




青稞社区主页:https://qingkeai.online/
原文:https://mp.weixin.qq.com/s/MPuc8kjwAjPYGSdyHrkbqg
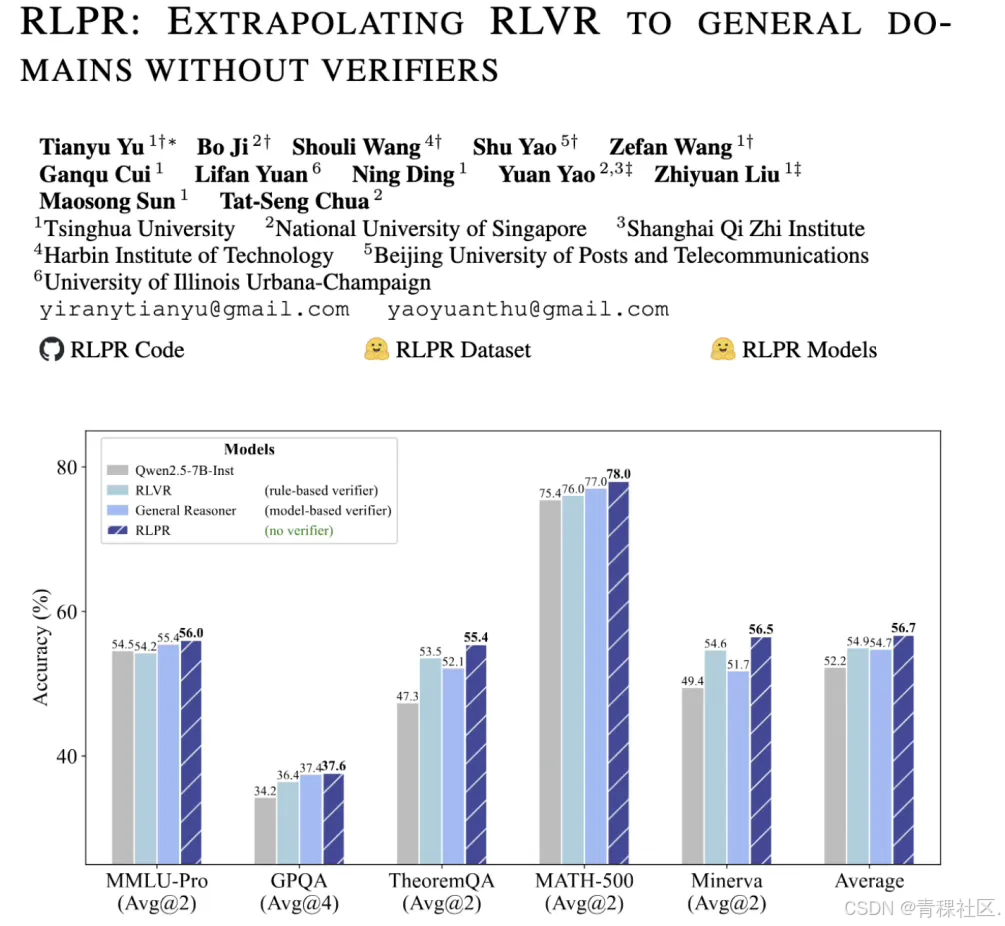
RLVR 展现出了巨大的潜力,但现有方法的应用范围局限于数学和代码等少数领域。面对自然语言固有的丰富多样性,清华大学自然语言处理实验室提出基于参考概率奖励的强化学习 RLPR,将 RLVR 推广到通用领域推理问题。
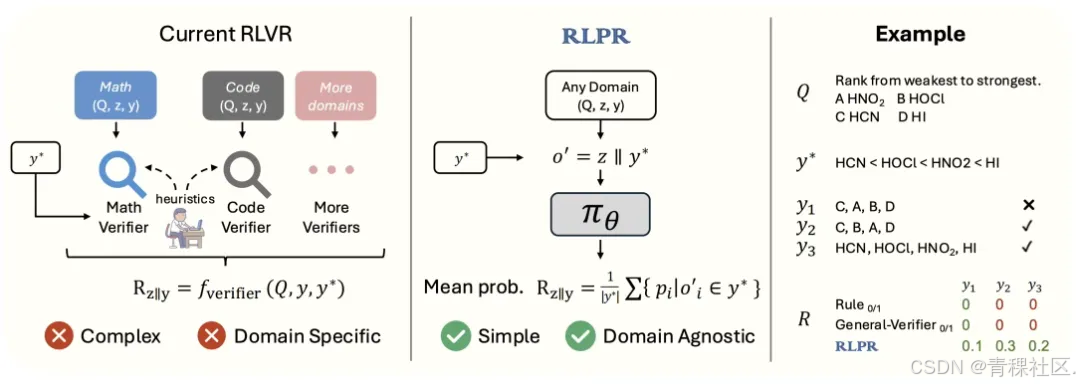
论文:RLPR: Extrapolating RLVR to General Domains without Verifiers
链接: https://arxiv.org/abs/2506.18254
代码:https://github.com/OpenBMB/RLPR
关于 RLPR 的解读:RL突破通用领域推理瓶颈!清华NLP实验室提出基于参考概率奖励的强化学习RLPR
8月12日晚8点,青稞Talk 第71期,清华大学自然语言处理实验室博士生余天予,将直播分享《RLPR:基于参考概率奖励的强化学习,推广 RLVR 到通用领域推理问题》。
分享嘉宾
余天予,清华大学自然语言处理实验室博士生,发表AAAI、CVPR 等人工智能顶会论文多篇,主要研究方向为多模态大模型。
主题提纲
RLPR:基于参考概率奖励的强化学习,推广 RLVR 到通用领域推理问题
1、RLVR 现有方法解析及局限
2、RLPR 核心思路与主要技术分析
3、在通用推理和数学推理基准上的评估验证
4、潜在不足与未来方向探讨
直播时间
8月12日20:00 - 21:00

















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









