 GPT-3:大型语言模型的突破与挑战
GPT-3:大型语言模型的突破与挑战





GPT1
GPT-3
关于GPT-3的主要事实:
-
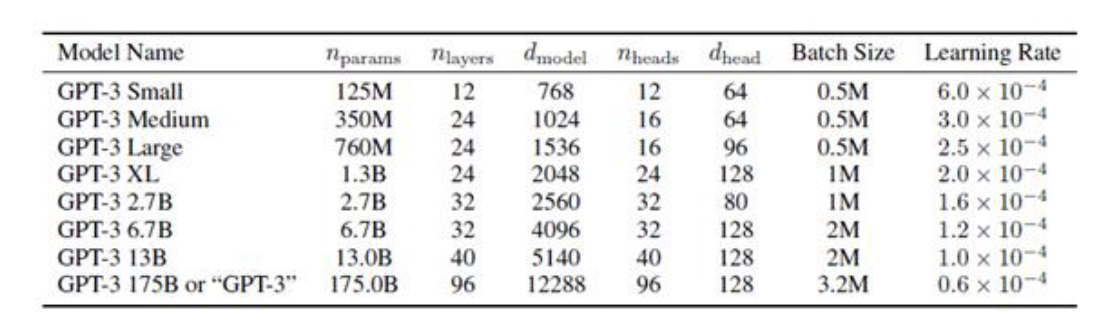
模型分类:GPT-3有8个不同的模型,参数从1.25亿到1750亿不等。
-
模型大小:最大的GPT-3模型有1750亿参数。这比最大的BERT模型大470倍(3.75亿个参数)
-
体系结构:GPT-3是一种自回归模型,使用仅有解码器的体系结构。使用下一个单词预测目标进行训练
-
学习方式:GPT-3通过很少的学习,学习时没有梯度更新
需要训练数据:GPT-3需要较少的训练数据。它可以从非常少的数据中学习,这使得它的应用程序可以用于数据较少的领域
关键假设:
- 模型规模的增加和对更大数据的训练可以导致性能的提高
- 单一模型可以在许多NLP任务上提供良好的性能。
- 模型可以从新数据中推断,不需要进行微调
- 该模型可以解决从未训练过的数据集上的问题。
早期的预训练模型-微调:
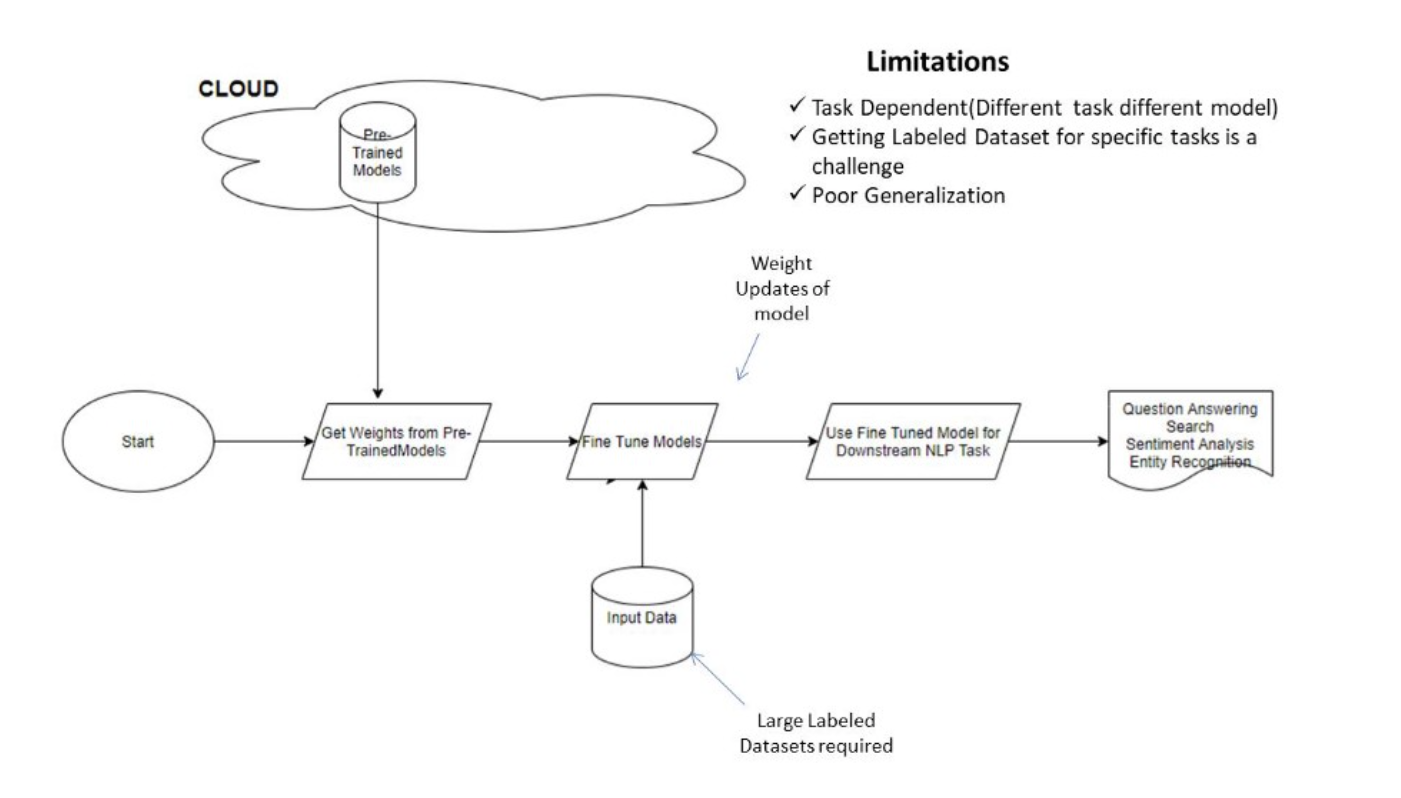
- GPT-3采用了不同的学习方法。不需要大量标记数据来推断新问题。
- 相反,它可以
不从数据(零次学习 Zero-Shot Learning )中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









