




在探讨多源异构数据融合的过程中,除了上篇介绍的通过Union方式实现的数据整合之外,Join操作同样是一种非常重要的手段。如果说Union是从横向角度将不同来源但结构相似的数据集合起来的话,那么Join则是从纵向的角度出发,基于特定条件将来自不同源头且可能存在关联关系的数据表连接起来,从而形成更加丰富、全面的信息集。这种方式特别适用于那些虽然分布在多个数据库或文件中但内在存在着一定联系的数据集之间。
一、多源异构数据融合的难点
多源异构数据在不同数据源之间在格式、结构和语义上都有着差异,使得数据整合变得复杂;多样性则意味着数据类型丰富,处理和分析需要针对不同类型数据采取不同的技术和方法;在融合这些多源异构数据时,面临的主要挑战包括数据标准化困难、数据质量问题、语义差异和处理复杂性。由于不同数据源缺乏统一的标准,导致在比较和融合时可能出现不一致;此外,数据的准确性和完整性也可能因来源不同而受到影响,进而影响分析结果的可靠性。语义差异则指同一概念在不同数据源中的不同定义和表达方式,这使得数据的集成和理解更加复杂。最后,处理多源异构数据所需的计算资源和技术能力也相对较高,需要采用复杂的算法和系统架构,这进一步增加了数据融合的难度。因此,在实际应用中,实现高效、准确的多源异构数据融合仍然是一个亟待解决的挑战。
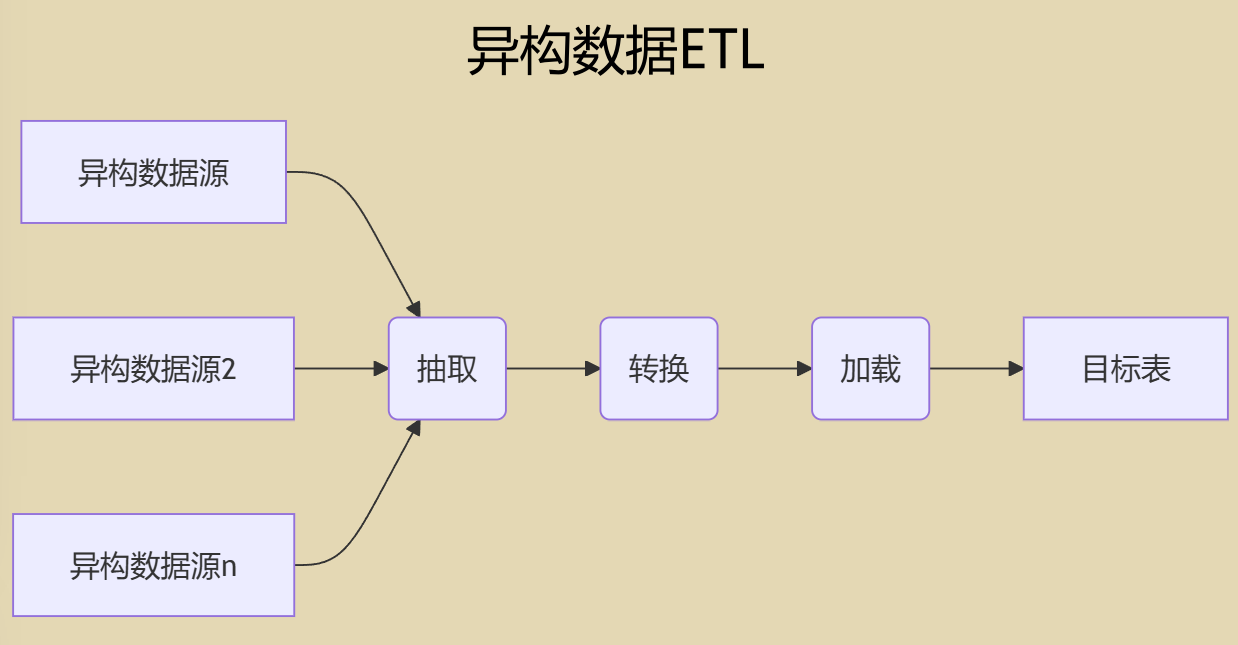
二、如何进行多源异构数据源融合
多源异构数据源融合就是对数据进行ETL的过程。从多个多源异构数据源中抽取出数据,经过一系列转换操作,再加载到目标数据源,就完成了多源异构数据源融合。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









