




创作内容丰富的干货文章很费心力,感谢点过此文章的读者,点一个关注鼓励一下作者,激励他分享更多的精彩好文,谢谢大家!
一、面试题
在后端面试时,经常会被问到 volatile 关键字可以保证原子性吗?我们肯定知道是不能保证原子性的。那么接下来面试官会问,如何保证原子性呢?
二、解读synchronized
要想保证原子性,就要依赖于同步机制。在Java语言中提供了多种同步机制,例如synchronized关键字、Lock接口、Semaphore类、CountDownLatch类等。本文是介绍synchronized的底层原理,让我们先来看看synchronized学习大纲:
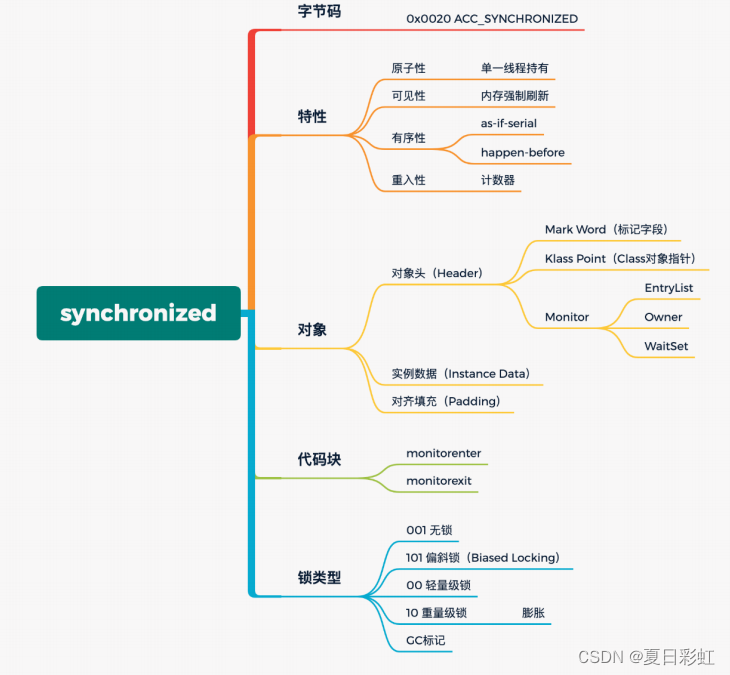
1. 对象结构
1.1 对象结构介绍
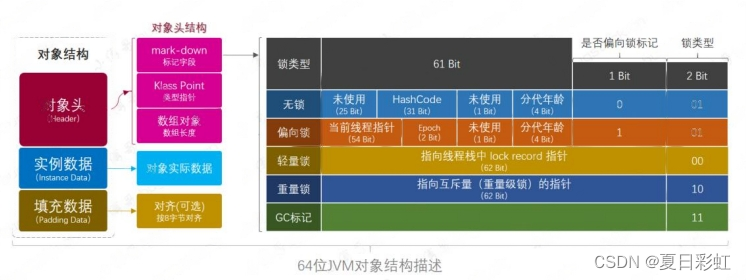
HotSpot 虚拟机 markOop.cpp 中的 C++ 代码注释片段,描述了 64bits 下mark-word 的存储状态,也就是上面的图的结构示意。
这部分的源码注释如下:
64 bits: -------- unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) size:64 ----------------------------------------------------->| (CMS free block) unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object) JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object) narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object) unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
源码地址:jdk8/hotspot/file/vm/oops/markOop.hpp
HotSpot 虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
-
mark-word:对象标记字段占 4 个字节,用于存储一些列的标记位,比如:哈希值、轻量级锁的标记位,偏向锁标记位、分代年龄等。
-
Klass Pointer:Class 对象的类型指针,Jdk1.8 默认开启指针压缩后为 4 字节,关闭指针压缩(-XX:-UseCompressedOops)后,长度为 8 字节。其指向的位置是对象对应的 Class 对象(其对应的元数据对象)的内存地址。
-
对象实际数据:包括对象的所有成员变量,大小由各个成员变量决定,比如:byte占 1 个字节 8 比特位、int 占 4 个字节 32 比特位。
-
对齐:最后这段空间补全并非必须,仅仅为了起到占位符的作用。由于 HotSpot 虚拟机的内存管理系统要求对象起始地址必须是 8 字节的整数倍,所以对象头正好是8 字节的倍数。因此当对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
另外,在 mark-word 锁类型标记中,无锁,偏向锁,轻量锁,重量锁,以及 GC 标记,5 种类中没法用 2 比特标记(2 比特最终有 4 种组合 00、01、10、11),所以无锁、偏向锁,前又占了一位偏向锁标记。最终:101 为无锁、001 为偏向锁。
1.2 验证对象结构
为了可以更加直观的看到对象结构,我们可以借助 openjdk 提供的 jol-core 进行打印分析。
引入 POM
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-cli</artifactId> <version>0.14</version> </dependency>
测试代码
public static void main(String[] args) {
System.out.println(VM.current().details());
Object obj = new Object();
System.out.println(obj + " 十六进制哈希:" + Integer.toHexString(obj.hashCode()));
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
1.2.1 指针压缩开启(默认)
运行结果
# Running 64-bit HotSpot VM. # Using compressed oop with 3-bit shift. # Using compressed klass with 3-bit shift. # Objects are 8 bytes aligned. # Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes] # Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes] java.lang.Object object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1) 4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) 8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243) 12 4 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 4 bytes external = 4 bytes total

-
Object 对象,总共占 16 字节
-
对象头占 12 个字节,其中:mark-down 占 8 字节、Klass Point 占 4 字节
-
最后 4 字节,用于数据填充找齐
1.2.2 指针压缩关闭
在 Run-->Edit Configurations->VM Options 配 置 参 数 -XX:-UseCompressedOops 关闭指针压缩。
运行结果
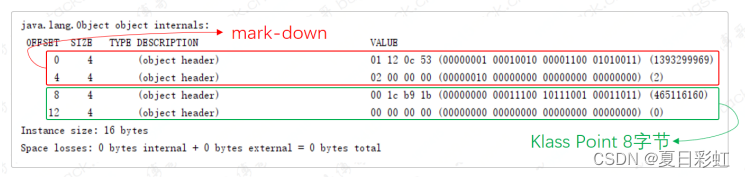
java.lang.Object object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 4 (object header) 01 12 0c 53 (00000001 00010010 00001100 01010011) (1393299969) 4 4 (object header) 02 00 00 00 (00000010 00000000 00000000 00000000) (2) 8 4 (object header) 00 1c b9 1b (00000000 00011100 10111001 00011011) (465116160) 12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0) Instance size: 16 bytes Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
-
关闭指针压缩后,mark-word 还是占 8 字节不变。
-
重点在类型指针 Klass Point 的变化,由原来的 4 字节,现在扩增到 8 字节。
1.2.3 对象头哈希值存储验证
接下来,我们调整下测试代码,看下哈希值在对象头中具体是怎么存放的。
测试代码
public static void main(String[] args) {
System.out.println(VM.current().details());
Object obj = new Object();
System.out.println(obj + " 十六进制哈希:" + Integer.toHexString(obj.hashCode()));
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
-
改动不多,只是把哈希值和对象打印出来,方便我们验证对象头关于哈希值的存放结果。
运行结果
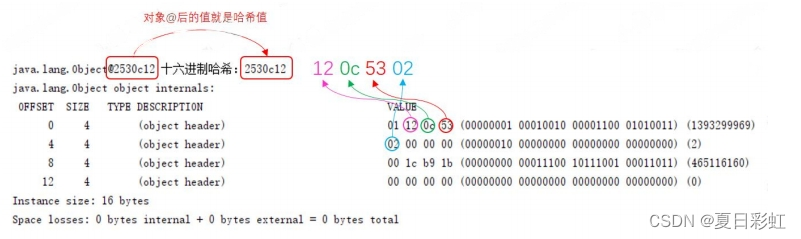
-
对象的哈希值是 16 进制的,即0x2530c12
-
在对象头哈希值存放的结果上看,也有对应的数值。只不过这个结果是倒过来的。
关于这个倒过来的问题是因为,大小端存储导致;
-
Big-Endian:高位字节存放于内存的低地址端,低位字节存放于内存的高地址端
-
Little-Endian:低位字节存放于内存的低地址端,高位字节存放于内存的高地址端
1.3 Monitor 对象
在 HotSpot 虚拟机中,monitor 是由 C++中 ObjectMonitor 实现。synchronized 的运行机制,就是当 JVM 监测到对象在不同的竞争状况时,会自动切换到适合的锁实现,这种切换就是锁的升级、降级。
那么三种不同的 Monitor 实现,也就是常说的三种不同的锁:偏斜锁(Biased Locking)、轻量级锁和重量级锁。当一个 Monitor 被某个线程持有后,它便处于锁定状态。
Monitor 主要数据结构如下:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录个数
_waiters = 0,
_recursions = 0; // 线程重入次数
_object = NULL; // 存储 Monitor 对象
_owner = NULL; // 持有当前线程的 owner
_WaitSet = NULL; // 处于 wait 状态的线程,会被加入到 _WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; // 单向列表
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁 block 状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
源码地址:jdk8/hotspot/file/vm/runtime/objectMonitor.hpp
-
ObjectMonitor,有两个队列:WaitSet、EntryList,用来保存ObjectWaiter 对象列表。
-
_owner,获取 Monitor 对象的线程进入 _owner 区时, _count + 1。如果线程调用了 wait() 方法,此时会释放 Monitor 对象, _owner 恢复为空, _count - 1。同时该等待线程进入 _WaitSet 中,等待被唤醒。
每个 Java 对象头中都包括 Monitor 对象(存储的指针的指向),synchronized 也就是通过这一种方式获取锁 ,也就解释了为什么synchronized() 括号里放任何对象都能获得锁!
2. synchronized 特性
2.1 原子性
原子性是指一个操作是不可中断的,要么全部执行成功要么全部执行失败。
案例代码
private static volatile int counter = 0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
for (int i1 = 0; i1 < 10000; i1++) {
add();
}
});
thread.start();
}
// 等 10 个线程运行完毕
Thread.sleep(1000);
System.out.println(counter);
}
public static void add() {
counter++;
}
这段代码开启了 10 个线程来累加 counter,按照预期结果应该是 100000。但实际运行会发现,counter 值每次运行都小于 10000,这是因为 volatile 并不能保证原子性,所以最后的结果不会是 10000。
修改方法 add(),添加 synchronized:
这回测试结果就是:100000 了!
因为 synchronized 可以保证统一时间只有一个线程能拿到锁,进入到代码块执行。
反编译查看指令码
javap -v -p AtomicityTest
public static void add(); descriptor: ()V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=2, args_size=0 0: ldc #12 // class com/ray/test/sync/AtomicityTest 2: dup 3: astore_0 4: monitorenter 5: getstatic #10 // Field counter:I 8: iconst_1 9: iadd 10: putstatic #10 // Field counter:I 13: aload_0 14: monitorexit 15: goto 23 18: astore_1 19: aload_0 20: monitorexit 21: aload_1 22: athrow 23: return Exception table: from to target type 5 15 18 any 18 21 18 any LineNumberTable: line 22: 0 line 23: 5 line 24: 13 line 25: 23 StackMapTable: number_of_entries = 2 frame_type = 255 /* full_frame */ offset_delta = 18 locals = [ class java/lang/Object ] stack = [ class java/lang/Throwable ] frame_type = 250 /* chop */ offset_delta = 4
2.2 可见性
在上一章节 volatile 篇中,我们知道它保证变量对所有线程的可见性。最终的效果就是在添加 volatile 的属性变量时,线程 A 修改值后,线程 B 使用此变量可以做出相应的反应,比如 while(!变量) 退出。
那么,synchronized 具备可见性吗,我们做给例子。
public static boolean sign = false;
public static void main(String[] args) {
Thread Thread01 = new Thread(() -> {
int i = 0;
while (!sign) {
i++;
add(i);
}
});
Thread Thread02 = new Thread(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException ignore) {
}
sign = true;
logger.info("vt.sign = true while (!sign)")
});
Thread01.start();
Thread02.start();
}
public static int add(int i) {
return i + 1;
}
这是两个线程操作一个变量的例子,因为线程间对变量 sign 的不可见性,线程Thread01 中的 while (!sign) 会一直执行,不会随着线程 Thread02 修改sign = true 而退出循环。
现在我们给方法 add 添加 synchronized 关键字修饰,如下:
public static synchronized int add(int i) {
return i + 1;
}
添加后运行结果:
23:55:33.849 [Thread-1] INFO org.itstack.interview.VisibilityTest - vt.sign = true while (!sign) Process finished with exit code 0
可以看到当线程 Thread02 改变变量 sign = true 后,线程 Thread01 立即退出了循环。
注意:不要在方法中添加 System.out.println() ,因为这个方法中含有**synchronized 会影响测试结果!
那么为什么添加 synchronized 也能保证变量的可见性呢?
因为:
-
线程解锁前,必须把共享变量的最新值刷新到主内存中。
-
线程加锁前,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值。
-
volatile 的可见性都是通过内存屏障(Memnory Barrier)来实现的。
-
synchronized 靠操作系统内核互斥锁实现,相当于 JMM 中的 lock、unlock。退出代码块时刷新变量到主内存。
2.3 有序性
as-if-serial,保证不管编译器和处理器为了性能优化会如何进行指令重排序,都需要保证单线程下的运行结果的正确性。也就是常说的:如果在本线程内观察,所有的操作都是有序的;如果在一个线程观察另一个线程,所有的操作都是无序的。
这里有一段双重检验锁(Double-checked Locking)的经典案例:
public class Singleton {
private Singleton() {
}
private volatile static Singleton instance;
public Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
为什么,synchronized 也有可见性的特点,还需要 volatile 关键字?因为,synchronized 的有序性,不是 volatile 的防止指令重排序。
那如果不加 volatile 关键字可能导致的结果,就是第一个线程在初始化初始化对象,设置 instance 指向内存地址时。第二个线程进入时,有指令重排。在判断 if (instance == null) 时就会有出错的可能,因为这会可能 instance 可能还没有初始化成功。
2.4 可重入性
synchronized 是可重入锁,也就是说,允许一个线程二次请求自己持有对象锁的临界资源,这种情况称为可重入锁。
那么我们就写一个例子,来证明这样的情况。
public class ReentryTest extends A{
public static void main(String[] args) {
ReentryTest reentry = new ReentryTest();
reentry.doA();
}
public synchronized void doA() {
System.out.println("子类方法:ReentryTest.doA() ThreadId:" + Thread.currentThread().getId());
doB();
}
private synchronized void doB() {
super.doA();
System.out.println("子类方法:ReentryTest.doB() ThreadId:" + Thread.currentThread().getId());
}
}
class A {
public synchronized void doA() {
System.out.println("父类方法:A.doA() ThreadId:" + Thread.currentThread().getId());
}
}
测试结果
子类方法:ReentryTest.doA() ThreadId:1 父类方法:A.doA() ThreadId:1 子类方法:ReentryTest.doB() ThreadId:1 Process finished with exit code 0
这段单例代码是递归调用含有 synchronized 锁的方法,从运行正常的测试结果看,并没有发生死锁。所有可以证明 synchronized 是可重入锁。
synchronized 锁对象的时候有个计数器,他会记录下线程获取锁的次数,在执行完对应的代码块之后,计数器就会-1,直到计数器清零,就释放锁了。
之所以,是可以重入。是因为 synchronized 锁对象有个计数器,会随着线程获取锁后 +1 计数,当线程执行完毕后 -1,直到清零释放锁。
3. 锁升级过程
关于 synchronized 锁升级有一张非常完整的图,可以参考:
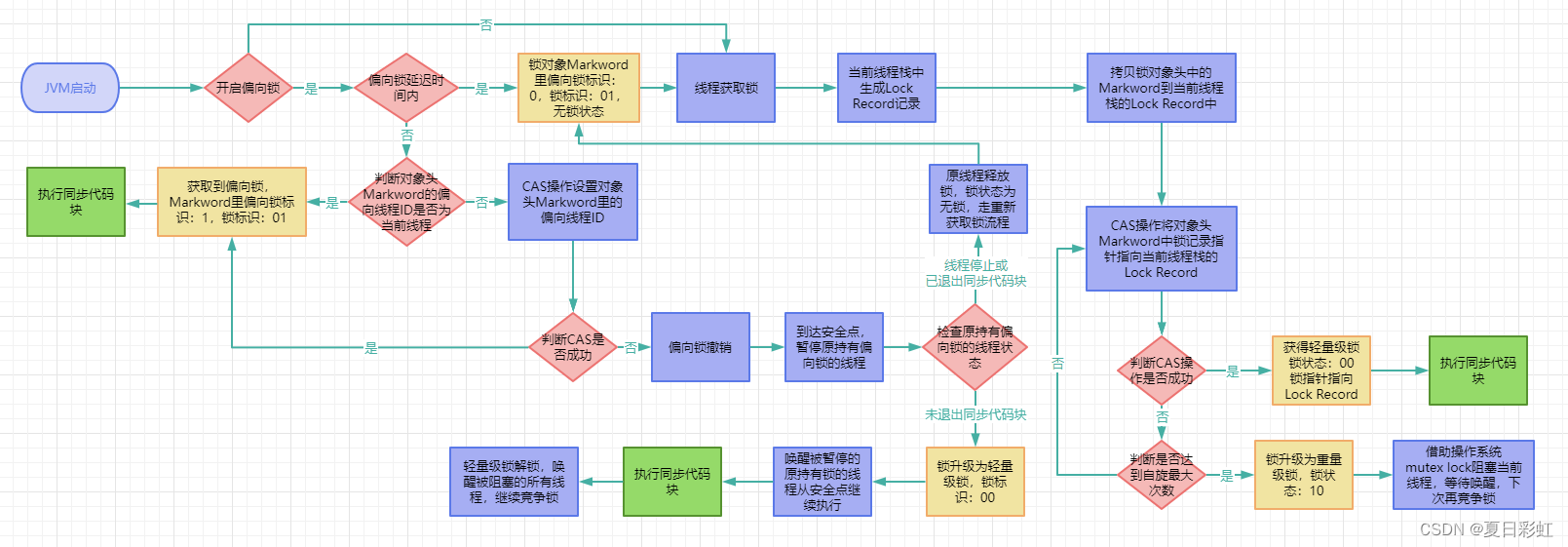
synchronized 锁有四种交替升级的状态:无锁、偏向锁、轻量级锁和重量级,这几个状态随着竞争情况逐渐升级。
3.1 偏向锁
synchronizer 源码:/src/share/vm/runtime/synchronizer.cpp
void ObjectSynchronizer::jni_exit(oop obj, Thread* THREAD) {
TEVENT (jni_exit) ;
if (UseBiasedLocking) {
Handle h_obj(THREAD, obj);
BiasedLocking::revoke_and_rebias(h_obj, false, THREAD);
obj = h_obj();
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
ObjectMonitor* monitor = ObjectSynchronizer::inflate(THREAD, obj);
// If this thread has locked the object, exit the monitor. Note: can't use
// monitor->check(CHECK); must exit even if an exception is pending.
if (monitor->check(THREAD)) {
monitor->exit(true, THREAD);
}
}
UseBiasedLocking 是一个偏向锁检查,1.6 之后是默认开启的,1.5 中是关闭的,需要手动开启参数是 XX:-UseBiasedLocking=false
偏斜锁会延缓 JIT 预热进程,所以很多性能测试中会显式地关闭偏斜锁,偏斜锁并不适合所有应用场景,撤销操作(revoke)是比较重的行为,只有当存在较多不会真正竞争的 synchronized 块儿时,才能体现出明显改善。
3.2 轻量级锁
当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),JVM 虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的 Mark Word 的拷贝,官方称之为 Displaced Mark Word。
3.3 自旋锁
自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗 CPU。自旋锁的默认大小是 10 次,可以调整:-XX:PreBlockSpin如果自旋 n 次失败了,就会升级为重量级的锁。重量级的锁,在 1.3 Monitor 对象中已经介绍。
3.4 锁会降级吗?
之前一直了解到 Java 不会进行锁降级,但最近整理了大量的资料发现锁降级确实是会发生。
When safepoints are used?
Below are few reasons for HotSpot JVM to initiate a safepoint:
Garbage collection pauses
Code deoptimization
Flushing code cache
Class redefinition (e.g. hot swap or instrumentation)
Biased lock revocation
Various debug operation (e.g. deadlock check or stacktrace dump)
Biased lock revocation,当 JVM 进入安全点 SafePoint 的时候,会检查是否有闲置的 Monitor,然后试图进行降级。
三、总结
-
本章关于 synchronized 锁涉及到了较多的 C++源码分析学习,源码地址:GitHub - JetBrains/jdk8u_hotspot
-
关于锁的细节挖掘除了本文提到的还有很多知识点可以继续学习,可以结合
ifeve、并发编程、深入理解 JVM 虚拟机,等系列知识整理。
-
学习过程中结合 C++源代码中关于锁的实现,更容易理解可能原本晦涩难懂的概念。在结合实际的案例验证,会容易接受这部分知识。
-
好了,这篇就写到这里了,如果有观点和文章不准确的表达欢迎留言,互相学习,互相扫盲,互相进步。


















 564
564




 到【灌水乐园】发言
到【灌水乐园】发言









