




👉目录
1 引言
2 正文
3 腾讯云架构师技术同盟交流圈介绍
4 卓越架构师共学计划介绍
01
引言
大型语言模型(LLM)的训练过程虽然耗资巨大且备受关注,但其真正的价值实现,却发生在 推理(Inference) 这一最终环节。推理是将训练好的模型应用于实际,根据 用户输入(Prompt)生成响应的过程 。无论是驱动一个实时聊天机器人,还是进行离线文档分析,高效、可靠的推理是所有 LLM 应用的基石。然而,这一过程远非简单地调用模型那么直接,它面临着一个核心的 三难困境(Trilemma):
既要追求极致的 低延迟(Latency) 以保证用户体验,又要实现最大的 高吞吐量(Throughput) 以服务海量用户并降低单位成本,同时还需控制昂贵的硬件 成本(Cost)。
既要追求极致的 低延迟(Latency) 以保证用户体验,又要实现最大的 高吞吐量(Throughput) 以服务海量用户并降低单位成本,同时还需控制昂贵的硬件 成本(Cost)。
本文将深入剖析 LLM 推理的全貌,从其根本的自回归生成机制出发,逐层揭示其 核心挑战、关键性能指标、优化技术、分布式策略以及当前主流的推理框架 。本文旨在为读者构建一个关于 LLM 推理的完整知识图谱,理解其“表”之性能与“里”之原理。
*本LLM系列文章选自腾讯云架构师技术同盟成员羚羊工业互联网股份有限公司 高级系统架构师 宋国磊。宋老师为开发者搭建了一条由浅入深的学习路径。
02
正文
现代大语言模型主要基于 Transformer 架构,其推理过程的核心是自注意力机制。在推理阶段,模型需要处理的主要计算包括:
嵌入层计算:将输入 token 转换为向量表示。
多头自注意力:计算 Query、Key、Value 矩阵。
前馈网络:进行非线性变换。
层归一化:稳定训练过程。
输出层:生成下一个 token 的概率分布。
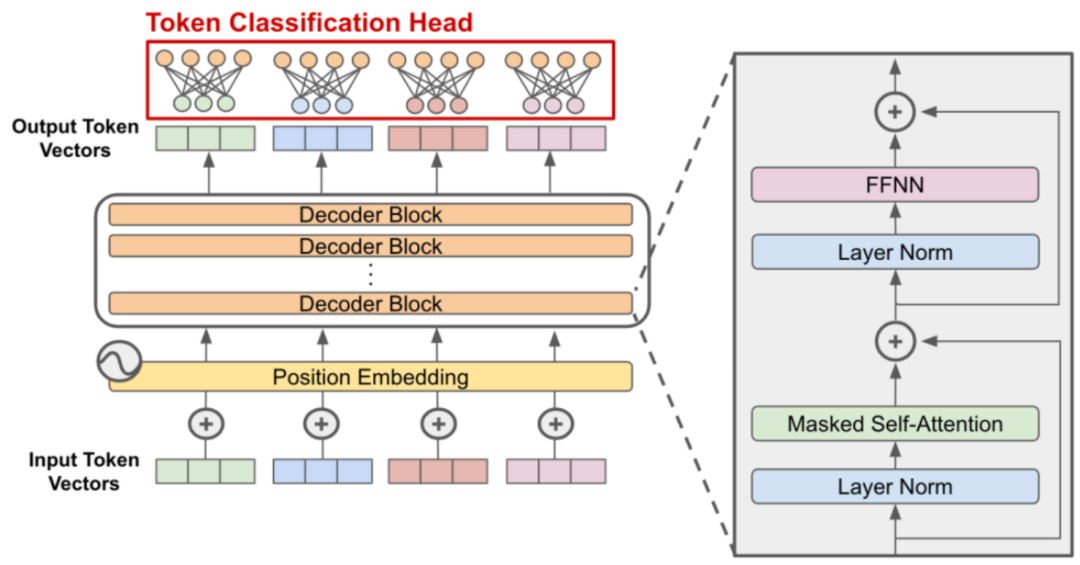
*Decoder-only Transformer架构
自回归生成:逐字吐露的本质
自回归意味着模型以 逐个 token 的方式生成文本。每个新 token 的预测都依赖于之前已经生成的所有 token(包括原始输入和先前已生成的输出)。这个过程形成了一个循环:
模型接收当前序列作为输入。
预测词汇表中每个词成为下一个 token 的概率分布。
通过采样策略(如贪心采样、核采样等)选择一个 token。
将新选中的 token 附加到序列末尾。
重复此过程,直到满足停止条件(如生成了终止符 `` 或达到最大长度)。
这种循序渐进的特性是 LLM 能够生成连贯、上下文相关文本的基础。但它也带来了固有的算法性挑战:随着序列的增长,模型在下一步需要处理的上下文也随之增加,导致计算量不断累积,速度越来越慢。
两阶段过程:预填充(Prefill)与解码(Decode)
LLM 推理并非一个单一的过程,而是被清晰地划分为两个计算特性截然不同的阶段。这种二元性是所有推理优化挑战的根源。
...

(点击图片阅读原文)
*该文章选自腾讯云架构师技术同盟交流圈
03
腾讯云架构师技术同盟交流圈介绍
架构师技术同盟交流圈是由腾讯云与海内外架构师们共建,为渴望深耕架构领域的开发者、技术专家和行业精英打造的成长型社区。交流圈聚焦于沉淀和交流一线落地实践与技术创新哲思,陪伴每一位成员在架构之路上行稳致远。这里不只是知识社区,也是你的技术成长同频圈。
点击阅读全文可前往交流圈首页,查看更多开发进阶架构师知识&与一线架构师共同探讨开发解决方案。诚邀你来逛社区,看行家经验、拓宽朋友圈,与万人共赴未来。
04
卓越架构师共学计划介绍
🌟不论你是基层新手研发人,还是深耕数年从业者,都能且值得走上架构师之路。

🌟参加卓越架构师共学计划,每周仅需30分钟,可系统化学习进阶架构师的知识,还可赢取精美周边。扫码进群即可正式成为共学计划成员,进群后请查看群公告,仅需2步即可抽取精美礼品~

*卓越架构师共学计划群
🎁本周精美奖品:斜挎包、卧蚕宝宝公仔、image冷萃杯等

卓越架构师,让我们一起code the future~


















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









