




 本文详细解析了快速排序、堆排序和归并排序在不同情况下的时间复杂度,包括最好、最坏和平均情况,并解释了每种情况的原因。
本文详细解析了快速排序、堆排序和归并排序在不同情况下的时间复杂度,包括最好、最坏和平均情况,并解释了每种情况的原因。
写在前面
之所以写这个博文是因为在面试讯飞的时候面试官问到了快排在最好、平均情况下的时间复杂度及其原因。由于一直记得的是快排是冒泡的改进,冒泡最好情况下是O(n),所以一直记的快排最好情况下时间复杂度是O(n),然而二路快排在最好情况下其实是O(nlog2n)。面试到最后虽然我还是算通过了,但是我觉得是不行的。于是写下了这个作为一个提醒。这里放一下各种常用排序的时间复杂度和空间复杂度。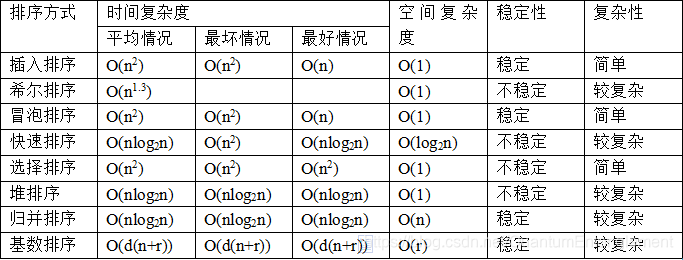
正文
1.快速排序(二路快排)
最好情况O(nlog2n)
快排最好情况是在待排序列的元素分布非常均匀的情况下,也就是说,每一趟排序的支点都恰好是待排子序列的中值,使得序列被平均分成长度相等的两个子序列。这时候一共进行了log2n次排序,每次排序访问了n个元素
最坏情况O(n2)
快排最坏情况是在待排序列正序或者倒序的时候,每一趟排序的支点都恰好是待排子序列的最大值或最小值,使得序列被分成了一个长度为1和一个长度为n-1的两个子序列。这时候一共进行了n次排序,每次排序访问了n个元素。
平均情况O(nlog2n)
一般来说平均情况都是指待排序列有一点乱或者是部分有序,快排在这种情况下不一定能将序列平均分成两个大小相等的序列,但在数据量很大的情况下能将序列分成大小相近的两个序列,这使得平均情况下进行比log2n大但不会超过很多的排序,每次排序访问了n个元素。
2.堆排序
最好情况、最坏情况、平均情况O(nlog2n)
这里将堆排序的三种情况放到一块讲是因为堆排序对待排序列顺序没有太多要求。三种情况下排序的过程都是进行了n次排序,每次排序访问了log2n个元素。这里说堆排序对原始顺序没有太多要求并不是说完全没有要求。如果原始序列在排序要求为升序时是一个小顶堆,降序时是一个大顶堆(这里大家可以去看看堆的定义是什么,因为堆本身也是非常难理解的)的话,排序速度要比其他状态下的序列快,这是因为本身建堆也是非常耗时间的(时间复杂度为O(n)),只是这个建堆的时间和排序的时间比起来更小一点。这也是为什么通常情况下我们排大量数据的时候一般选用快排而不用堆排序。
3.归并排序(二路归并)
最好情况、最坏情况、平均情况O(nlog2n)
归并和堆排序一样,对待排序列的顺序也没有太多要求。三种情况下排序的过程都是进行了log2n次的排序,每次排序访问n个元素。但是归并排序不需要建堆,所以归并的效率要比堆排序更高。

















 1971
1971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









