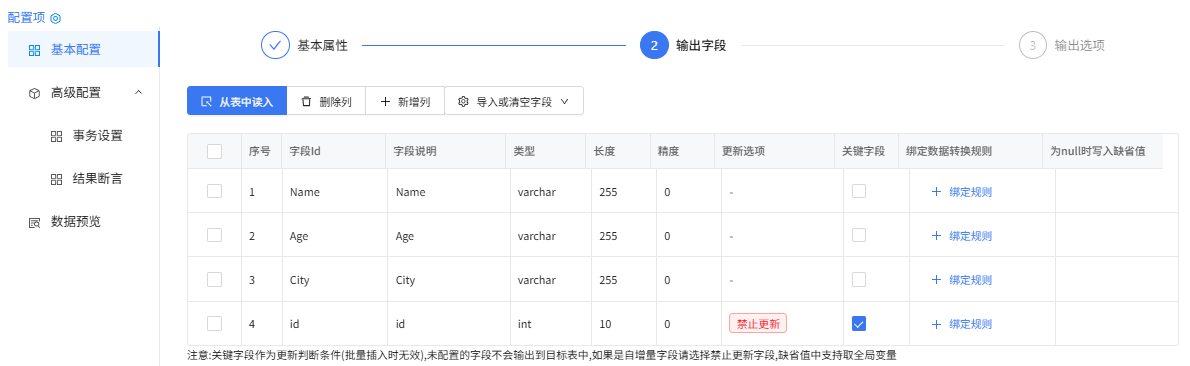
输出选项
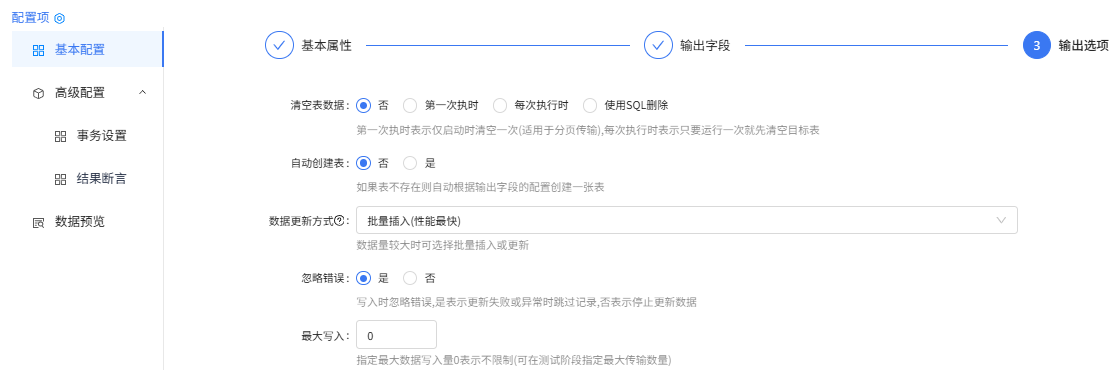
2.运行流程
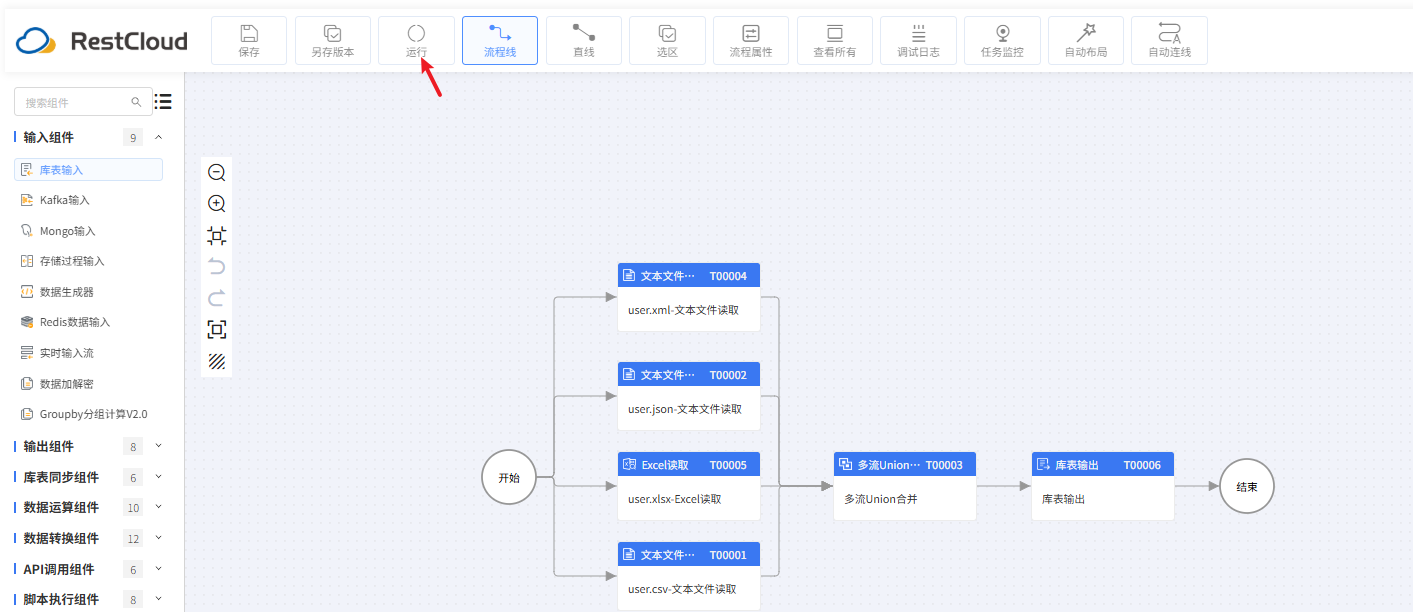
流程监控
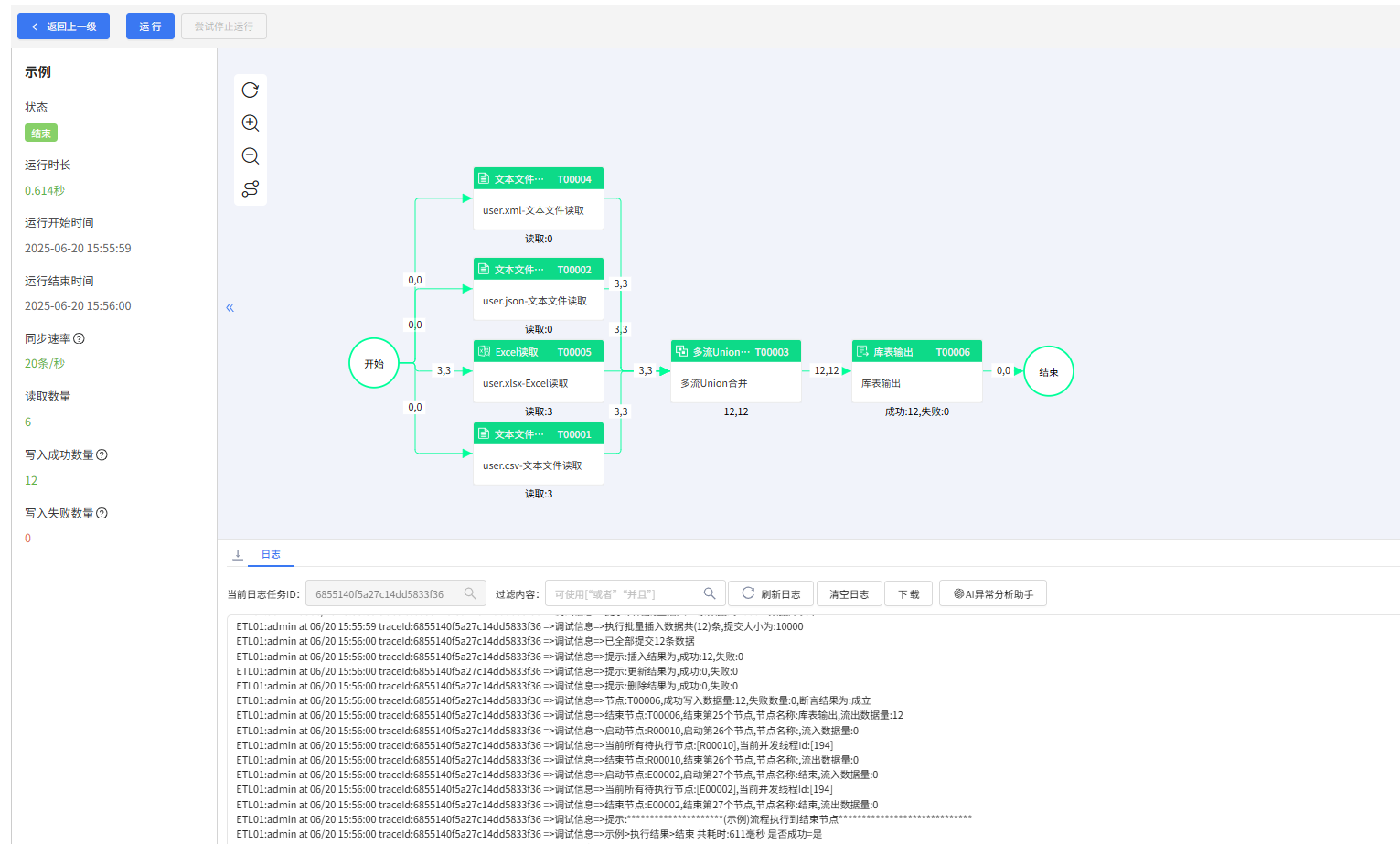
查看源数据:
user.csv文件数据
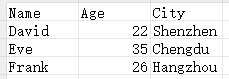
user.json文件数据

user.xlsx文件数据
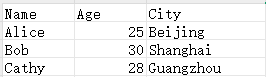
user.xml文件数据

库表输出user表数据
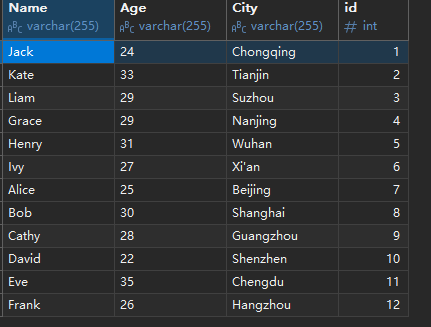
四、最后
除了借助ETL工具实现文件格式处理外,我们还能通过其他不同的方式,但在高速发展的时代下,我们应该选择更高效的数据处理工具来提升企业的数据集成效率。同时随着数据量的不断增长和数据复杂性的提升,数据处理方法和工具也会有不断创新和演进。后续我们可能会看到更多不同的数据处理方式或ETL工具,这些方法将帮助我们企业更好的提升智能化、自动化,能够处理更复杂、更海量的数据,助力企业在数字化浪潮中脱颖而出。

















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









