




 本文详细探讨了消息队列在解耦、异步、削峰等场景的应用,阐述了生产者-消费者模式,以及如何在RabbitMQ、Kafka、RocketMQ中保证消息顺序消费。同时,分析了消息队列如何防止消息丢失,提出RabbitMQ和Kafka在确保消息顺序和避免重复消费方面的策略。最后,讨论了MQ的推拉模式、RabbitMQ与Kafka的区别以及Kafka的高性能原因。
本文详细探讨了消息队列在解耦、异步、削峰等场景的应用,阐述了生产者-消费者模式,以及如何在RabbitMQ、Kafka、RocketMQ中保证消息顺序消费。同时,分析了消息队列如何防止消息丢失,提出RabbitMQ和Kafka在确保消息顺序和避免重复消费方面的策略。最后,讨论了MQ的推拉模式、RabbitMQ与Kafka的区别以及Kafka的高性能原因。
文章目录
2. 消息队列
2.1 MQ有什么用?
参考答案
消息队列有很多使用场景,比较常见的有3个:解耦、异步、削峰。
- 解耦:传统的软件开发模式,各个模块之间相互调用,数据共享,每个模块都要时刻关注其他模块的是否更改或者是否挂掉等等,使用消息队列,可以避免模块之间直接调用,将所需共享的数据放在消息队列中,对于新增业务模块,只要对该类消息感兴趣,即可订阅该类消息,对原有系统和业务没有任何影响,降低了系统各个模块的耦合度,提高了系统的可扩展性。
- 异步:消息队列提供了异步处理机制,在很多时候应用不想也不需要立即处理消息,允许应用把一些消息放入消息中间件中,并不立即处理它,在之后需要的时候再慢慢处理。
- 削峰:在访问量骤增的场景下,需要保证应用系统的平稳性,但是这样突发流量并不常见,如果以这类峰值的标准而投放资源的话,那无疑是巨大的浪费。使用消息队列能够使关键组件支撑突发访问压力,不会因为突发的超负荷请求而完全崩溃。消息队列的容量可以配置的很大,如果采用磁盘存储消息,则几乎等于“无限”容量,这样一来,高峰期的消息可以被积压起来,在随后的时间内进行平滑的处理完成,而不至于让系统短时间内无法承载而导致崩溃。在电商网站的秒杀抢购这种突发性流量很强的业务场景中,消息队列的强大缓冲能力可以很好的起到削峰作用。
2.2 说一说生产者与消费者模式
参考答案
所谓生产者-消费者问题,实际上主要是包含了两类线程。一种是生产者线程用于生产数据,另一种是消费者线程用于消费数据,为了解耦生产者和消费者的关系,通常会采用共享的数据区域,就像是一个仓库。生产者生产数据之后直接放置在共享数据区中,并不需要关心消费者的行为。而消费者只需要从共享数据区中去获取数据,就不再需要关心生产者的行为。但是,这个共享数据区域中应该具备这样的线程间并发协作的功能:
- 如果共享数据区已满的话,阻塞生产者继续生产数据放置入内;
- 如果共享数据区为空的话,阻塞消费者继续消费数据。
在Java语言中,实现生产者消费者问题时,可以采用三种方式:
- 使用 Object 的 wait/notify 的消息通知机制;
- 使用 Lock 的 Condition 的 await/signal 的消息通知机制;
- 使用 BlockingQueue 实现。
2.3 消息队列如何保证顺序消费?
参考答案
在生产中经常会有一些类似报表系统这样的系统,需要做 MySQL 的 binlog 同步。比如订单系统要同步订单表的数据到大数据部门的 MySQL 库中用于报表统计分析,通常的做法是基于 Canal 这样的中间件去监听订单数据库的 binlog,然后把这些 binlog 发送到 MQ 中,再由消费者从 MQ 中获取 binlog 落地到大数据部门的 MySQL 中。
在这个过程中,可能会有对某个订单的增删改操作,比如有三条 binlog 执行顺序是增加、修改、删除。消费者愣是换了顺序给执行成删除、修改、增加,这样能行吗?肯定是不行的。不同的消息队列产品,产生消息错乱的原因,以及解决方案是不同的。下面我们以RabbitMQ、Kafka、RocketMQ为例,来说明保证顺序消费的办法。
RabbitMQ:
对于 RabbitMQ 来说,导致上面顺序错乱的原因通常是消费者是集群部署,不同的消费者消费到了同一订单的不同的消息。如消费者A执行了增加,消费者B执行了修改,消费者C执行了删除,但是消费者C执行比消费者B快,消费者B又比消费者A快,就会导致消费 binlog 执行到数据库的时候顺序错乱,本该顺序是增加、修改、删除,变成了删除、修改、增加。如下图:
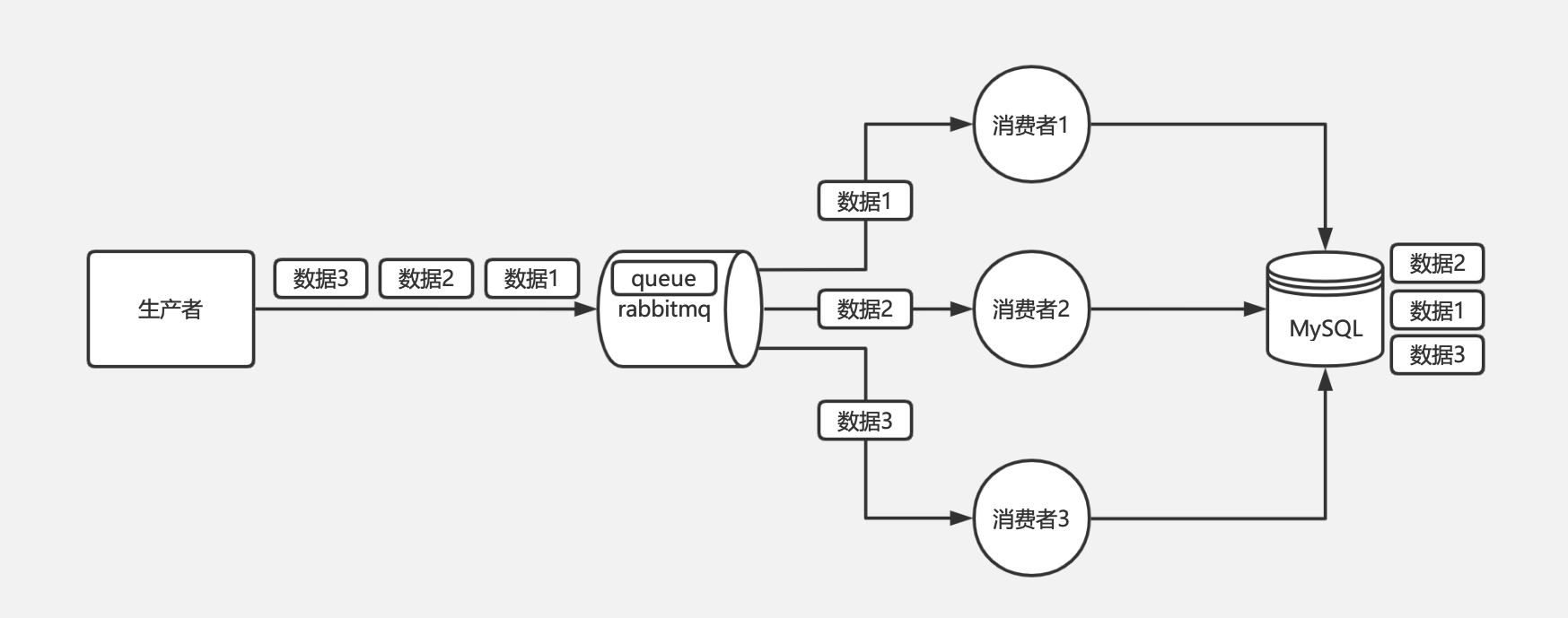
RabbitMQ 的问题是由于不同的消息都发送到了同一个 queue 中,多个消费者都消费同一个 queue 的消息。解决这个问题,我们可以给 RabbitMQ 创建多个 queue,每个消费者固定消费一个 queue 的消息,生产者发送消息的时候,同一个订单号的消息发送到同一个 queue 中,由于同一个 queue 的消息是一定会保证有序的,那么同一个订单号的消息就只会被一个消费者顺序消费,从而保证了消息的顺序性。如下图:
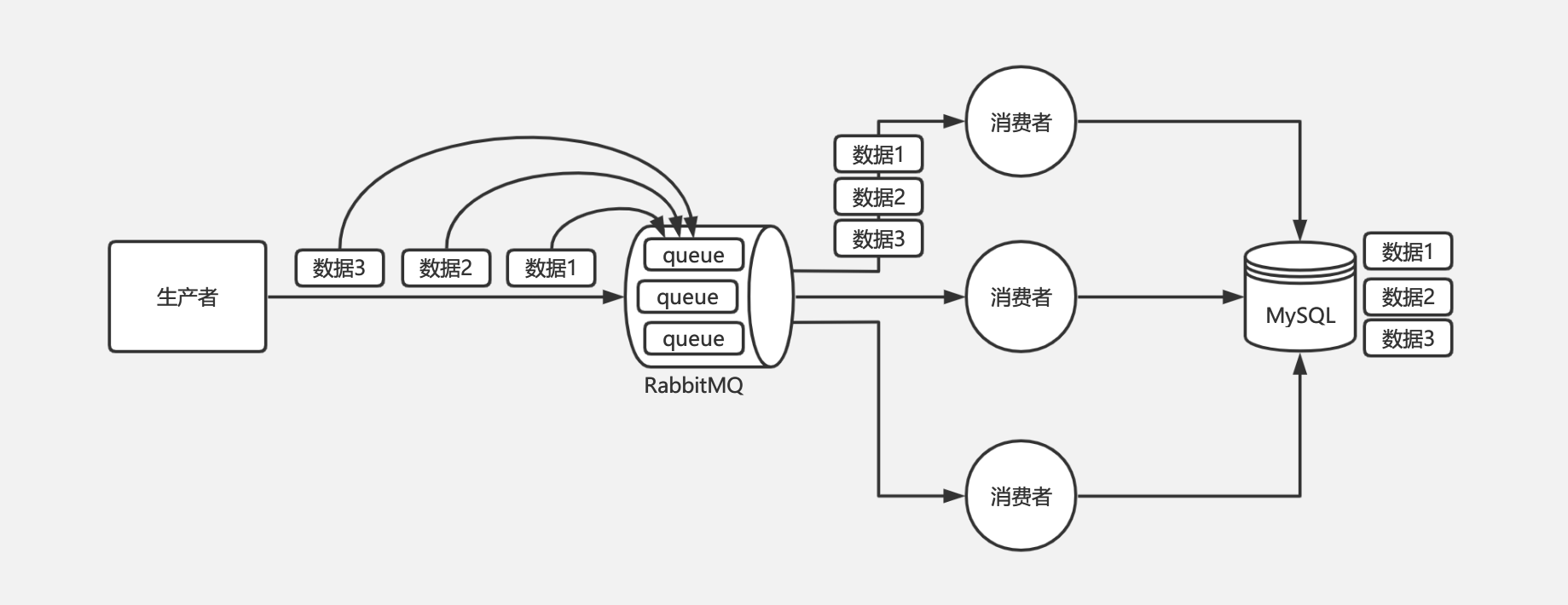
Kafka:
对于 Kafka 来说,一个 topic 下同一个 partition 中的消息肯定是有序的,生产者在写的时候可以指定一个 key,通过我们会用订单号作为 key,这个 key 对应的消息都会发送到同一个 partition 中,所以消费者消费到的消息也一定是有序的。
那么为什么 Kafka 还会存在消息错乱的问题呢?问题就出在消费者身上。通常我们消费到同一个 key 的多条消息后,会使用多线程技术去并发处理来提高消息处理速度,否则一条消息的处理需要耗时几十 毫秒,1 秒也就只能处理几十条消息,吞吐量就太低了。而多线程并发处理的话,binlog 执行到数据库的时候就不一定还是原来的顺序了。如下图:
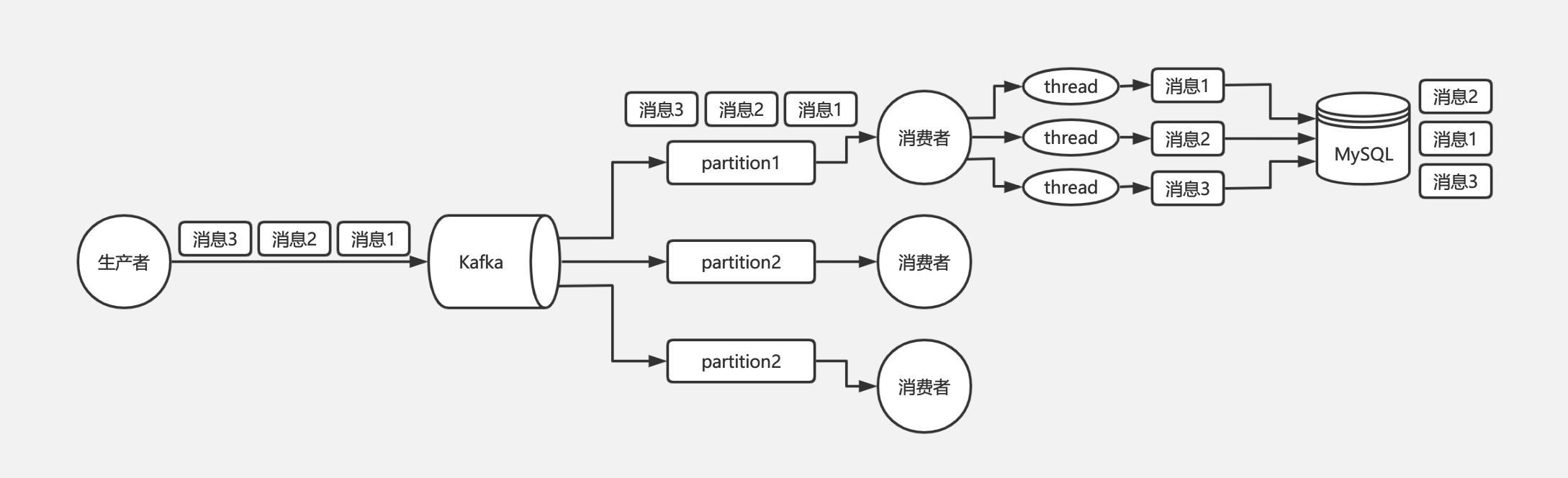
Kafka 从生产者到消费者消费消息这一整个过程其实都是可以保证有序的,导致最终乱序是由于消费者端需要使用多线程并发处理消息来提高吞吐量,比如消费者消费到了消息以后,开启 32 个线程处理消息,每个线程线程处理消息的快慢是不一致的,所以才会导致最终消息有可能不一致。
所以对于 Kafka 的消息顺序性保证,其实我们只需要保证同一个订单号的消息只被同一个线程处理的就可以了。由此我们可以在线程处理前增加个内存队列,每个线程只负责处理其中一个内存队列的消息,同一个订单号的消息发送到同一个内存队列中即可。如下图:
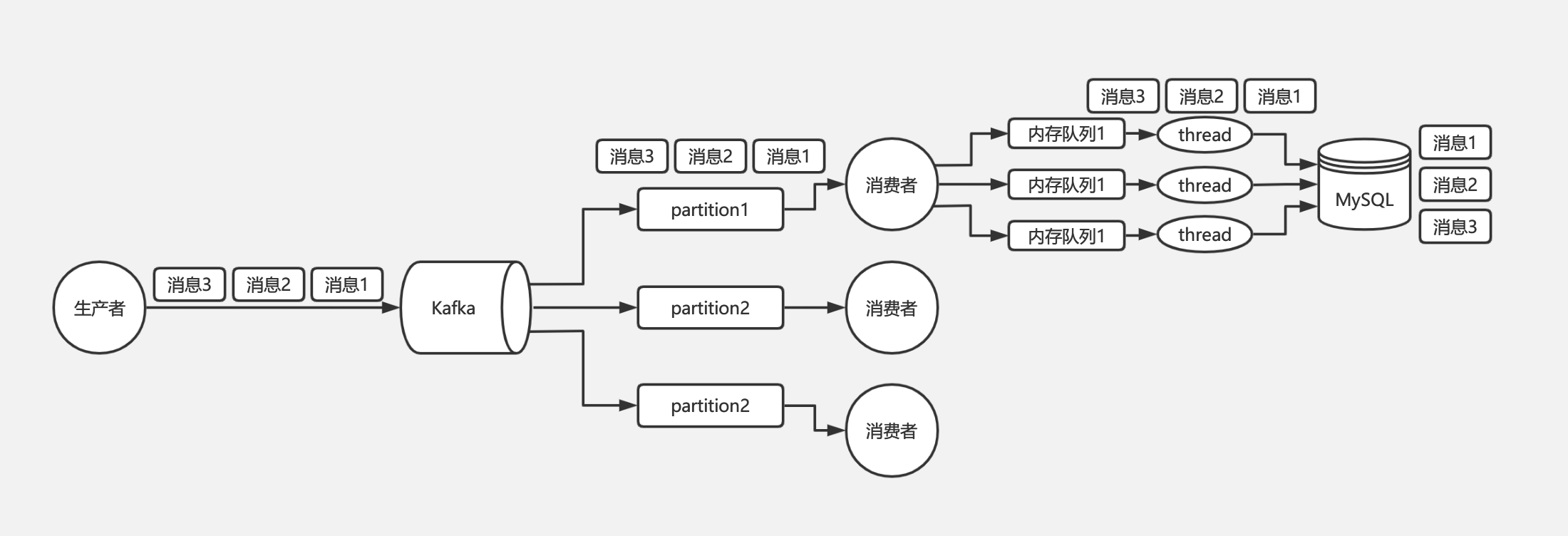
RocketMQ:
对于 RocketMQ 来说,每个 Topic 可以指定多个 MessageQueue,当我们写入消息的时候,会把消息均匀地分发到不同的 MessageQueue 中,比如同一个订单号的消息,增加 binlog 写入到 MessageQueue1 中,修改 binlog 写入到 MessageQueue2 中,删除 binlog 写入到 MessageQueue3 中。
但是当消费者有多台机器的时候,会组成一个 Consumer Group,Consumer Group 中的每台机器都会负责消费一部分 MessageQ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









