




题目来自华为Talent官网《华为ICT大赛 - 云赛道学习空间(中国区)》,如有侵权,请及时联系本人删除文章。
非官方解析,仅供参考。
数据是我自己造的,大概看看就好。
我RDS用的阿里云,华为云的RDS操作差不多的
任务一:MySQL数据预处理
子任务1-3我就跳过了,一直点点点就行了
子任务4:多表连接查询
a.把三个表连起来查询并将查询结果保存为新的data表。
题目要求的字段如下:

根据date字段进行多表连接
CREATE TABLE `data` (
`date` varchar(50) NOT NULL,
`confirmed` int(11) NOT NULL,
`recivered` int(11) NOT NULL,
`deaths` int(11) NOT NULL,
`Province/State` varchar(50) NOT NULL,
`Country/Region` varchar(50) NOT NULL
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;
# 上面这一段是因为阿里云的RDS不支持create table XXX select XXX语法
# 我不知道华为云是否支持
# 如果支持的话可以直接把下面那句insert into `data`换成create table `data`
insert into `data`
SELECT c.`date` as 'date',
c.confirmed as confirmed,
r.recovered as recivered,
d.deaths as deaths,
c.`Province/State`,
c.`Country/Region`
from
confirmed as c
join recovered as r
on c.`date`=r.`date`
join deaths as d
on r.`date`=d.`date`;

b.从data表查询国家是xxxxxxx的数据并将查询结果保存为新的mysql_result表。
CREATE TABLE `mysql_result` (
`date` varchar(50) NOT NULL,
`confirmed` int(11) NOT NULL,
`recivered` int(11) NOT NULL,
`deaths` int(11) NOT NULL,
`Province/State` varchar(50) NOT NULL,
`Country/Region` varchar(50) NOT NULL
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;
insert into `mysql_result`
select * from `data`
where `Country/Region` in ('Australia','China','France','US','United Kingdom');
 任务2:创建Hive数据库和表并从HDFS导入数据
任务2:创建Hive数据库和表并从HDFS导入数据
子任务1跳过
子任务2:在Hive中创建数据库和外部表并导入数据
a.用beeline命令进入Hive命令行;创建ict_bigdata数据库;查看所有数据库;切换到ict_bigdata数据库。
nohup hive --service metastore &
nohup hiveserver2 &
beeline -u jdbc:hive2://<主机名>:10000 -n root

create database ict_bigdata;
show databases;

b.在ict_bigdata数据库中创建一个obs_covid19外部表,字段已给出。

use ict_bigdata;
CREATE EXTERNAL TABLE obs_covid19 (
`date` String,
confirmed Int,
recivered Int,
deaths Int,
`Province/State` String,
`Country/Region` String
)
row format delimited
fields terminated by ','
stored as textfile
location '/user/ict';

c.使用Hive命令将HDFS中的mysql_result.csv文件导入到外部表obs_covid19中,导入成功后查看表前30行数据。
load data inpath '/user/ict/mysql_result.csv' into table obs_covid19;
select * from obs_covid19 limit 30;

任务3:构建分层模型和统计分析
子任务1:Hive数据查询
a.在ict_bigdata数据库中创建dwd_covid19数据表,字段已给出。
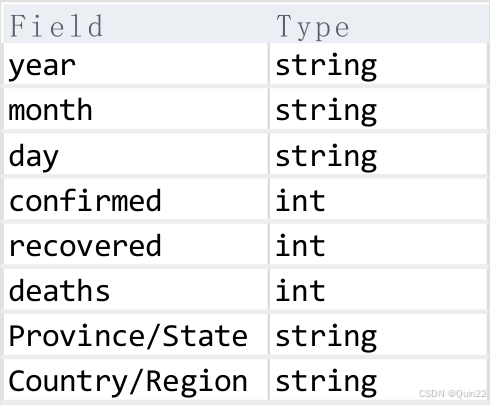
create table dwd_covid19(
year String,
month String,
day String,
confirmed Int,
recivered Int,
deaths Int,
`Province/State` String,
`Country/Region` String
);
b.切割date列,将切割查询结果存入dwd_covid19表。
insert into table dwd_covid19
select
split(`date`,'/')[0] as year,
split(`date`,'/')[1] as month,
split(`date`,'/')[2] as day,
confirmed,
recivered,
deaths,
`Province/State`,
`Country/Region`
from obs_covid19;

c.在ict_bigdata数据库中创建dws_monthly_confirmed数据表,字段已给出。

create table dws_monthly_confirmed (
year String,
month String,
`Country/Region` String,
monthly_confirmed int
);
d.从dwd_covid19表查询五个城市每个月的确诊人数,将查询结果存入dws_monthly_confirmed表。
insert into table dws_monthly_confirmed
select
year,
month,
`country/region`,
sum(confirmed) as monthly_confirmed
from dwd_covid19
group by year,month,`country/region`;

子任务2:使用Hive窗口函数查询数据
a.在ict_bigdata数据库中创建dws_most_recovered表,字段已给出。
create table dws_most_recovered(
year String,
month String,
`Country/Region` String,
monthly_recivered Int,
rank int
);
b.对于每个月份,查询dwd_covid19表中每月康复人数最多的两个国家,将查询结果存入dws_most_recovered表。
WITH monthly_recovered AS (
SELECT
year,
month,
`Country/Region`,
SUM(recivered) AS monthly_recivered
FROM dwd_covid19
GROUP BY year, month, `Country/Region`
),
ranked_recovered AS (
SELECT
year,
month,
`Country/Region`,
monthly_recivered,
ROW_NUMBER() OVER (PARTITION BY year, month ORDER BY monthly_recivered DESC) AS rank
FROM monthly_recovered
)
INSERT INTO TABLE dws_most_recovered
SELECT
year,
month,
`Country/Region`,
monthly_recivered,
rank
FROM ranked_recovered
WHERE rank <= 2;

任务4:PySPARK ML做不出来,ModelArts自动创建的环境有问题,做出来再发
再次重申,本文非官方解析,仅供参考
如有侵权,请及时联系本人删除文章。

















 2277
2277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









