



前言
讲述了 React 框架从诞生到现在的历史演变,以及它如何通过一系列的特性和改进,逐步成为一个性能优异且易于使用的前端库。今日文章由 @Corbin Crutchley 分享,前端早读课@飘飘编译。
译文从这开始~~
React 是一个有些 “奇特” 的 Web 开发框架。我发现他们的很多 API 都需要特定的思维模式才能正确使用;这是为什么呢?
多年来,我在使用 React 的过程中也一直有同样的疑问,直到某一天,突然恍然大悟。多年来聆听 React 核心团队的交流,再加上对这个工具演变过程的观察,终于让我彻底理解了它的设计逻辑。
今天我想分享一下让我终于理解 React 库背后的故事。这个故事同时从两个方向展开:一个是历史性的,另一个纯粹源自代码本身。
为什么要分开讲?因为对大多数人来说,很容易以为 React 的 API 是零散发展出来的,没有统一的思路。但如果我们从它诞生的起点出发,梳理 React 团队一路走来的理念,你会发现,事实并非如此。
我希望通过这个故事提出一个核心观点:React 自诞生以来,在 API 设计上的一致性令人惊讶。而正是这种一致性,造就了一种特有的思维模型 —— 只要你掌握了它,就能迅速成为 React 高手。
接下来我们会聊到:
React 的基础:历史、JSX 和虚拟 DOM
早期的组件写法:类组件及其当时的用法
Hooks 的引入及其带来的变革
React 重写后的巨大转变
为什么 React 的数据获取方式是今天这个样子
React 如何 “转向” 服务器端
React API 的短期发展方向
那我们就开始吧!
React 的起点
时间回到 2011 年,Facebook 遇到了一个问题。他们在内部广告团队用一个自研框架叫 “BoltJS”。虽然大部分(大概 90%)广告相关的功能都可以用 Bolt 实现,但在项目中仍有一些情况,团队不得不脱离自己的框架,采用不太声明式的解决方案。
虽然这不是一个需要立即解决的问题,但它给 Facebook 迅速壮大的团队带来了一系列新的问题;在庞大的团队中,10% 的比例很快就会在一致性、培训以及整体开发者体验方面成为问题。如果不加以控制,这必然会影响他们以期望的速度推出产品的能力。
这些问题让广告团队的一位成员 Jordan Walke 感到不舒服。其实,很少有编程范式让他满意。他曾在一次社区访谈中说:
“刚开始学编程时,我就觉得那种基于数据绑定和状态变更的传统 MVC 模式不太对劲。虽然当时我还没掌握像 ‘状态变异’、‘函数式编程’ 这些术语,但我知道那种方式不适合我。”
“我的代码经常被别人说奇怪。我曾一度觉得‘大概我就是个奇怪的程序员’。后来我终于上了一门编程语言原理课,才学会用术语表达我想构建应用的方式。”
于是,Jordan 开始尝试着解决他认为 Bolt 和其他框架存在的问题。他最初做了一个叫 “FaxJS” 的个人项目,后来改名为 “FBolt(Functional Bolt)”,再后来,它就成了 “React”。一个小团队也开始围绕这个新工具展开开发。
时间来到 2012 年,Facebook 状态很好 —— 好到刚花 10 亿美元收购了 Instagram。
当时 Instagram 有安卓和 iOS 的移动应用,但没有网页版。新加入 Facebook 的团队需要构建这个网页版本,但他们被要求使用 Facebook 自家的技术栈。
评估了 Bolt 和 React 之后,这个团队做了个决定:他们将成为第一个在生产环境中使用 React 的团队。
很快,他们意识到手上的这个工具不一般:开发速度很快,性能表现不错,开发体验也很好。于是有人开始提出把这个项目开源。
但这时候新问题来了:Facebook 内部已经有两个用于浏览器渲染的方案 ——Bolt 和刚起步的 React。
两个团队坐下来认真讨论,发现问题的复杂度超出了他们的权限范围。此时 Facebook 正值 IPO 低谷期,而广告产品是主要收入来源,这支广告团队才刚把一个大项目迁移到 Bolt。如果换成 React,可能要花上四个月重写,中间不能加任何新功能。
眼看着 React 的内部推广要泡汤了,CTO 出面了:“做正确的技术决策,着眼长远。如果这会带来短期代价,我支持你们。哪怕重写要花几个月,也去做。”
于是广告平台也迁移到了 React,并像 Instagram 那样取得了成功。
到 2013 年,推动开源 React 的团队逐渐占据主导,最终赢得内部共识。React 准备开源了:在 JSConf US 2013 上,Tom Occhino 和 Jordan Walke 正式发布了 React 的源码和文档。
模板语法的痛点
React 早期就提出一个理念:用 JavaScript 来写 HTML。
这带来了极大的灵活性。它不仅避免了需要定制模板标签来实现条件渲染或循环的麻烦,还让 UI 代码的迭代变得更加有趣和快速。
比如原来可能需要这样写模板(假设用的是某个模板框架):
<div>
<some-tag data-if="someVar"></some-tag>
<some-item-tag data-for="let someItem of someList"></some-item-tag>
</div>现在可以这样用 JSX 写:
const data = (
<div>
{someVar && <some-tag />}
{someList.map((someItem) => (
<some-item-tag />
))}
</div>
);这样的方式有几个关键优势:
模板可以在运行前就编译,开发时更早发现错误
JSX 不是字符串,天生具有更好的 XSS 安全性
可以重用 JavaScript 的控制逻辑,避免在模板语言中重复造轮子
JSX 的语法也让 “模板转 JS” 这一步变得非常轻量。比如:
function App() {
return (
<ul role="list">
<li>Test</li>
</ul>
);
}会被转换成:
function App() {
return React.createElement(
"ul",
{ role: "list" },
[React.createElement("li", {}, ["Test"])]
);
}这样一来,哪怕代码经过了转换,出错时的定位依然清晰,调试起来也更方便。
“关注点分离” 其实不是你以为的那个意思
JSX 经常被批评 “打破了关注点分离原则”。早期很多项目按语言类型来组织代码:
src/
html/
button.html
card.html
css/
button.css
card.css
js/
button.js
card.js但这其实是个很武断的分类方式。你很难快速找到某个功能相关的所有代码。
React 团队提倡的方式(也被很多现代项目采纳)是按功能模块组织代码:
src/
button/
button.html
button.css
button.js
card/
card.html
card.css
card.js这种结构更有利于理解和维护代码,也更符合 React 的开发理念。
以 “任意时刻的状态” 来描述 UI
在 React 之前,像 Backbone.js 这样的框架通常是这样管理 UI 的:
<!-- index.html, shortened for brevity -->
<div id="counter-app"></div>
<!-- index.html 中的模板 -->
<script type="text/template" id="counter-template">
<p>Count: <%= count %></p>
<button>Add 1</button>
</script>// app.js
var CounterModel = Backbone.Model.extend({ defaults: { count: 0 } });
var CounterView = Backbone.View.extend({
el: "#counter-app",
template: _.template($("#counter-template").html()),
events: { "click button": "increment" },
initialize() {
this.listenTo(this.model, "change", this.render);
this.render();
},
render() {
var html = this.template(this.model.toJSON());
this.$el.html(html);
},
increment() {
this.model.set("count", this.model.get("count") + 1);
},
});
var counterModel = new CounterModel();
new CounterView({ model: counterModel });在这里,我们正在做很多事情:
从包含表示我们模板的字符串的脚本标签中读取初始模板
定义模板中要使用的组件的数据模型
手动绑定事件并在请求时将模板重新构建为 HTML
这里虽然也能实现功能,但数据和视图同步过程是手动管理的,一不小心就容易出问题。
而 React 的同类代码长这样:
<div id="root"></div>
<script type="text/babel">
var Counter = React.createClass({
getInitialState: () => ({ count: 0 }),
increment() {
this.setState({ count: this.state.count + 1 });
},
render() {
return (
<div>
<p>Count: {this.state.count}</p>
<button onClick={this.increment}>Add 1</button>
</div>
);
},
});
ReactDOM.render(<Counter />, document.getElementById("root"));
</script>虽然用 this.setState 显式更新了模板,但与 Backbone 最大的区别在于:
React 中的 render 方法不是 “初始模板”,而是 “每一次状态变化都用的模板”。
也就是说,我们不再关心 UI 是怎么一步步 “变成” 现在这个样子的,而是用状态直接描述 “现在这个样子”。这种思维方式来源于 Jordan 对函数式编程的学习:数据应该是不可变的,视图是状态的纯函数。
更棒的是,这种响应式的方式也非常高效:点击按钮、更新状态、自动重新渲染 —— 一切都很自然。
让模板具备响应性
JSX 提供了极大的灵活性,但它也意味着每次状态变化时,模板中的所有节点都需要重新执行,才能用新数据构建 DOM。
 没有虚拟 DOM 的话,React 会重新渲染所有组件
没有虚拟 DOM 的话,React 会重新渲染所有组件
对于小型应用,这种方式问题不大;但如果是大型 DOM 树,频繁的整体重渲染会带来明显的性能问题。
为了解决这个问题,React 团队引入了一个概念:虚拟 DOM(VDOM)。这个虚拟 DOM 是浏览器 DOM 在 JavaScript 中的一个副本。当 React 创建 DOM 节点时,它也会将副本记录在自己的 VDOM 中。
这样,当某个组件需要更新 DOM 时,React 就会先与 VDOM 做对比,仅对需要更新的部分进行重新渲染。
有了 VDOM,React 就可以把重渲染限制在受影响的组件子树中
这是一项巨大的性能优化,使得 React 应用可以大规模扩展而不牺牲性能。
从内部实现角度看,React 在 “协调(reconciliation)” 阶段引入了差异比较(diff)步骤。值得一提的是,React 在早期版本中就对 VDOM 的 diff 算法做了不少优化。
React 处理状态变化 → 触发 VDOM diff → 预更新 VDOM → 最终提交真实 DOM
React 早期的开发体验
React 在 2013 年推出时采用的是类组件(class-based components);Hooks 直到 2019 年才发布。类组件的出现很棒,它让我们可以将代码模块化,但也带来了一些问题。
比如组件的核心理念是 “组合性”:可以通过已有组件构建新组件:
// 已有组件
class Button extends React.Component { /* ... */ }
class Title extends React.Component { /* ... */ }
class Surface extends React.Component { /* ... */ }
// 新的组合组件
class Card extends React.Component {
render() {
return (
<Surface>
<Title />
<Button />
</Surface>
);
}
}没有这样的组合能力,React 根本无法扩展到大型项目中。但问题在于:类组件的内部逻辑是不可组合的。
来看这个例子:
class WindowSize extends React.Component {
state = {
width: window.innerWidth,
height: window.innerHeight,
};
handleResize = () => {
this.setState({
width: window.innerWidth,
height: window.innerHeight,
});
};
componentDidMount() {
window.addEventListener("resize", this.handleResize);
}
componentWillUnmount() {
window.removeEventListener("resize", this.handleResize);
}
render() {
// ...
}
}这个 WindowSize 组件获取了浏览器窗口的宽高,将其存储在 state 中,并在变化时触发组件的更新。
假设我们想在多个组件中重用这套逻辑。根据面向对象编程的思路,可以使用类继承(class inheritance)。
直观但短视的继承方案
不修改 WindowSize 组件的代码,我们可以用 extends 来让新组件继承它的方法和状态:
class MyComponent extends WindowSize {
render() {
const { windowWidth, windowHeight } = this.state;
return (
<div>
The window width is: {windowWidth}
<br />
The window height is: {windowHeight}
</div>
);
}
}这个简单示例可以运行,但它的问题也很明显:一旦 MyComponent 变复杂,就得小心处理继承逻辑,比如必须调用 super 方法:
class MyComponent extends WindowSize {
state = {
...this.state, // 继承父类状态
counter: 0,
};
intervalId = null;
componentDidMount() {
super.componentDidMount(); // 继承父类生命周期方法
this.intervalId = setInterval(() => {
this.setState((prevState) => ({ counter: prevState.counter + 1 }));
}, 1000);
}
componentWillUnmount() {
super.componentWillUnmount(); // 清理事件监听
clearInterval(this.intervalId);
}
render() {
const { windowWidth, windowHeight, counter } = this.state;
return (
<div>
The window width is: {windowWidth}
<br />
The window height is: {windowHeight}
<br />
The counter is: {counter}
</div>
);
}
}但只要漏掉一个 super(),就可能引发意外行为,甚至内存泄漏。
于是,React 社区提出了一种更好的方案:高阶组件(Higher-Order Components, HoC)。
社区实践:高阶组件
借助高阶组件,能够避免要求用户在其代码库中进行 super 调用,而是从基类接收参数作为 props 传递给扩展类:
const withWindowSize = (WrappedComponent) => {
return class WithWindowSize extends React.Component {
state = {
width: window.innerWidth,
height: window.innerHeight,
};
handleResize = () => {
this.setState({
width: window.innerWidth,
height: window.innerHeight,
});
};
componentDidMount() {
window.addEventListener("resize", this.handleResize);
}
componentWillUnmount() {
window.removeEventListener("resize", this.handleResize);
}
render() {
return (
<WrappedComponent
{...this.props}
windowWidth={this.state.width}
windowHeight={this.state.height}
/>
);
}
};
};
class MyComponentBase extends React.Component {
render() {
const { windowWidth, windowHeight } = this.props;
return (
<div>
The window width is: {windowWidth}
<br />
The window height is: {windowHeight}
</div>
);
}
}
const MyComponent = withWindowSize(MyComponentBase);在 Hooks 出现前,这是组件逻辑复用的主流方式。
不过,它也有缺点:开发者需要知道有哪些 props 是高阶组件提供的,不太适合 TypeScript 类型检查,而且总给人一种 “外挂工具” 的感觉,而不像是 React 的内置能力。
类组件的早期替代方案
2015 年,React 0.14 发布,带来了类组件的替代方案:函数组件(function components)。
React 团队曾说过,类组件其实就是 “一个带状态容器的 render 函数”。那如果把状态拿掉,只保留 render 呢?
于是下面这段类组件:
var Aquarium = React.createClass({
render: function () {
var fish = getFish(this.props.species);
return <Tank>{fish}</Tank>;
},
});可以简化成:
var Aquarium = (props) => {
var fish = getFish(props.species);
return <Tank>{fish}</Tank>;
};写法更简洁了,但也有个大问题:函数组件没有自己的状态(state)。
这限制了它在实际项目中的使用,因此许多人还是选择继续使用类组件。
开发体验的成熟期:Hooks 登场
React 16.8 发布时,引入了 Hooks,彻底解决了函数组件无法拥有状态的问题,也为后续的 API 奠定了基础。
原本需要用类组件 + 生命周期方法才能实现状态管理和副作用处理:
class WindowSize extends React.Component {
state = {
width: window.innerWidth,
height: window.innerHeight,
};
handleResize = () => {
this.setState({
width: window.innerWidth,
height: window.innerHeight,
});
};
componentDidMount() {
window.addEventListener("resize", this.handleResize);
}
componentWillUnmount() {
window.removeEventListener("resize", this.handleResize);
}
render() {
// ...
}
}现在可以用纯函数 + Hooks 来实现:
function WindowSize() {
const [size, setSize] = React.useState({
width: window.innerWidth,
height: window.innerHeight,
});
const { height, width } = size;
useEffect(() => {
const handleResize = () => {
setSize({
width: window.innerWidth,
height: window.innerHeight,
});
};
window.addEventListener("resize", handleResize);
return () => window.removeEventListener("resize", handleResize);
}, []);
return (
// ...
);
}这种新 API 带来了多个好处,其中最关键的一点就是:提升了逻辑的组合能力。
在逻辑层应用组件的优势
在类组件中,组合逻辑的主流方式是高阶组件(HoC),而在 Hooks 体系中,组合逻辑的方法是…… 🥁
另一个 Hook。😐
这听起来可能理所当然,但正是这种 “理所当然”,让 Hook 拥有了强大的能力 —— 无论是现在还是将来。
来看一个自定义的 useWindowSize Hook:
function useWindowSize() {
const [size, setSize] = React.useState({
width: window.innerWidth,
height: window.innerHeight,
});
const { height, width } = size;
useEffect(() => {
const handleResize = () => {
setSize({
width: window.innerWidth,
height: window.innerHeight,
});
};
window.addEventListener("resize", handleResize);
return () => window.removeEventListener("resize", handleResize);
}, []);
return { height, width };
}📌 说明
你可能注意到了,我们几乎不需要改动原来组件中的逻辑。正是这种 “逻辑抽离后几乎无改动” 的特性,让 Hook 的组合能力非常强大。
然后这个自定义 Hook 就可以在任意函数组件中复用:
function MyComponent() {
const { height, width } = useWindowSize();
return (
<div>
The window width is: {width}
<br />
The window height is: {height}
</div>
);
}持续一致的 I/O 处理方式
我可以花几个小时聊编程中的副作用。这里只做个简单概括:
“副作用” 指的是从组件 / 函数外部改变状态的行为。
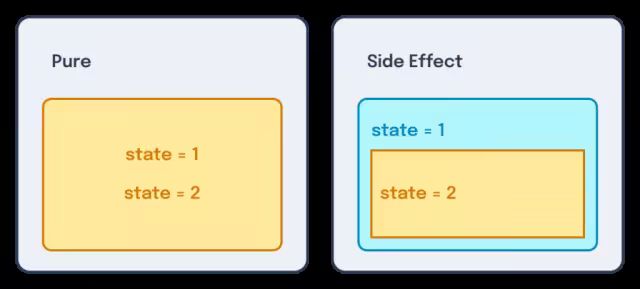 纯函数只能在自身作用域内修改状态,而副作用则是改变外部环境中的数据。
纯函数只能在自身作用域内修改状态,而副作用则是改变外部环境中的数据。
所有 I/O(如事件监听、请求等)本质上都是副作用,因为用户和外部世界在函数之外。
大多数 I/O 操作都需要在某个时机进行清理:要么取消监听,要么重置设置的状态,否则就可能造成 bug 或内存泄漏。
React 的 useEffect Hook 正是为了解决这个问题,它鼓励开发者以更规范的方式处理副作用和清理逻辑。
来看类组件中副作用的处理方式:
class Listener extends React.Component {
componentDidMount() {
window.addEventListener("resize", this.handleResize);
}
componentWillUnmount() {
window.removeEventListener("resize", this.handleResize);
}
handleResize = () => {
// ...
};
}📌 说明
你可能会疑惑:为什么 handleResize 必须是箭头函数?因为如果不是,this 会指向 window 而不是组件实例。
而在函数组件中,用 useEffect 来处理就简单直观多了:
function Listener() {
useEffect(() => {
const handleResize = () => {
// ...
};
window.addEventListener("resize", handleResize);
return () => window.removeEventListener("resize", handleResize);
}, []);
}这也是 React 没有为函数组件设计 1:1 对应的类生命周期方法的原因之一:Hook 的方式更优雅,也更利于副作用的管理和清理。
解决 React 的一致性问题
React 18 发布时,很多人发现他们的应用在开发模式下突然 “出问题” 了。
实际发生的是:React 故意对开发模式下的 <StrictMode> 组件做了变更,而这个组件默认出现在大多数 React 应用模板中。
在此之前,<StrictMode> 主要用来提示开发者使用了过时的 API 或生命周期方法。
而现在,它更出名的原因是这个:
function App() {
useEffect(() => {
console.log("Mounted");
}, []);
return <>{/* ... */}</>;
}在开发环境中,这段代码会执行两次;在生产环境中只执行一次。
为什么会有这个改变?
简单说:React 团队希望你能正确清理副作用,避免内存泄漏和难以调试的问题。
更深层的原因是:他们希望组件的渲染行为是幂等的(idempotent)。
什么是幂等?举个例子说明:
假设你在工厂流水线上工作,有个按钮控制上方滑道掉落空箱子,箱子会被传送到包装机封装。


如果你在上一个箱子还没封装完就再次按按钮,新箱子就会卡住流水线,出问题了。
 而如果这个按钮是 “幂等” 的,不管你按多少次,只会等上一个箱子包装完成后才掉落下一个。
而如果这个按钮是 “幂等” 的,不管你按多少次,只会等上一个箱子包装完成后才掉落下一个。
React 的渲染行为也是一样的。
来看这段代码:
function BoxAddition() {
useEffect(() => {
window.addBox();
}, []);
return null;
}每次渲染这个组件,都会 “添加一个箱子”。但如果我们不断地挂载 / 卸载这个组件,系统里总箱子数会出问题,表现不一致。
比如这样写:
function CheckBoxAddsOnce() {
const [bool, setBool] = useState(true);
useEffect(() => {
setInterval(() => setBool((v) => !v), 0);
setInterval(() => setBool((v) => !v), 100);
setInterval(() => setBool((v) => !v), 200);
});
if (bool) return null;
return <BoxAddition />;
}这会导致 BoxAddition 不断被挂载卸载,window.addBox() 被调用了很多次,而没有对应的清理逻辑。
所以正确写法是这样的:
function BoxAddition() {
useEffect(() => {
window.addBox();
return () => window.removeBox();
}, []);
return null;
}这就是为什么 React 18 改变了 <StrictMode> 的行为,用来提醒你注意这些 “非幂等” 问题。
而且,这并不是 React 18 新加的偶然想法。幂等性早在 Facebook 团队第二次公开讲解 React 时就被列为核心设计原则。
为保持一致性而制定的规则
不过这不代表你可以随意编写 Hook。React 明确规定了 Hook 的一套使用规则:
所有 Hook 都必须是函数
函数名称必须以
use开头不允许在条件语句中调用 Hook
Hook 必须在组件最顶层调用
不允许动态调用 Hook
传给 Hook 的参数不能被修改
无论是官方的还是自定义的 Hook,从早期的 useState 到后来的 useActionState,这些规则都适用。
✅ 正确示例:
function AllowedHooksUsage() {
const [val, setVal] = React.useState(0);
const { height, width } = useWindowSize();
return <>{/* ... */}</>;
}❌ 错误示例:
function DisallowedHooksUsage() {
const obj = {};
useObj(obj);
obj.key = (obj.key ?? 0) + 1; // ❌ 修改传入 Hook 的对象
if (bool) {
const [val, setVal] = React.useState(0); // ❌ 条件调用 Hook
}
if (other) return null;
const { height, width } = useWindowSize(); // ❌ return 后再调用 Hook
for (let i = 0; i < 10; i++) {
const ref = React.useRef(); // ❌ 循环中调用 Hook
}
return <>{/* ... */}</>;
}接下来我们来看看:为什么这些规则如此重要?
发挥虚拟 DOM 的全部潜力
我们的故事讲到了 React 18 以及它所带来的变化,但在展望未来之前,我们先回到过去。让我们把时间拨回到 2016 年。
在 ReactNext 2016 上,Andrew Clark 做了一个名为「React 的下一步」的演讲。他介绍了一个名叫 Fiber 的实验项目。
有没有注意到?
在他的演讲中提到,他们早在 2014 年的博客文章中就谈到过 React 的一些计划 —— 这些计划与后来 Fiber 实现的内容惊人地一致。
虽然当时 Andrew 提醒说「这个实验可能行不通」,但事实证明:到了 2017 年,React 16 发布时,Fiber 已经成为 React 的新稳定内核。这还是少数几个被写进 Facebook 工程博客的版本之一。
关于 Fiber 的具体实现细节,Andrew 在 GitHub 仓库 中有详细解释。但大体而言,它实现了以下能力:
暂停工作并稍后恢复
为不同类型的任务分配优先级
复用已完成的任务
在任务不再需要时中止它
这些能力虽然对 Hooks 做出了一些限制,但同时也解锁了大量新特性,为 React 的未来打下了基础。
解决错误处理问题
Fiber 解锁的第一个特性是在 React 16 中引入的 错误边界(Error Boundaries)。到了 React 16.6,这个机制获得了改进,解决了 React 应用长久以来的一个难题。
在此之前,如果组件中某个地方抛出错误,会导致整个 React 应用崩溃。
没有错误边界时,即使是叶子节点出错,也可能导致整个应用崩溃
但由于组件是树状结构的,我们可以在潜在出错的组件与其他状态之间建立 “边界”。
有了错误边界,错误事件只会上冒到最近的边界,不会影响整个应用
不仅单个组件适用,还可以通过将一组组件包在同一个 ErrorBoundary 中,实现分组隔离错误:
import React, { useState } from "react";
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
static getDerivedStateFromError(error) {
return { hasError: true };
}
render() {
if (this.state.hasError) {
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
function App() {
return (
<div>
<ErrorBoundary>
<ErrorCounter />
<OtherCounter />
</ErrorBoundary>
<ul>
<li>Item 1</li>
</ul>
</div>
);
}如果 ErrorBoundary 中的某个子组件出错,它会移除所有子节点,并显示备用 UI,而外部组件则不受影响。
这类错误隔离机制正是因为 Fiber 能 “中止任务” 而实现的。
解决代码拆分(bundle splitting)问题
除了错误处理,React 16.6 还引入了 懒加载组件(lazy loading) 的机制:
import React, { lazy, Suspense } from "react";
const LargeBundleComponent = lazy(() => import("./LargeBundleComponent"));
function MyComponent() {
return <LargeBundleComponent />;
}懒加载组件使 React 能够 tree-shake 删除仅与导入组件相关的捆绑代码,这样,只有在渲染组件时, lazy 包裹的组件代码才会被导入到浏览器中:
没有懒加载:所有组件代码都被打包成一个 JS 文件,不管用不用都加载
有了懒加载:只有真正渲染的组件才会触发加载,重复代码会被提取成共享模块,仅加载一次
这使得通过网络加载组件及其相关代码(在此例中为 LargeBundleComponent )来进一步将 VDOM 用作复杂状态的表示成为可能。
解决加载状态处理问题
但懒加载组件存在一个问题:加载过程中用户看到的是什么?
这时就需要 Suspense 边界来处理了。在 2018 年 JSConf Iceland 上,React 团队发布了 Suspense 组件,让你能够在高延迟场景下将加载状态作为备用方案处理在用户界面中,就像上面提到的 lazy 组件那样:
import React, { lazy, Suspense } from "react";
const LargeBundleComponent = lazy(() => import("./LargeBundleComponent"));
function MyComponent() {
return (
<Suspense fallback={<div>Loading...</div>}>
<LargeBundleComponent />
</Suspense>
);
}就像 ErrorBoundary 用来捕获错误一样,Suspense 用来捕获 “加载中的状态”,让我们能优雅地控制哪些地方展示 Loading。
还可以为多个异步组件分别设置 Suspense:
import React, {lazy, Suspense} from 'react';
const LargeBundleComponent = lazy(() => import('./LargeBundleComponent'));
const AnotherLargeComponent = lazy(() => import('./AnotherLargeComponent'));
function MyComponent() {
return (
// Only resolves once both components are loaded
<Suspense fallback={<div>Loading...</div>}>
<LargeBundleComponent />
<AnotherLargeComponent />
</Suspense>
);
}
// OR
function MyOtherComponent() {
return (
// Show a loading state per component
<Suspense fallback={<div>Loading...</div>}>
<LargeBundleComponent />
</Suspense>
<Suspense fallback={<div>Loading...</div>}>
<AnotherLargeComponent />
</Suspense>
);
}有迹象表明,Suspense 未来可能还会用于数据请求场景……👀
并发渲染的探索
Fiber 带来了许多能力,但直到 React 18,我们才真正看到一系列 API 来支持这些底层行为。
这些 API 被统称为 并发特性(Concurrent Features),包括:
useTransitionuseOptimisticuseDeferredValuestartTransition
我们以 startTransition 为例来看看它的用途。
假设我们有一个组件要渲染大量列表项,我们想将用户输入的文本映射到这些元素上:
const SlowList = ({ text }) => {
const items = useMemo(() => {
let list = [];
for (let i = 0; i < 20000; i++) {
list.push(`Item ${i} - includes '${text}'`);
}
return list.filter((item) =>
item.toLowerCase().includes(text.toLowerCase())
);
}, [text]);
return (
<ul>
{items.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
);
};直观地讲,我们可能会将受控的输入状态传递给这个 SlowList 元素:
const LegacyDemo = () => {
const [inputText, setInputText] = useState("");
const [filterTerm, setFilterTerm] = useState("");
const handleChange = (e) => {
const value = e.target.value;
setInputText(value);
setFilterTerm(value); // 会阻塞渲染
};
return (
<div>
<input value={inputText} onChange={handleChange} />
<SlowList text={filterTerm} />
</div>
);
};然而,如果我们这样做,就会发现当用户输入时,输入框会因为列表重新渲染而出现延迟:
这种情况的发生是因为渲染列表所需的时间比用户输入每个单独字符的时间要长。为了解决这个问题,我们需要一种方法来告诉 React 暂缓对列表的更新,优先处理输入元素的变化。幸运的是,Fiber 就是为了实现这一功能而编写的。我们可以使用 useTransition API 与 Fiber 进行交互来解决这个问题:
const ConcurrentDemo = () => {
const [inputText, setInputText] = useState("");
const [filterTerm, setFilterTerm] = useState("");
const handleChange = (e) => {
const value = e.target.value;
setInputText(value);
startTransition(() => {
setFilterTerm(value);
});
};
return (
<div>
<input value={inputText} onChange={handleChange} />
<SlowList text={filterTerm} />
</div>
);
};这样输入就不会再卡顿,体验流畅许多。
这一变化现在带来了更流畅的文本更新体验:
终极目标:原生数据请求支持
Fiber 奠定了未来的基础,而直到 React 19,这些积累最终汇聚成一个重大方向:原生的数据请求 API。
多年来,React 团队一直在强调「提升状态(lift state)」的重要性。他们早在 2017 年就把这点写进了官方文档,Dan 甚至在 2015 年的 GitHub 评论中提到过这个问题。
React 19 的 use API 和 Suspense API 正是以此理念为基础构建的。
具体做法:
在父组件中生成
Promise将
Promise传给子组件子组件用
use(promise)获取数据用
Suspense包裹处理加载状态
function Child({ promise }) {
const data = use(promise);
return <p>{data}</p>;
}
function App() {
const promise = useMemo(() => fakeFetch(), []);
return (
<Suspense fallback={<p>Loading...</p>}>
<Child promise={promise} />
</Suspense>
);
}
const fakeFetch = () =>
new Promise((resolve) => setTimeout(() => resolve(1000), 1000));让我们花点时间来看看 use 内部的工作原理。根据 React 团队为 use 引入的 RFC:
如果传入的 Promise 还没完成,就抛出一个异常;当 Promise resolve 后,React 会重新渲染组件。
React 首先会尝试检查该 Promise 是否已被读取过,无论是通过不同的 use 调用还是不同的渲染尝试。如果是这样,React 可以直接复用上次的结果,同步进行,而无需挂起。
而 Fiber 的机制正是允许中断和恢复组件渲染,因此这一切才能实现。
并行 vs 瀑布式数据请求
你可能会说:“等等!我也可以用 useFetcher 把数据请求逻辑提升到上层呀!”
你说得没错,确实可以!
来看一个例子,演示如何通过传统方式提升请求逻辑到父组件中,并把结果作为 props 传下去:
import { useState, useEffect } from "react";
// 子组件,接收 posts 作为 props
function UserPosts({ posts, loading, error }) {
if (loading) return <div>Loading posts...</div>;
if (error) return <div>Error loading posts: {error}</div>;
return (
<div>
<h3>Posts</h3>
{posts?.map((post) => (
<div
key={post.id}
style={{
marginBottom: "1rem",
padding: "1rem",
border: "1px solid #ccc",
}}
>
<h4>{post.title}</h4>
<p>{post.content}</p>
</div>
))}
</div>
);
}
// 父组件,接收 profile 和子组件
function UserProfile({ profile, loading, error, children }) {
if (loading) return <div>Loading profile...</div>;
if (error) return <div>Error loading profile: {error}</div>;
return (
<div>
<h2>User Profile</h2>
<div
style={{
marginBottom: "2rem",
padding: "1rem",
border: "2px solid #333",
}}
>
<h3>{profile.name}</h3>
<p>Email: {profile.email}</p>
<p>Bio: {profile.bio}</p>
</div>
{children}
</div>
);
}
// 主组件,同时发起两个并行请求
export default function App() {
const userId = "123";
const {
data: profile,
loading: profileLoading,
error: profileError,
} = useFetch(`/users/${userId}/profile`);
const {
data: posts,
loading: postsLoading,
error: postsError,
} = useFetch(`/users/${userId}/posts`);
return (
<div style={{ padding: "2rem" }}>
<UserProfile
profile={profile}
loading={profileLoading}
error={profileError}
>
<UserPosts posts={posts} loading={postsLoading} error={postsError} />
</UserProfile>
</div>
);
}这个方式在逻辑上没问题,而且可以实现并行请求。但新的问题也来了:
每个子组件都要传多个 props(loading、error、data)
如果我们想统一一个全局的 loading 状态,或者合并多个状态,就需要较大幅度的重构
使用 use + Suspense 优雅统一加载状态
React 19 的 use API 搭配 Suspense,就可以完美解决这些问题。
你可以自由地选择在组件树的哪个位置放置 Suspense 边界,React 会自动接管加载状态。你无需手动传递 loading 和 error。
这不仅简化了代码结构,也大大提高了可维护性和代码可组合性。
React 数据请求方案的优势
你可能会问:“但 Corbin,React 社区早就有很多数据请求库了,比如 SWR、React Query,这些都很好用。那为什么还要用 use 呢?”
这是个好问题!我也曾深入比较过这些方案,最后发现,React 自带的 use API 有两个关键优势:
1、强制提升数据请求逻辑到组件树更高层
这能有效避免瀑布式(waterfall)请求,显著提升性能。
2、简化多个加载状态的管理
不再需要分别管理每个请求的 loading /error 状态,一切由 Suspense 统一处理。
我们已经在前面的例子中看到了:
瀑布式请求是先请求用户信息,再加载帖子
并行请求可以大幅减少等待时间
使用
use+Suspense后,甚至可以做到代码结构整洁、逻辑清晰、状态统一
这不仅是一次 API 设计优化,更是 React 走向原生异步 UI 渲染的关键一步。
融合旧与新:错误处理与数据请求
很多人常常忽略一点:“渲染” 本身也是一种副作用。在 React 中,更新界面就是将数据转化为输出结果,而输出(I/O)本质上就是副作用。
这是真的!而正因为如此,我们之前用于处理错误的机制(ErrorBoundary 错误边界组件),同样可以用来处理数据请求中的错误。
来看一个例子,演示如何捕获通过 use API 抛出的错误:
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
static getDerivedStateFromError(error) {
return { hasError: true };
}
render() {
if (this.state.hasError) {
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
function Load({ promise }) {
const data = React.use(promise);
return <p>Success</p>;
}
function App() {
const promise = React.useMemo(
() =>
new Promise((resolve, reject) => {
setTimeout(() => {
reject(); // 模拟请求失败
}, 1000);
}),
[],
);
return (
<div>
<ErrorBoundary>
<React.Suspense fallback={<p>Loading..</p>}>
<Load promise={promise} />
</React.Suspense>
</ErrorBoundary>
</div>
);
}
这个例子中,父组件通过 Suspense 和 ErrorBoundary 包裹了子组件。use(promise) 在加载失败时会抛出错误,Suspense 捕捉到 “加载状态”,ErrorBoundary 捕捉到最终的错误,展现备用 UI。
转向服务端
服务端渲染(SSR) 在 Web 的发展历程中由来已久。不论是 WordPress、Ruby on Rails 还是早期的 React SSR,本质上都是将模板渲染为 HTML/CSS/JS,返回给浏览器。
虽然 Next.js(2016)简化了 React 的 SSR 使用方式,但早在 React 0.4 版本时,React 就已支持服务端渲染。甚至在官网博客中,还展示了与 Ruby 和 Python 的结合方式。
解决 “两个计算机” 的问题
从 React 0.4 到 React Server Components(RSC) 发布前,SSR 总存在一个问题:
页面首次由服务端渲染后,浏览器拿到页面后仍需重新渲染所有组件,做一次 “重演”。
直到 2023 年 Next.js 开始采用 RSC,并在 React 19 中正式稳定,我们才有了彻底的解决方案。
📌 历史小知识
Next.js 13.4 发布于 2023 年 5 月,而 React 19 正式版直到 2024 年 12 月才发布。在此期间,Next.js 使用了 React 19 的 “canary”(实验)版本。
【第3440期】探索 React 19:性能、开发体验与创新特性的全面提升
这意味着,只要你使用了 Next.js 的 App Router,其底层实际上运行的是 React 19 的试验版本。
React Server Components 的实现原理如下:
开发者使用
use client标记需要在客户端运行的组件,未标记的默认视为服务端组件。所有组件都在服务端渲染。
客户端只重新渲染那些被标记为 client 的组件。
服务端将 VDOM 状态序列化,并与 HTML 一起发送到浏览器。
客户端根据 VDOM 状态 “跳过” 已完成渲染的服务端组件,避免重复计算。
从服务端加载数据
虽然 React 并未支持在客户端直接使用 await,但在服务端组件中完全没问题:
async function UserProfile({ userId }) {
const data = await getUserFromDb(userId);
return <UserProfileClient data={data} />;
}无需封装缓存,无需特殊处理,因为服务端组件只执行一次,不会重复运行。
这种在组件中进行 await 的能力,完全是由于 React 过去所做的决定才得以实现:
虚拟 DOM 用于在服务器上表示状态,而非依赖浏览器的 DOM。
Fiber's 暂停、停止、出错以及优先处理工作的能力
向服务端发送数据
从服务器获取数据解决了一个方向,但我们还需要一个方法将数据发送回服务端,这就是 Server Actions 的作用。
通过在服务端组件中声明 "use server" 指令,并将函数绑定到 <form action={handle}> 中:
async function handleLikePost(formData) {
"use server";
const postId = formData.get("postId");
const userId = formData.get("userId") || "anonymous-user";
await likePost(postId, userId);
redirect("/");
}使用方式如下:
<form action={handleLikePost}>
<input type="hidden" name="postId" value={post[0].id} />
<input type="hidden" name="userId" value="anonymous-user" />
<button type="submit">{post.likes} likes</button>
</form>即使用户禁用 JavaScript,也能正常提交数据,因为这利用的是浏览器原生表单的 action 提交机制。
在内部,这依赖于浏览器自带的 action API。虽然 React 版本的此 API 允许传递函数,但浏览器 API 则期望传入要调用的后端端点的 URL 以及相关的 formData 。
而且由于这是一个服务器组件(因为缺少 "use client" ),所以无论用户是否在浏览器中启用了 JavaScript,此服务器操作都将正常工作。
我们可以看到,浏览器的内置功能如何帮助确定了服务器操作 API 的设计 —— 这使得其功能比 React 团队在没有这种考虑的情况下自行搭建解决方案要强大得多。
双向数据同步:引入 useActionState
虽然可以提交数据了,但提交后我们还在用 redirect() 来刷新页面,这与 React 的 “无需刷新 UI” 理念相悖。
于是,我们使用 useActionState 实现响应式状态更新:
"use client";
import { useActionState } from "react";
export default function Post({ post }) {
const [state, action, isPending] = useActionState(handleLikePost, {
postId: post.id,
liked: !post.likedBy.includes("anonymous-user"),
totalLikes: post.likes,
});
return (
<form action={action}>
<input type="hidden" name="postId" value={post.id} />
<input type="hidden" name="userId" value="anonymous-user" />
<button type="submit" disabled={isPending}>
{state.totalLikes} likes
</button>
</form>
);
}
export async function handleLikePost(_prevState, formData) {
"use server";
const postId = formData.get("postId");
const userId = formData.get("userId") || "anonymous-user";
return await likePost(postId, userId);
}这样提交点赞后无需刷新页面,页面数据自动响应式更新。
超越基础 SSR:Next.js 的部分预渲染(PPR)
虽然不是 React 核心功能,但我们不能不提 Next.js 推出的 Partial Pre-rendering(部分预渲染)。
它的核心思想是:
静态内容缓存起来(首次渲染)
下一次请求时,先立即返回静态内容
动态内容在后台异步生成,随后补上
⏱️ 这样可以显著缩短首屏渲染时间,提升用户体验
PPR 的实现依赖于 React 能清晰区分「客户端」和「服务端」组件的机制,这再次验证了 React 构建边界的成功。
React 的未来
虽然我们已经介绍了目前为止发布的所有稳定特性,但 React 的未来仍然令人兴奋。接下来我们看几个前瞻性的实验功能。
保留隐藏状态:Activity API
React 新增的 <Activity> 组件,可以隐藏 DOM 节点的同时保留组件状态:
import { unstable_Activity as Activity, useState } from "react";
function Counter() {
const [count, setCount] = useState(0);
return <button onClick={() => setCount(count + 1)}>Count: {count}</button>;
}
export default function App() {
const [hide, setHide] = useState(false);
return (
<>
<button onClick={() => setHide((v) => !v)}>Toggle Count</button>
<Activity mode={hide ? "hidden" : "visible"}>
<Counter />
</Activity>
</>
);
}以前隐藏组件意味着状态丢失。现在你可以隐藏 DOM,但状态保留在 VDOM 中,稍后再 “复活”。
这对于带 Tab 页、切换视图等场景非常实用。
自动优化:React 编译器(Compiler)
React 正在开发编译器,可自动对代码进行性能优化(如自动缓存)。
虽然生成的代码人类可能不易阅读,但它更快、更高效。
前提是你严格遵循 React Hook 规则、使用 StrictMode、遵守 ESLint 指南。
其实,这并不是 React 团队第一次尝试。早在 2017 年,Facebook 就开发过一个叫 Prepack 的 JS 编译器,尝试在构建时优化代码(例如提前计算 fibonacci(10) 得到 55)。
而 React Compiler 的构想甚至早于 Hooks 的出现。React 团队在设计 Hook 的规则时,早已为未来的编译器做了准备。

当然,其他框架也有类似优化策略,比如:
Angular 的
runOutsideAngular、OnPushVue 的
v-once和v-memoSolid.js 的
createMemo
可见,不同框架虽然机制不同,但对性能的追求是一致的。
总结:React 的一贯哲学
纵观 React 的发展历程,我们可以清晰看到一条主线:
React 所有的新功能,无论多前沿,几乎都能回溯到早期的设计理念。
虚拟 DOM → 状态抽象
Hooks → 逻辑组合
Suspense → 异步流程控制
Server Components → 客户端 / 服务端解耦
Compiler → 自动化性能优化
这些功能之间彼此串联、互相支撑,从不孤立存在。
也正是这种连贯性与持续优化的精神,让 React 成为一个不断进化且始终实用的生态系统。
React 没有止步于过去,而是用清晰的目标指引未来。
关于本文
译者:@飘飘
作者:@Corbin Crutchley
原文:https://playfulprogramming.com/posts/react-history-through-code
最后
送人玫瑰,手留余香,觉得有收获的朋友可以点赞,关注一波 ,我们组建了高级前端交流群,如果您热爱技术,想一起讨论技术,交流进步,不管是面试题,工作中的问题,难点热点都可以在交流群交流,为了拿到大Offer,邀请您进群,入群就送前端精选100本电子书以及 阿里面试前端精选资料 添加 下方小助手二维码或者扫描二维码 就可以进群。让我们一起学习进步.
“在看和转发”就是最大的支持
















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









