




 本文详细介绍R语言中tidyverse系统的数据处理方法,包括数据筛选、随机抽样、重复行去除、缺失值处理、列选择、排序、变量名修改、新变量计算、数据分组汇总及长宽表转换等,适合数据科学与统计分析人员学习。
本文详细介绍R语言中tidyverse系统的数据处理方法,包括数据筛选、随机抽样、重复行去除、缺失值处理、列选择、排序、变量名修改、新变量计算、数据分组汇总及长宽表转换等,适合数据科学与统计分析人员学习。
R数据处理
(学习资料参考北京大学李东风老师《R语言教程》)
27 数据整理
27.1 tidyverse系统
首先载入tidyverse 包,则magrittr包,readr包,dplyr包和tidyr包都会被自动载入:
library(tidyverse)
结果如下:
下面的例子中用如下的一个班的学生数据作为例子, 保存在如下class.csv文件中,读入为tibble (tibble是数据框类型的改进,readr包的read_csv()会生成此类)
d.class <- read_csv(
"class.csv",
col_types=cols(
.default = col_double(),
name=col_character(),
sex=col_factor(levels=c("M", "F"))
))
27.2 用filter()选择行子集
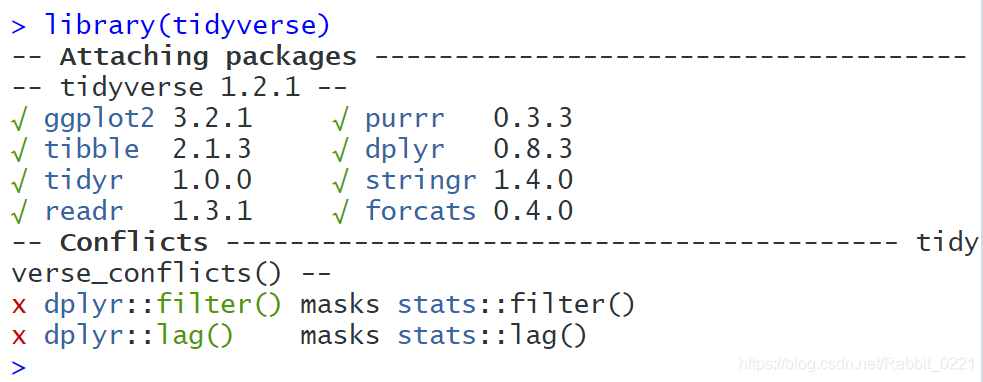
依旧使用上面的class文件,选出年龄在13岁和13岁以下的女生:
d.class %>%
filter(sex=="F", age<=13) %>%
knitr::kable()
得到结果如下:
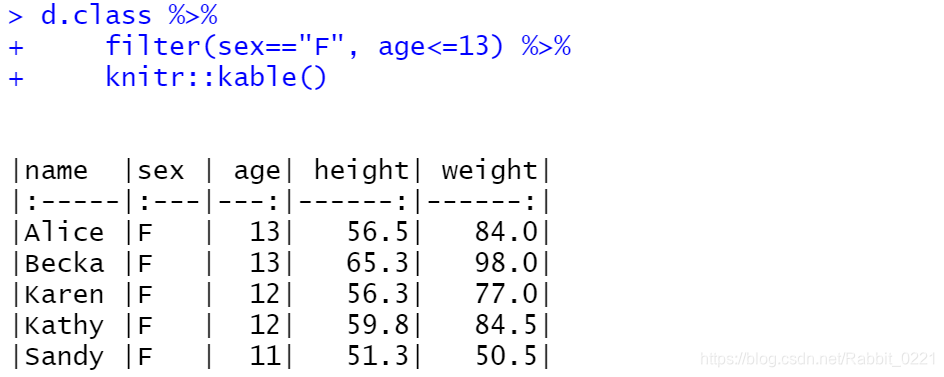
同理,可以选择年龄再13岁以上的男孩:
d.class %>%
filter(sex=="M", age>13) %>%
knitr::kable()
filter() 会自动舍弃行名, 如果需要行名只能将其转换成数据框的一列。
filter() 的结果为行子集数据框。 用在管道操作当中的时候第一自变量省略(是管道传递下来的)。
- 函数
head(x, n)可以用来选择数据框x前面n行,tail(x, n)可以用来选择数据框x后面n行,如,尝试取表格的前4行:
d.class %>%
head(n=4) %>%
knitr::kable()

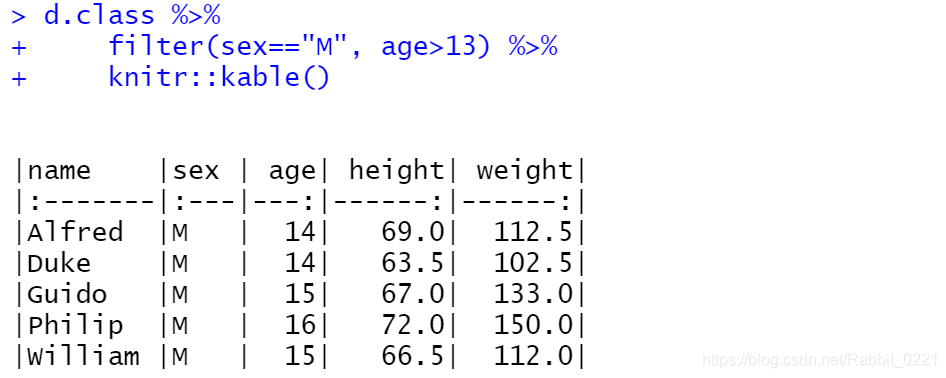
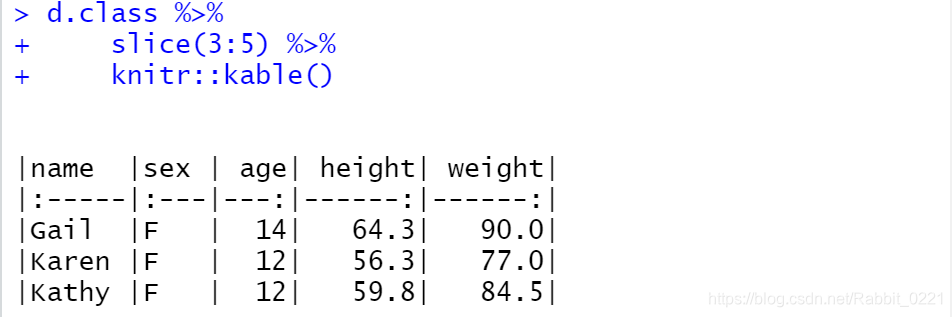
- dplyr包的函数
slice(.data, ...)可以用来选择指定序号的行子集, 正的序号表示保留,负的序号表示排除。如:
d.class %>%
slice(3:5) %>%
knitr::kable()
27.3 用sample_n()对观测随机抽样
dplyr包的sample_n(tbl, size)函数可以从数据集tbl中随机无放回抽取size行,如:
d.class %>%
sample_n(size = 3) %>%
knitr::kable()
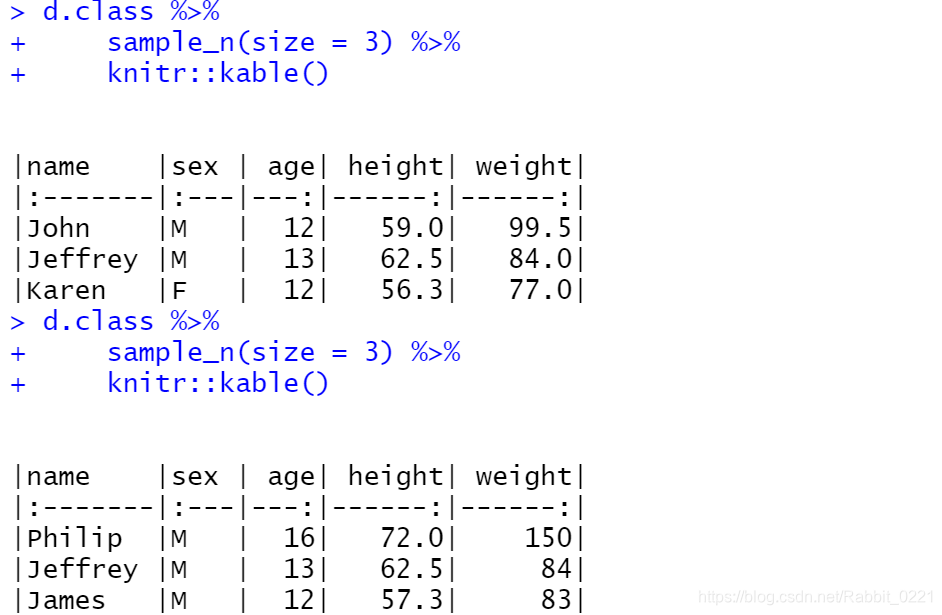
(从以上可以看出,的确是随机抽取,每次的结果并不相同)
27.4 用distinct()去除重复行
有时我们希望得到一个或若干个变量组合的所有不同值。 dplyr包的distinct()函数可以对数据框指定若干变量, 然后筛选出所有不同值, 每组不同值仅保留一行。
指定变量名时是写成字符串形式而是直接写变量名, 这是dplyr和tidyr包的特点。 例如,筛选出性别与年龄的所有不同组合:
d.class %>%
distinct(sex, age) %>%
knitr::kable()

再看一下有什么性别?

年龄呢?

可以知道distinct() 函数的作用。
27.5 用drop_na()去除指定的变量有缺失值的行
在进行统计建模时, 通常需要用到的因变量和自变量都不包含缺失值。 tidyr包的 drop_na()函数可以对数据框指定一到多个变量, 删去指定的变量有缺失值的行。 不指定变量时有任何变量缺失的行都会被删去。
在这里只把代码放上,由于上面使用的class文件都没有缺失值,所以看不出效果:
d.class %>%
drop_na(age, height, weight)
27.6 用 select() 选择列子集
dplyr包的 select() 选择列子集,并返回列子集结果。
可以指定变量名,如:
d.class %>%
select(name, age) %>%
knitr::kable()
这样出来的结果就只有name和age两列。
还可以用冒号表示范围,如:
d.class %>%
select(age:weight) %>%
knitr::kable()
这样出来的结果就是age到weight的列。
还可以用数字表示列的范围,如:
d.class %>%
select(3:5) %>%
knitr::kable()
这样出来的结果就是第3列到第5列的结果。
参数中前面写负号表示扣除,如:
d.class %>%
select(-name, -age) %>%
knitr::kable()
这样出来的结果就是除了name和age以外的列。
另外,select() 有若干个配套函数可以按名字的模式选择变量列, 如:
- starts_with(“se”): 选择名字以“se”`开头的变量列;
- ends_with(“ght”): 选择名字以“ght”`结尾的变量列;
- contains(“no”): 选择名字中含有子串“no”`的变量列;
- matches("1+[[:digit:]]+$"), 选择列名匹配某个正则表达式模式的变量列, 这里匹配前一部分是字母,后一部分是数字的变量名。
- num_range(“x”, 1:3),选择x1, x2, x3。
- everything(): 代指所有选中的变量, 这可以用来将指定的变量次序提前, 其它变量排在后面。
27.7 用arrange()排序
dplyr包的 arrange() 按照数据框的某一列或某几列排序, 返回排序后的结果,如:
d.class %>%
arrange(sex, age) %>%
knitr::kable()
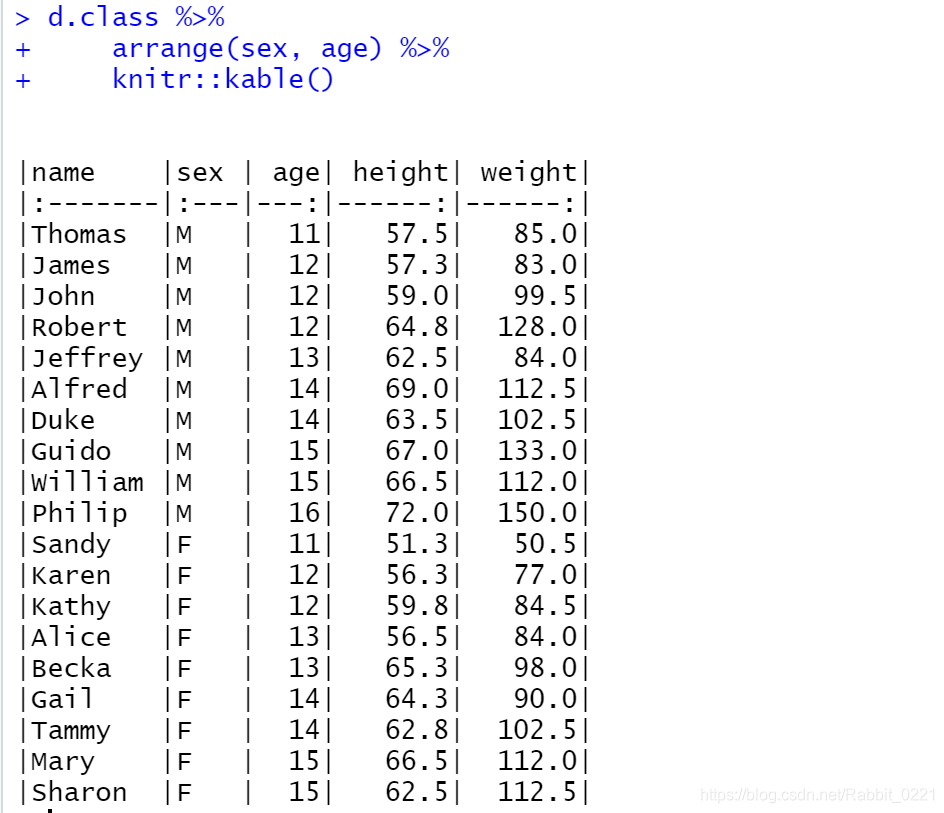
通过以上结果可以看出,得到的结果是先按照sex排序,在sex中按照age排序。如果sex中age需要降序怎么办呢?用desc()包裹想要降序排列的变量,试一下:
d.class %>%
arrange(sex, desc(age)) %>%
knitr::kable()
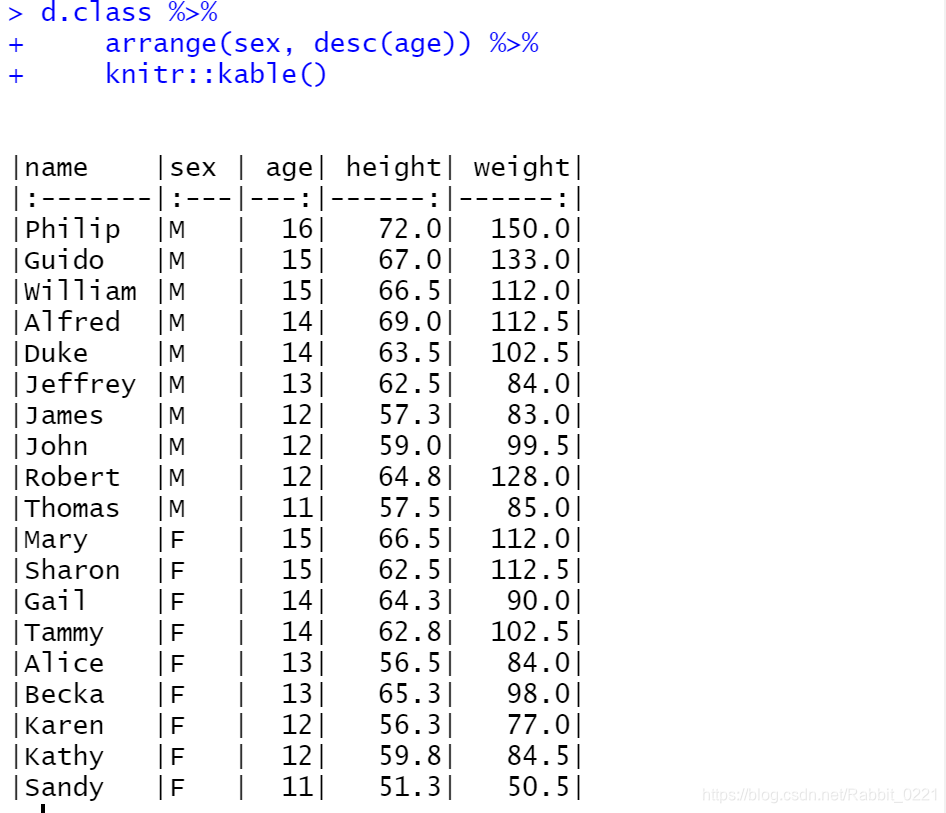
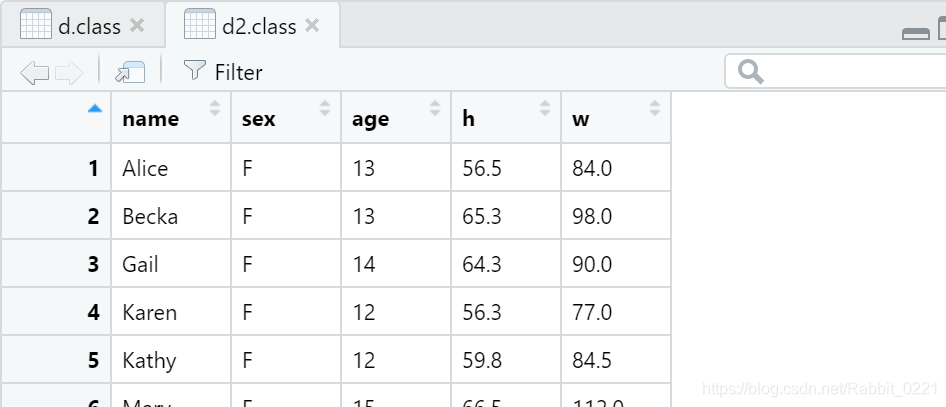
27.8 用rename()修改变量名
可以看出,一些列的名字太长,我们可以使用rename重新命名,如下:
d2.class <- d.class %>%
rename(h=height, w=weight)
这样,就出现了第二个class表格,里面的列名得到了改变:
27.9 用mutate()计算新变量
dplyr包的mutate()可以为数据框计算新变量, 返回含有新变量以及原变量的数据框。
下面我们计算体重和身高的比,并且把性别用男/女来表示:
d.class %>%
mutate(
rwh=weight/height,
sexc=ifelse(sex=="F", "女", "男")) %>%
knitr::kable()
计算公式中可以包含对数据框中变量的统计函数结果,如:
d.class %>%
mutate(
cheight = height - mean(height)) %>%
knitr::kable()
结果就会多出一个新的cheight变量,计算过程如上。mean可以直接进行计算。
27.10 用管道连接多次操作
管道运算符特别适用于对同一数据集进行多次操作。 例如,对t.class数据,先选出所有女生, 再去掉性别和age变量:
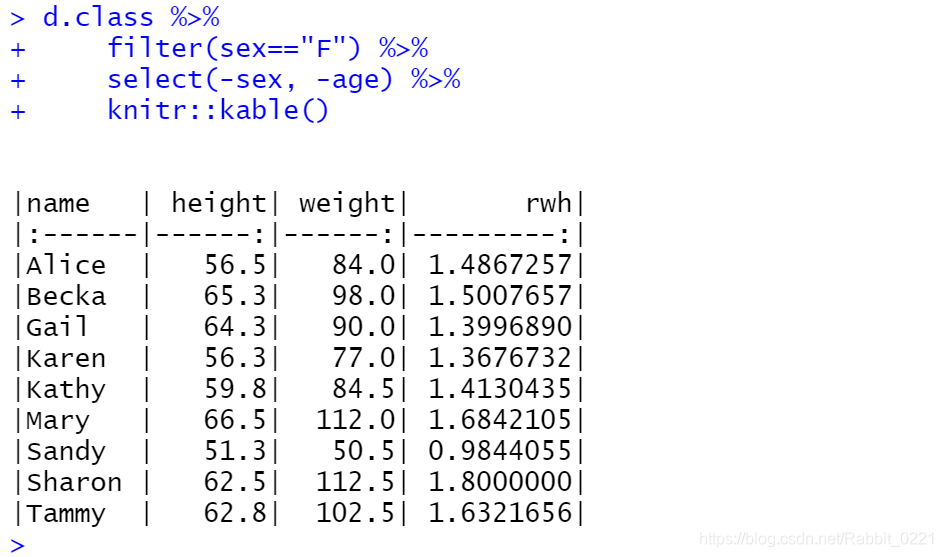
d.class %>%
filter(sex=="F") %>%
select(-sex, -age) %>%
knitr::kable()
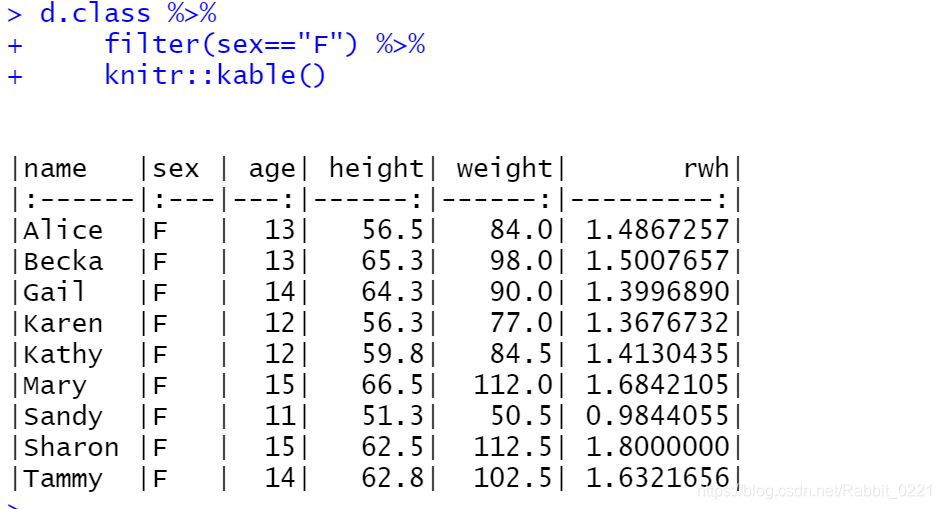
分解一下步骤看看,先选出所有的女生:
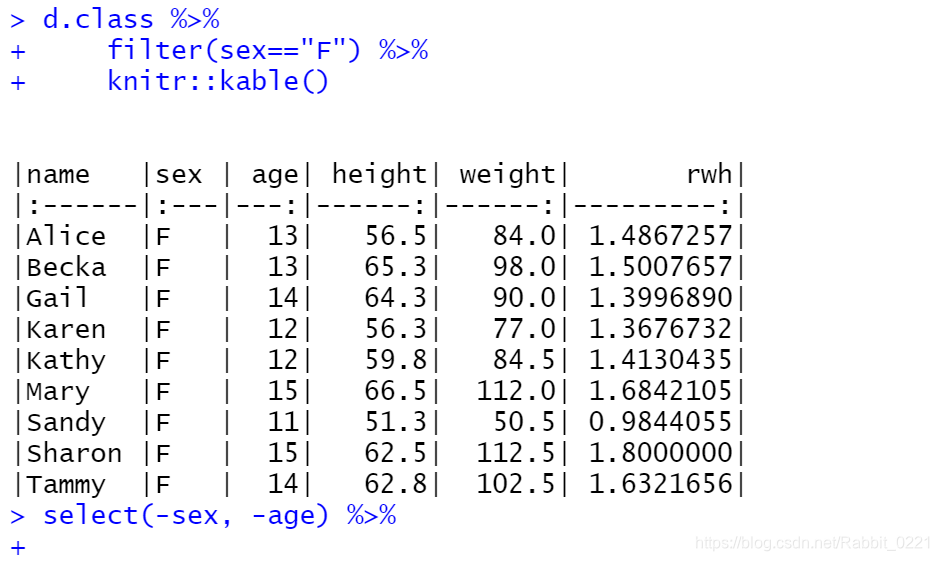
然后再去除sex和age变量,得到的是上面的结果。记住,R语言中不会记忆你上次做的,所以代码要放在一起,如下是不可以的,要重新放在一起进行运行。
27.11 数据分组汇总
看一下,原网页给定的代码是上面的,出现了报错。修改以后正常运行~
求出年龄age的平均值和标准差:
首先要先导入tidyverse系统,所以第一遍报错了

第二次就完成了

接下来进行分组汇总。 dplyr包的 group_by() 函数对数据框(或tibble)分组, 随后的 summarise() 将按照分组汇总。 比如, 按不同性别计算人数与年龄平均值:
d.cancer %>%
group_by(sex) %>%
summarise(
count=n(),
mean.age=mean(age, na.rm=TRUE)) %>%
knitr::kable()
其中n()计算某类的观测数(行数),以下说明,性别是F,观测行数有13行,平均年龄是66.14286;性别是M,观测行数有21行,平均年龄是63.25000。
下面列出常用的汇总函数:
- 位置度量:
mean(),median()。 - 分散程度(变异性)度量:
sd(),IQR(),mad()。 - 分位数:
min(),max(),quantile()。 - 按下标查询,如
first(x)取出x[1], last(x)取出x的最后一个元素, nth(x,2)取出x[2]。 可以提供一个缺省值以防某个下标位置不存在。 - 计数:n()给出某个组的观测数,
sum(!is.na(x))统计x的非缺失值个数,n_distinct(x)统计x的不同值个数(缺失值也算一个值)。count(x)给出x的每个不同值的个数(类似于table()函数)。
27.12 长宽表转换
不知道为什么,27.12.1和27.12.2都没有跑成功,但是下面两个都是对的。
[:alpha:] ↩︎

















 4132
4132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









