



DeepPHY团队 投稿
量子位 | 公众号 QbitAI
首个系统性评估多模态大模型(VLM)交互式物理推理能力的综合基准来了。
淘天集团算法技术-未来生活实验室团队提出DeepPHY,通过六个极具挑战性的物理模拟环境,揭示了即便是顶尖VLM,在将物理知识转化为精确、可预测的交互控制时,仍存在显著的核心短板。
该论文已被AAAI 2026收录。

近期,基于视觉语言模型(VLM)的智能体在游戏、GUI操作和具身AI等动态交互环境中取得了显著进展。然而,现有基准或侧重于静态问答,或物理模型过于简化,难以全面评估智能体的真实物理推理能力。
为了弥补这一空白,淘天集团未来生活实验室团队提出了DeepPHY。
下面具体来看。
DeepPHY是什么?
DeepPHY概览
尽管VLM在静态图像理解上表现出色,但当它们作为智能体(Agent)进入需要与物理世界交互的动态环境时,其性能往往不尽人意。这暴露出现有基准的局限性:
游戏环境(如《星际争霸II》):通常提供高级别的观测和动作空间,智能体更多是学习剧情向的游戏机制而非底层物理规律。
GUI环境:动作是离散的、非连续的,不涉及真实世界的物理原理。
具身AI环境:大多聚焦于语义层面的交互(如“拿起杯子”),而物理动态过程(如碰撞、摩擦)被过度简化。
物理推理是世界模型和具身智能的基石,为了深入探究VLM的物理推理能力,淘天未来生活实验室推出了DeepPHY——首个专为此目的设计的综合基准框架,它将六个不同的物理模拟器融合,创造出 VLM 交互式物理推理的考场。
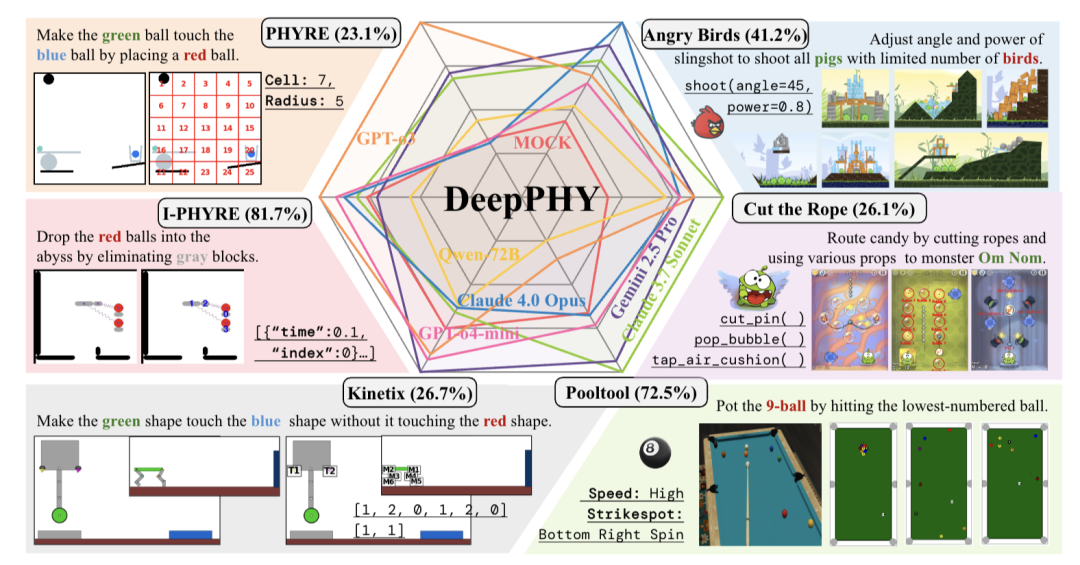 △DeepPHY基准测试套件,括号中的值显示了性能最佳的VLM成功率
△DeepPHY基准测试套件,括号中的值显示了性能最佳的VLM成功率
在这些环境中,智能体必须通过持续的交互来感知和理解物理世界的因果关系,从而系统性地衡量其“物理智商”。
在此基础上,研究人员对17个主流的开源与闭源VLM进行了全面的实证研究,揭示了它们在物理交互、规划及环境适应等方面的不足。
DeepPHY基准环境介绍
DeepPHY集成了六个各具特色的物理挑战环境,从简单到复杂,全面覆盖了从基础物理(碰撞、重力)到复杂动力学(多体动力学、绳索张力)的多个维度。
 △DeepPHY中六个环境在不同维度上的挑战侧重分析
△DeepPHY中六个环境在不同维度上的挑战侧重分析
PHYRE:在静态的2D物理场景中,通过放置一个红色球,让绿色球最终碰到蓝色球。考验模型的前瞻性规划,能否设计一次动作引发完美的连锁反应。
I-PHYRE:在精确的时刻移除特定灰色障碍物,引导所有红球落入下方深渊。测试模型的时序规划,要求在最佳时间点触发物理变化。
Kinetix:协同控制多部件(马达正反转、推进器开关),让绿色部件接触蓝色目标并避开红色障碍。检验模型的多部件协同控制与动态适应能力,需要根据实时视觉反馈持续调整策略。
台球:在高仿真台球环境 (Pooltool) 中遵循9球规则,将目标球击入袋中。考察对碰撞、旋转(Spin)和摩擦力等高级物理效应的理解与运用。
愤怒的小鸟 (Angry Birds):设定角度与力度,用弹弓发射不同类型的有限小鸟摧毁所有绿猪。挑战模型对抛物线运动、结构力学和连锁反应的直觉掌握。
割绳子 (Cut the Rope):切断绳索并利用气垫、泡泡等道具,将糖果送到小怪兽Om Nom口中。是对精确时机、动作序列和多道具协同的综合物理推理考验,被作者视为物理智能的终极考验。
为了让VLM能够专注于物理推理而非目标检测,研究人员对环境的观测和动作空间进行了标准化改造:
增强观测空间:通过在图像上叠加网格或ID标签,清晰标注可交互对象,降低感知负担,从而更聚焦于VLM物理推理智商的评估。
结构化动作空间:将连续或复杂的动作(如精确坐标、角度)转化为离散的、结构化的格式(如选择网格、输出JSON或Python函数调用),使VLM在零样本(zero-shot)设置下也能进行有效交互。
 △DeepPHY中各环境的观测与动作空间转换策略
△DeepPHY中各环境的观测与动作空间转换策略
实验与发现
研究人员在DeepPHY上对17个主流VLM(包括Qwen、Claude、Gemini、GPT系列)进行了全面的零样本评估,结果揭示了当前VLM在物理推理方面存在的普遍且深刻的局限性。
△本文测评的主流VLM模型
总体性能:与“随机猜”差距不大
在多个环境中,大多数VLM的性能甚至无法超越一个随机执行动作的MOCK基线。
这表明,即便研究人员将动作空间大幅简化,模型依然缺乏对物理世界基本规律的深入理解。
虽然最新的闭源大模型(如GPT-o3、Gemini-2.5-Pro)表现相对较好,但与理想性能和人类水平相比,仍有巨大的鸿沟。
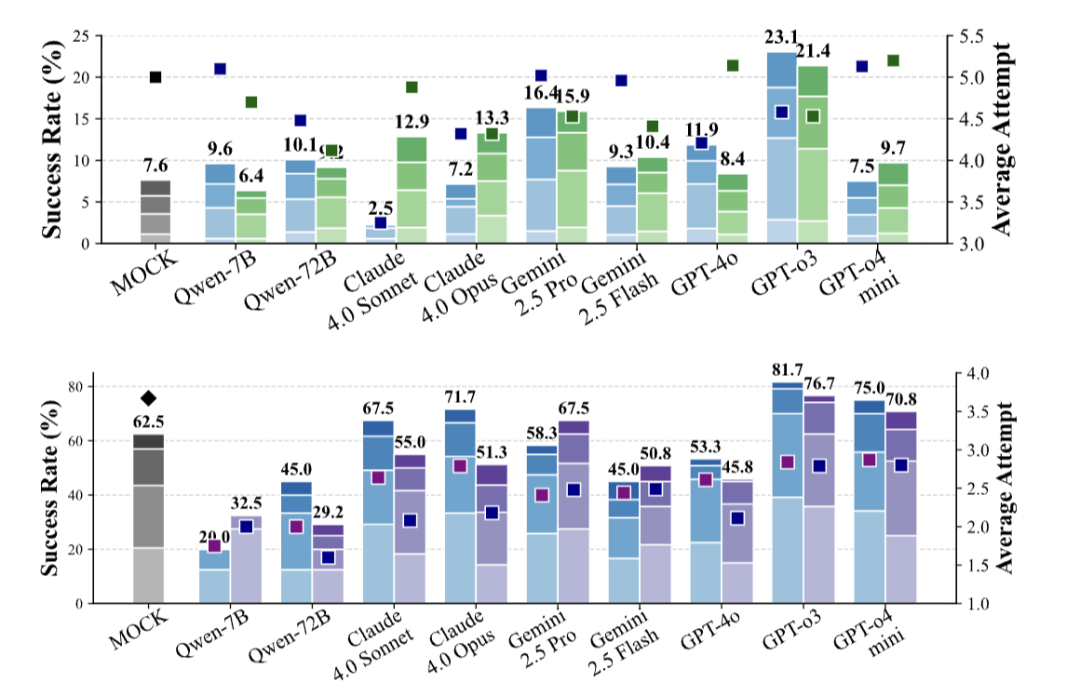 △PHYRE(上)和I-PHYRE(下)环境中的性能对比。大多数模型成功率提升缓慢,平均尝试次数居高不下
△PHYRE(上)和I-PHYRE(下)环境中的性能对比。大多数模型成功率提升缓慢,平均尝试次数居高不下
分环境剖析:暴露不同维度的短板
PHYRE&I-PHYRE:模型难以从失败的尝试中有效学习。即使给予多次机会,成功率提升缓慢,表明其无法构建准确的内部物理世界模型来指导后续决策。
Kinetix:随着任务难度增加,模型性能急剧下降。在复杂任务中,额外的视觉标注甚至会成为“认知干扰”,损害性能,这揭示了模型在处理复杂信息时的脆弱性。
Pooltool(台球):“高成功率”的假象。团队发现,某些模型(如GPT-4o-mini)取得的100%成功率并非源于策略规划,而是在所有交互中返回了相同的答案,完全不懂得利用旋转、角度等高级物理技巧进行布局,这暴露了其策略的浅薄。
Angry Birds&Cut the Rope:与人类玩家差距巨大。这类游戏需要精确的时机把握和多步连锁反应预测。模型的核心弱点在于时空推理能力的缺失。例如,它们无法预测切断绳索后糖果的最佳摆动时机,或小鸟撞击后建筑物的连锁坍塌效果。
 △Pooltool、Angry Birds和Cut the Rope中的性能总结,模型在需要精细策略和时序控制的游戏中,与人类差距悬殊
△Pooltool、Angry Birds和Cut the Rope中的性能总结,模型在需要精细策略和时序控制的游戏中,与人类差距悬殊
核心发现:“说得到”却“做不到”的脱节
团队设计了两种提示(Prompt)策略:一种是直接输出动作的VLA模式,另一种是要求模型先预测物理结果再输出动作的WM(World Model)模式。
直觉上,WM模式应该能促进模型思考,提升性能。但实验结果恰恰相反:在绝大多数复杂任务中,WM模式反而降低了成功率。
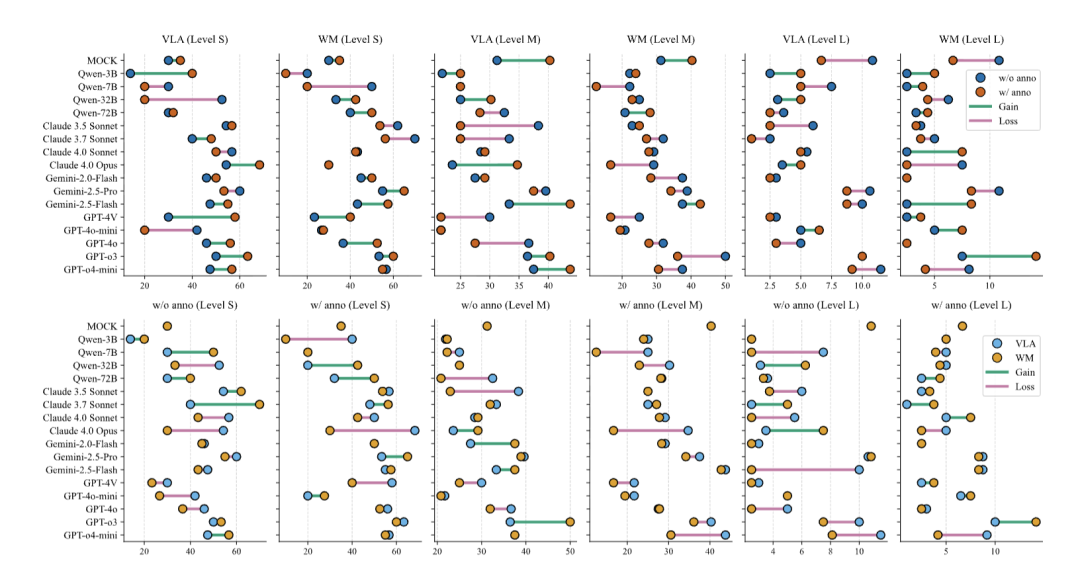 △Kinetix中不同任务等级的VLA与WM模式对比
△Kinetix中不同任务等级的VLA与WM模式对比
 △Kinetix 中,Claude 4.0 Sonnet的定性案例
△Kinetix 中,Claude 4.0 Sonnet的定性案例
通过进一步的案例分析,表明了尽管模型能够用语言准确地描述出预期的物理运动(如“机器人手臂将顺时针旋转并展开”),但它生成的动作指令却无法实现这一描述,导致失败。
这一发现揭示了当前VLM的一个根本性缺陷:它们的物理知识是描述性的,而非预测性和程序性的。
模型可以像物理教科书一样“背诵”出正确的物理现象描述,但却无法将这种描述性知识转化为精确的、可执行的控制信号来与物理世界进行交互。
这就像一个人能背诵出所有游泳理论,但一进水里就下沉。
基于此,团队表示希望DeepPHY能成为一个严谨的“试金石”,推动社区开发出更具物理常识、真正理解并能与物理世界交互的下一代AI智能体。
感兴趣的朋友可戳下方链接查看更多细节~
论文链接:https://arxiv.org/abs/2508.05405
开源代码:https://github.com/XinrunXu/DeepPHY


















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









