




目录
基础知识
汇编语法
Demo
基本程序
debug

我给 Go 的 1.11 提交了这几个项目,第一个是 Hashmap 优化,就是你们常用的 map 操作里面最费时的哈希值计算优化。VDSO,虚拟动态对接的 syscall,主要是优化系统时间调用。Md5、Chacha20就不说了。还有一个 Duffcopy,这是给编译器展开优化用的,它在 arm64平台优化得不是很好,所以我也做了优化。除了 Chacha20还没有完成外,其他的都已经在 Go master 上可以用到了。可能有些人会觉得为什么都是 arm64 平台的优化?其实就是 Go 官方团队维护了 X86-64,已经优化得很好,我就不要搀和了,就挑了一个比较新的平台,arm64。
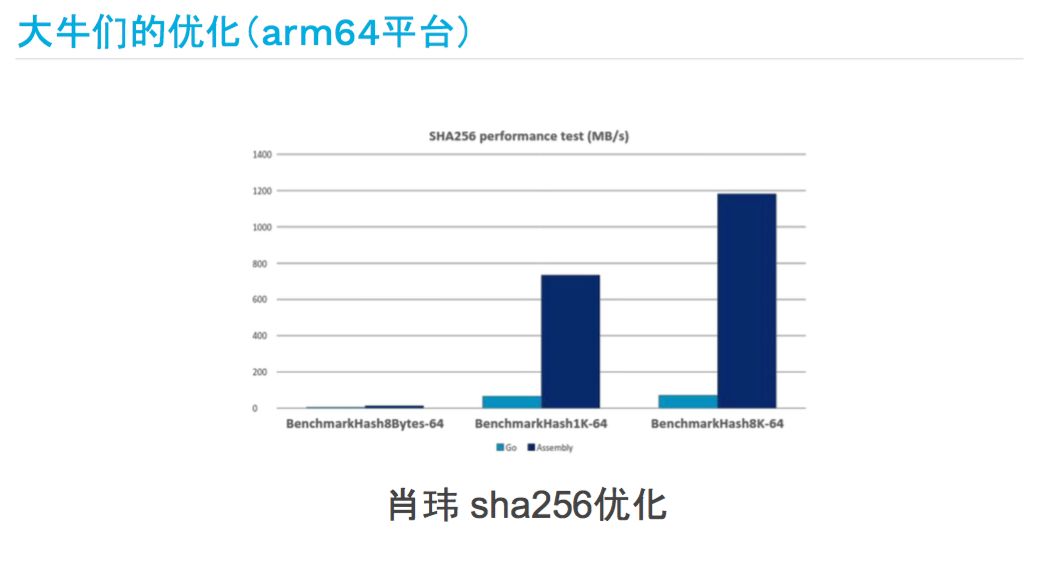
国内 arm 公司的大牛肖玮带领他的团队也在做 Go 相关的优化,比如 sha256,提升的效率有 16倍。国外的也有,Cloudflare,做CDN的公司,他们有一个密码学大牛弗拉德做了一些优化,也在 Go 的1.11里面合进去了,优化的效率是多少呢?
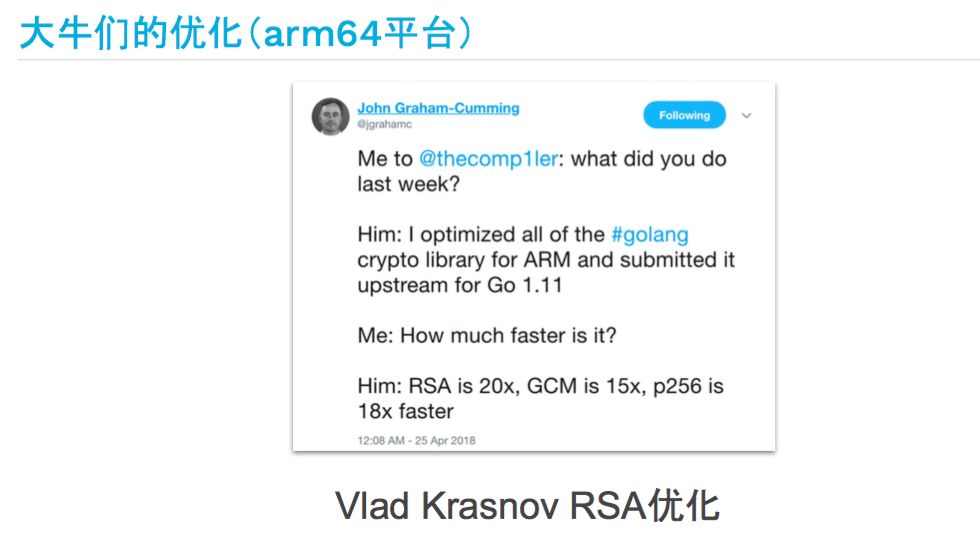
这是他们的CTO转发的推,CTO问他上周优化了一些什么东西呢?他说他优化了一些Go的库,RSA 性能有20倍,AES-GCM有15倍,P256有18倍。看了这些大牛优化以后有这么好的性能提升,是不是很心动啊?这次演讲就是教大家入门汇编优化,怎么做十几倍的加速。
1. 基础知识
所以怎么跑得那么快?就要知道干什么。 总结下来有三点,减少读写,并行操作,硬件加速。
1.1 减少读写
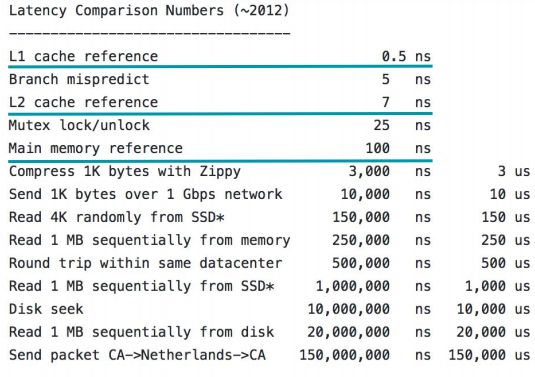
上图是谷歌的 Jeff Dean 分享的《程序员应该知道的延迟》,这个延迟是什么延迟呢?比如数据从CPU L1里面挖出来的速度,在2012年的时候是0.5ns,CPU L2里面是7ns;储存,也就是我们常说的内存里面拉出来是100ns。大家有没有发现每多一层就是10倍的性能下降,所以你要尽量少用内存的操作,多用寄存器。还有,CPU访问内存的时候有一个小窍门,把这个对齐再访问,CPU会执行得更快一些。这些都是基本知识,大家可以百度、Google 一下,不展开。
1.2 并行操作
业内叫做并行操作SIMD,就是单一指令多个数据进行操作。比如一般的加法操作,一次性只能加一个数,但是你要是用上一些向量指令集,就可以一次性操作8个、16个、32个,意味着相同的时间内能操作数据就更多,也就更快,这是很自然的事情。
1.3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









