



ProEdit团队 投稿
量子位 | 公众号 QbitAI
想给照片里的猫换个颜色,结果总是编辑失败?想让视频里的人换件衣服,人脸却糊成一片或完全改变?
在AI视觉编辑领域,如何在修改目标属性的同时,精准保留背景和非编辑属性的一致性,一直是个“鱼和熊掌”的难题。


近日,来自中山大学iSEE实验室、香港中文大学MM Lab、新加坡南洋理工大学、香港大学的研究团队发布了最新研究成果ProEdit。
该方法通过对注意力机制和初始噪声潜在分布的“精准手术”,实现了超高精度的图像与视频编辑,且完全无需训练、即插即用。

△ 图1. ProEdit在图像和视频编辑上与现有方法的对比
为什么AI编辑总是“改不动”?
目前,基于反演(Inversion-based)的编辑方法(如RF-Solver、FireFlow)通常采用全局注入策略:为了保持背景尽量一致,它们会将原图的大量信息强行“塞”进生成过程。
但研究团队通过文本与图像的注意力可视化发现,这种做法存在严重的“源图像信息过度注入”问题:
- 注意力过度注入:
现有方法通过全局注入了过多的源图像注意力特征,导致模型更听源图像的话,而忽略了用户的编辑指令(Prompt)。
- 潜在空间锁死:
反演后的初始噪声中残留了太强的源图像分布信息,使得模型倾向于“重建”原图,而不是“编辑”新图。
结果就是:现有方法下,你想把“橙色猫”改写成“黑色猫”,AI可能还是给你一只橙色猫。而去除源图像注意力注入机制,又难以保持背景和非编辑属性的一致性。
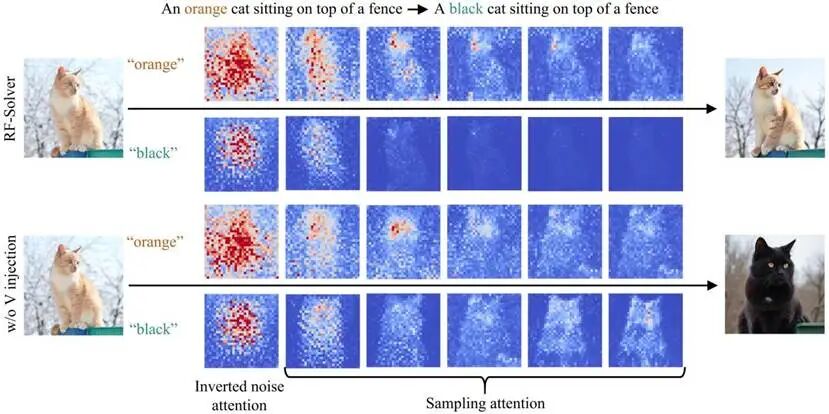
△ 图2. 现有方法与去除注意力注入下的注意力可视化与编辑效果
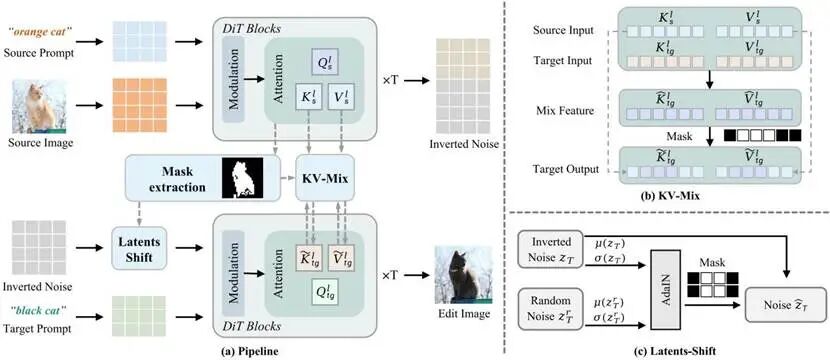
ProEdit两把精准的“手术刀”
为了破解上述难题,ProEdit提出了两个核心模块,从两个维度消除源图像信息的干扰:


















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









