




 SGS(SunGameServerTechnology)是Sun公司推出的一种游戏服务器技术,旨在解决大型多用户在线游戏中的扩展性、容错性和持续性等问题。该技术通过提供一个简化的开发环境,使开发者能够专注于编写游戏逻辑,同时确保高带宽、低延迟和高可扩展性。
SGS(SunGameServerTechnology)是Sun公司推出的一种游戏服务器技术,旨在解决大型多用户在线游戏中的扩展性、容错性和持续性等问题。该技术通过提供一个简化的开发环境,使开发者能够专注于编写游戏逻辑,同时确保高带宽、低延迟和高可扩展性。
转自:http://hi.baidu.com/calls911/blog/item/89da50cdba807634f9dc615e.html
SGS(Sun Game Server Technology)是Sun公司的游戏服务器技术,这个白皮书的内容是一个技术简介,于2004年6月份发布。(原文地址:http://www.sun.com/solutions/documents/white-papers/me_sungameserver.pdf)
目录
1、内容概览
2、主要面向的开发人员
3、主要面向的应用程序
4、设计要点
5、游戏服务器架构
5.1 传统大型多用户游戏架构
5.2 无尽请求和行业现状
5.3 现存大型多用户游戏解决方案的问题
6、SGS技术
6.1 SGS架构
6.2 SGS技术的优点
7、结论
7.1 对于游戏开发者
7.2 对于游戏实施人员
8、获取更多信息
-------------------------------------------------------------------------------------------------------------------------------
正文
1、内容概览
Sun公司正在开发新的技术来满足低延时、高带宽、容错的、高可扩展性的仿真服务。即使是设计用于大型多用户的网络游戏的意图,这种技术也可以适用于任何对上述方面(低延时、高带宽、容错的、高可扩展性)有要求的地方。
2、主要面向的开发人员
使用这个仿真服务系统的主要人员应该是游戏开发者。与传统的java软件开发人员相比,游戏开发者通常有完全不同的一些列需要、技术和认知。
I.无线程知识。游戏开发者的世界是单线程、独立的、基于时间的仿真。因此,SGS技术不要求任何关于线程和线程相关问题的知识就能开发部署仿真程序。
II.无数据库知识。游戏开发者只是在一个赋予他们的“级”的开始加载所有他们需要的数据。(一级是玩家的持续性交互的一个单元。)他们没有处理事务、死锁、查询优化、或者其它超大数量的复杂数据库事务,而这些问题通常是企业开发人员要面对的。因此,对于这个系统很重要的一点是让所有的数据库交互对他们百分之百的透明。
III.极少的可扩展性系统架构经验。今天游戏界的扩展性解决方案仍然很原始、简单。一般来讲,玩家被分成各个小组,只有组内的成员才能相互交互。这些组的扩展性仍然被限制了,导致一个结果就是开发主观生硬地限制了可以一起交互的玩家的数量。这种限制性的程序设计方式限制了游戏的种类和可以进行的游戏操作。
SGS的一个优势就在于它从上述限制中释放了游戏开发人员的空间,使得游戏设计更具有灵活性和创造性。而要这样做,就必须消除那些限制性的手段,使得一切对于玩家都更透明。
3、主要面向的应用程序
游戏被属于近乎实时仿真软件的范围,因此有一些非常严格的性能要求。Sun公司的目标是支持大型多用户网游并满足极限的可扩展性和延时要求。要想成功,支持大型多用户网游必须满足以下挑战:
I.非常低的延时。在后台所有活动的总的延时,而非仅仅程序员的游戏代码的延时,在每一次交互时必须控制在几十毫秒的级别。
II.允许从几百到几万用户同时交互的扩展性。这个系统不但要能处理10000名以上玩家的同时交互,并且还要很经济地处理几百名玩家的同时交互。由于不同的游戏显然会有不同的速度增长曲线,必须有一种经济的方式满足玩家同时交互人数从一个小的数量向一个巨大的数量或快或慢地变化的要求。
4、设计要点
由开发特征决定的这些目标直接关系到SGS技术的设计要点。
I.简单应用模式。应用程序只有一个“世界”,里面是一系列的仿真对象。这些对象有各自的方法,方法被调用就可以执行相应的动作。
II.自动执行模式。仿真对象在如下情况下被调用:事件驱动、验证步骤、验证死锁、容错方式。对象争夺和错误处理的所有问题都会被这个模式处理并且都对仿真对象的编码透明。
III.持续透明存在模式。当前得到的仿真对象的所有细节,包括执行、完成调用、保存结果都被这个模式所处理。游戏的每个动作在完成期间都是持续存在的。
IV.透明极大可扩展模式。仿真对象的执行是透明的一个伸展,它们放在一个线性可扩展数组中由相互独立的进程控制,每个进程有独立的内存空间——进程的数量可以很少也可以是个极大数。
5、游戏服务器架构
5.1 传统大型多用户游戏架构
只有熟悉以前的状况,才能更好的理解SGS技术。那些对现存的传统大型多用户游戏架构熟悉的人可以跳过这一段。
5.2 无尽请求和行业现状
今天的大型多用户游戏一般设计为有成千上万的同时在线的玩家,需要一个中央服务器环境,而游戏的运算则由一个分布式的主机群来多重处理。这些游戏,最多的部分,是基于一个无尽访问请求的软件架构。游戏被显式地分成不同区域,每个区在它自己的服务器上跑它自己的服务,管理它自己的内存空间状态。
玩家要想登陆游戏必须先连接到一个登陆服务器。一旦登陆完成之后,客户端就被连接到其中一个区的服务器,而从登录服务器断开。如果是个新玩家,他可以选择一个开始游戏的服务器,而老玩家则要登录到他之前已经选定了的那个服务器。当玩家从一个区到另一个区的时候,他们的当前连接就断开了,必须重新连接到新的区。
5.3 现存大型多用户游戏解决方案的问题
I.可扩展性限制
区域中仍然有人数限制,在同一时间在线的玩家数量有一个上限。当在线玩家数达到上限之后,那么除非有玩家离开,否则不能再有玩家进入游戏了。这就在这种模式可以支持的玩家数量上面加了一个绝对上限。
索尼公司解决这个问题的办法是继续大量细分整个服务系统。(索尼把每一个细分称为一个碎片,碎片已经成为行业内细分型MMP【massively multiplayer,大型多用户】游戏界所熟知的一个词语了。)然而,问题在于解决扩展性就成了基于细分用户数量了,先分成区,然后再细分成碎片。这样做不但增加了用户的成本,而且使得每个碎片内的在线用户数被更加严格地限制了。更进一步,在一个满员的碎片中的玩家不可能带动他的朋友来玩,因为他们根本无法在一起游戏。
II.低容错
碎片模式的容错性并不好。如果这个碎片的服务器当机了,那么玩家就掉线了,直到机器重启。而如果这个区的服务器当机了,那么整个区的玩家都只能坐等服务器恢复正常。
III.低效的进程处理
分区模式只有当人们的在线数量曲线自然呈现为高斯分布的时候才可以完美地均衡负载。不幸的是,事实显然不是如此。我们是社会动物,而社会动物是抱团的。
结果就是经常有机器进程处于闲置状态的同时,少数服务器超负荷运转。更进一步,加载特定的区的进程可以使机器从零负载一下到满负荷,所以你不可以把多个服务器的进程放到一个中心CPU上。每一个进程都必须可以在任何时间实现满负荷运转。这样就造成了大量处理器浪费。
IV,持续性限制
一般来讲,从硬盘提取出来加载到内存中的影像应该只是玩家当前状态所需的。分区模式因此是高度静止的;它们不能改变几何形状因为要随时重新加载原来的几何形状以备不时之需(任何时间的错误)。一个分区的物体目录(目录是指那些玩家或BOSS掉落的物品,以及地上的尸体)在服务器重启进程时都会消失。怪物作为一个分区进程中游戏运行的一部分又复活了,一切又重新开始了。
而游戏玩家的状态在服务器瘫痪的时候一般会损失15分钟左右,因为系统备份的时候只会停下来保存备份时刻的状态。更严重的情况下,为了修复角色的错误需要24小时以上时间。
6、SGS技术
SGS技术从根本上改变了开发大型多用户游戏的状况。它解决了所有扩展性、容错性游戏内容持续性等方面的问题,展现给开发人员的是独立的、事件驱动的、单线程的编程环境。使用了SGS环境运行的游戏,自动地扩展到多个处理器上,自动保持游戏内容并容错。
6.1SGS架构
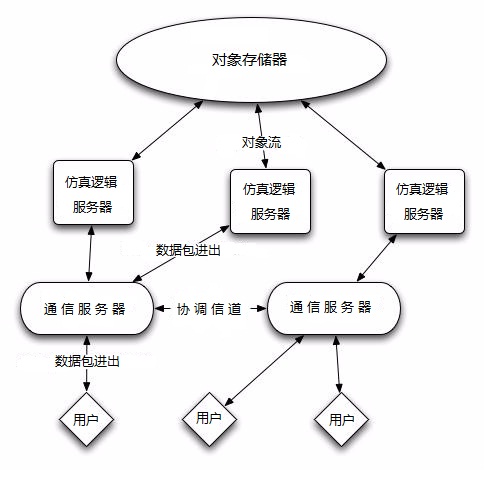
SGS技术在逻辑上垂直分为三层:通信层、仿真逻辑层和对象存储层。
I.对象存储层包括所有当前在游戏服务器上运行的全部游戏的所有状态。它是一个非常高效(每个操作仅需十分之几毫秒)、可扩展的、容错的,容错包括对于交易数据库层对仿真对象的死锁能够验证,有可能是一个写入的锁,也可能是不可重复的查询(相同的语句但信息已改变)。
II.仿真逻辑层的职责是执行实际的游戏代码。在这一层许多事件依次轮流地核查对象存储层的对象是否有需要,进而触发任务创建。当一个任务完成后,这个对象被更新并被返回到对象存储层。
III.通信层组织所有玩家的通信过程,把他们放到成组的通信器的信道中去。它负责管理数据包和仿真逻辑之间、玩家们之间的路由。它也负责网络上各种通信协议的转换翻译(例如通过HTTP协议收发电话语音)。
6.2 SGS技术的优点
I.极致的扩展性
通过使用一个高效的,可扩展的普通对象存储仓库来存储游戏数据,SGS技术消除了划分游戏区域的边界,放弃了细分游戏的分区和碎片。游戏可以以一种独立、统一、完全合乎逻辑的环境建立,可以支持成千上万名玩家同时在线。开发人员可以持续地修改、扩充游戏内容,同时部署人员能够迅速地扩展服务器数量来满足增长的需求,而这些都不会影响到在线用户的游戏进程。
II.高容错性
当一个仿真逻辑服务器或通信服务器当机的时候,游戏的事件和玩家到游戏的联线会被自动地重新分配到其它服务器上,消除了一般情况下一旦登录服务器和区域服务器错误就会产生的当机时间。这种当机时间是当前游戏服务器存在的客户普遍抱怨的固定问题。
III,最大的处理器效率
由于负载的分配是基于玩家的活动而不是分区,SGS技术可以自动实现负载均衡,并且不单只一个游戏,只要基于一个数据中心即便是多个游戏也可以。这一点彻底地减少了多余的、后备的、空闲的服务器资源的消耗。
IV.完整的持续性
通过SGS技术,所有的对象——不只是玩家状态——都有可靠的持续性。这给开发人员提供了极大的灵活性来创造高动态的环境,还能消除玩家遇到瞬间发生的服务器错误和实施错误而产生的郁闷。使得玩家满意度和客户忠诚度提高。
7、总结
7.1 对于游戏开发者
SGS技术给大型多用户游戏的开发者提供了一个彻底简化的开发模型。同时,它提供了强度类似于JAVA企业级产品的容错性和扩展性。通过使用这个游戏服务器,游戏开发者被从服务器端的所有困扰人的问题中解放出来,可以去做他/她最擅长的东西——编写伟大的游戏逻辑。
7.2 对于游戏实施人员
SGS技术可以安全地支持同时跑多个不同的游戏逻辑。这个架构可以自动实现同时运行一个游戏或多个游戏的负载均衡。这给游戏中心带来极大的CPU效率,尤其是当多款游戏由一个服务供应商运营时。
所有游戏公用一个仿真后端,这个后端包括共享的管理需求,所以可以由一个管理团队来负责所有的游戏。JAVA技术开发标准保证了游戏逻辑很安全地被包含其中而不会影响网络环境的其他部分。由于支持实施人员在未来于当前后端部署新的游戏,它也保护了投资利益。
8、获取更多信息
如果你对了解更多这项技术的内容感兴趣,或打算把它应用于你的网络游戏开发计划,请通过这个邮箱地址联系我们:gametech@sun.com。

















 8443
8443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









