



阶跃星辰投稿
量子位 | 公众号 QbitAI
形式化定理证明,又有新范式!
阶跃星辰正式发布并开源了形式化定理证明大模型:StepFun-Prover-Preview-7B和StepFun-Prover-Preview-32B。
StepFun-Prover采用基于环境反馈的强化学习训练流程,能像人类一样在推理过程中通过与环境的实时交互逐步修正和完善形式化证明。
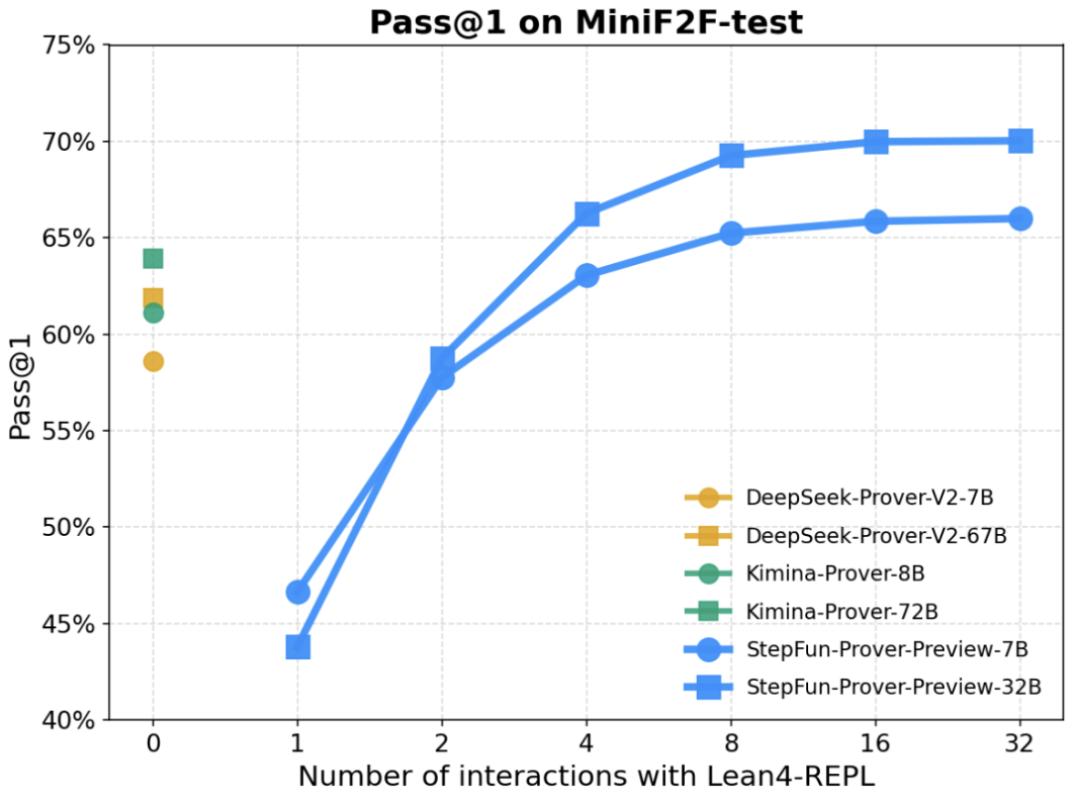
△不同模型在基准测试集 miniF2F-test 上的表现
技术亮点
两阶段监督微调(Two-stage SFT)
阶跃星辰团队采用了分阶段微调策略,具体可分为两步:
第一步利用开源的Lean 4数据,建立基础的代码补全能力。
第二步用精细筛选的高质量冷启动数据进一步训练,使模型能够理解求解数学题的过程中,如何使用Lean验证,并初步学会与环境交互。
这一步训练出的模型已经获得了使用工具的基本能力。
工具集成强化学习(Tool-integrated RL)
阶跃星辰团队使用GRPO进行后续强化学习训练,让模型在生成输出过程中获得如下能力:
用自然语言进行解题;
主动插入<sketch>标签并生成Lean 4代码,然后将代码发送到Lean 4环境中执行,相应的成功结果或错误信息(<REPL>)作为反馈返回给模型;
用自然语言分析反馈信息;
模型继续重复上述过程,直到最终输出</think>标签后给出确定答案。
这一套流程,允许模型像程序员一样调试代码——发现错误,反思,修正错误,直到证明成立。
奖励函数也设计得非常直观:对于最终模型确定的答案,REPL验证通过就给1分,否则0分。
RL与SFT的迭代循环优化
阶跃星辰团队采用了“RL-SFT-RL”的迭代优化方法,其关键步骤如下:
对强化学习过程中失败率高的题目,如果最终成功了,就把这条推理路径留下;
筛选其中逻辑清晰、反馈处理合理的样本,重新用于监督微调;
再接着强化学习,进一步提升模型的推理鲁棒性。
这一方法让模型逐步攻克更难的推理任务,真正实现越练越强。
Pass@1准确率领先
StepFun-Prover-Preview-32B在基准测试集miniF2F-test上的pass@1通过率达70.0%,超越所有已知模型4%+!
StepFun-Prover-Preview-7B的pass@1通过率也已超过DeepSeek-Prover-V2-671B和Kimina-Prover-72B。

△不同模型在miniF2F-test上的表现
案例展示
案例 1:主动去除形式化证明中的冗余步骤
<sketch>
import Mathlib
import Aesop
set_option maxHeartbeats 0
open BigOperators Real Nat Topology Rat
theorem mathd_numbertheory_247 (n : ℕ) (h₀ : 3 * n % 11 = 2) : n % 11 = 8 := by
have h1 : n % 11 = 0 ∨ n % 11 = 1 ∨ n % 11 = 2 ∨ n % 11 = 3 ∨ n % 11 = 4 ∨ n % 11 = 5 ∨ n % 11 = 6 ∨ n % 11 = 7 ∨ n % 11 = 8 ∨ n % 11 = 9 ∨ n % 11 = 10 := by
omega
rcases h1 with (h | h | h | h | h | h | h | h | h | h | h) <;> simp [Nat.mul_mod, h] at h₀ ⊢
<;> omega
</sketch>
<REPL>
{"messages": [{"severity": "warning", "pos": {"line": 11, "column": 6}, "endPos": {"line": 11, "column": 11}, "data": "this tactic is never executed\nnote: this linter can be disabled with `set_option linter.unreachableTactic false`"}, {"severity": "warning", "pos": {"line": 11, "column": 6}, "endPos": {"line": 11, "column": 11}, "data": "'omega' tactic does nothing\nnote: this linter can be disabled with `set_option linter.unusedTactic false`"}]}
</REPL>
Let me review what the REPL is telling us and modify my strategy.
The warning says that the `omega` tactic is never executed and does nothing. This suggests that the `simp` tactic with the given hypotheses and `omega` was able to solve the goals completely, so the `omega` tactic wasn't needed.
Let me try a simpler approach:
<sketch>
import Mathlib
import Aesop
set_option maxHeartbeats 0
open BigOperators Real Nat Topology Rat
theorem mathd_numbertheory_247 (n : ℕ) (h₀ : 3 * n % 11 = 2) : n % 11 = 8 := by
have h1 : n % 11 = 0 ∨ n % 11 = 1 ∨ n % 11 = 2 ∨ n % 11 = 3 ∨ n % 11 = 4 ∨ n % 11 = 5 ∨ n % 11 = 6 ∨ n % 11 = 7 ∨ n % 11 = 8 ∨ n % 11 = 9 ∨ n % 11 = 10 := by
omega
rcases h1 with (h | h | h | h | h | h | h | h | h | h | h) <;> simp [Nat.mul_mod, h] at h₀ ⊢
</sketch>案例 2:根据超时反馈调整形式化证明结构
<sketch>
import Mathlib
import Aesop
set_option maxHeartbeats 0
open BigOperators Real Nat Topology Rat
theorem mathd_numbertheory_277 (m n : ℕ) (h₀ : Nat.gcd m n = 6) (h₁ : Nat.lcm m n = 126) :
60 ≤ m + n := by
have h2 : m * n = 756 := by
calc
m * n = Nat.gcd m n * Nat.lcm m n := by rw [Nat.gcd_mul_lcm]
_ = 6 * 126 := by rw [h₀, h₁]
_ = 756 := by norm_num
have h3 : m ∣ 756 := by
use n
all_goals nlinarith
have h4 : n ∣ 756 := by
use m
all_goals nlinarith
have h5 : m ≤ 756 := by
exact Nat.le_of_dvd (by norm_num) h3
have h6 : n ≤ 756 := by
exact Nat.le_of_dvd (by norm_num) h4
interval_cases m <;> try {
interval_cases n <;> norm_num [Nat.gcd, Nat.lcm] at h₀ h₁ ⊢
<;> omega
}
</sketch>
<REPL>
"repl cannot return status in 60.47944927215576 seconds!"
</REPL>
The REPL feedback provides valuable insights - let me incorporate these and revise.
The error "repl cannot return status in 60.47944927215576 seconds!" indicates that the proof is taking too long. The `interval_cases` tactic is generating many cases, and we need a more efficient approach.
Let's use a more mathematical approach. We know that $m \cdot n = 756$ and $\gcd(m, n) = 6$. We can use the fact that if $\gcd(m, n) = 6$, then $m = 6a$ and $n = 6b$ where $\gcd(a, b) = 1$ and $a \cdot b = 21$.
The factor pairs of 21 with coprime factors are $(1, 21)$ and $(3, 7)$. The smallest sum is $1 + 21 = 22$, but we need to check if this gives us the minimal $m + n$.
Wait, actually, we need to consider all factor pairs and find the minimal sum. Let's compute:
For $(1, 21)$: $m = 6 \cdot 1 = 6$, $n = 6 \cdot 21 = 126$, sum = 132
For $(3, 7)$: $m = 6 \cdot 3 = 18$, $n = 6 \cdot 7 = 42$, sum = 60
For $(7, 3)$: $m = 6 \cdot 7 = 42$, $n = 6 \cdot 3 = 18$, sum = 60
For $(21, 1)$: $m = 6 \cdot 21 = 126$, $n = 6 \cdot 1 = 6$, sum = 132
So the minimal sum is 60. Therefore, we need to show that $m + n \geq 60$.
Let's try a more direct approach using the properties of gcd and lcm:
<sketch>
import Mathlib
import Aesop
set_option maxHeartbeats 0
open BigOperators Real Nat Topology Rat
theorem mathd_numbertheory_277 (m n : ℕ) (h₀ : Nat.gcd m n = 6) (h₁ : Nat.lcm m n = 126) :
60 ≤ m + n := by
have h2 : m * n = 756 := by
calc
m * n = Nat.gcd m n * Nat.lcm m n := by rw [Nat.gcd_mul_lcm]
_ = 6 * 126 := by rw [h₀, h₁]
_ = 756 := by norm_num
have h3 : m ≤ 756 := by
have : m ∣ 756 := by
use n
all_goals nlinarith
exact Nat.le_of_dvd (by norm_num) this
have h4 : n ≤ 756 := by
have : n ∣ 756 := by
use m
all_goals nlinarith
exact Nat.le_of_dvd (by norm_num) this
-- We know that m and n are at most 756, but we need a better bound
-- Since gcd(m, n) = 6, both m and n are multiples of 6
have h5 : 6 ∣ m := by
have : 6 ∣ m := by
have h6 : Nat.gcd m n ∣ m := by
exact Nat.gcd_dvd_left m n
rw [h₀] at h6
exact h6
exact this
have h6 : 6 ∣ n := by
have : 6 ∣ n := by
have h7 : Nat.gcd m n ∣ n := by
exact Nat.gcd_dvd_right m n
rw [h₀] at h7
exact h7
exact this
-- So m = 6k and n = 6l for some k, l
-- We also know that lcm(m, n) = 126
-- Since m = 6k and n = 6l, we have lcm(6k, 6l) = 6 * lcm(k, l) = 126
-- Therefore, lcm(k, l) = 21
-- We need to find the minimal m + n = 6(k + l) where lcm(k, l) = 21 and gcd(k, l) = 1
-- The factor pairs of 21 with coprime factors are (1, 21) and (3, 7)
-- The minimal sum is 1 + 21 = 22, so m + n = 6 * 22 = 132
-- But wait, that's not right. Let's recalculate...
-- Actually, we need pairs (k, l) such that lcm(k, l) = 21
-- The pairs are (1, 21), (21, 1), (3, 7), (7, 3)
-- The sums are 22, 22, 10, 10
-- So the minimal sum is 10, giving m + n = 6 * 10 = 60
-- Therefore, we need to show that m + n ≥ 60
-- Let's proceed by contradiction: assume m + n < 60
by_contra h
push_neg at h
-- We need to show this leads to a contradiction
-- Since m and n are both ≥ 6 (as they are multiples of 6 and positive)
have hm : m ≥ 6 := by
have : m > 0 := by
by_contra h'
push_neg at h'
have : m = 0 := by omega
rw [this] at h2
omega
have : m ≥ 6 := by
omega
exact this
have hn : n ≥ 6 := by
have : n > 0 := by
by_contra h'
push_neg at h'
have : n = 0 := by omega
rw [this] at h2
omega
have : n ≥ 6 := by
omega
exact this
-- So m + n ≥ 12, but we need a stronger bound
-- Let's use the fact that if m + n < 60, then both m and n must be less than 60
have h7 : m < 60 := by omega
have h8 : n < 60 := by omega
-- But since m and n are multiples of 6, the possible values are 6, 12, 18, 24, 30, 36, 42, 48
interval_cases m <;> try {
interval_cases n <;> norm_num [Nat.gcd, Nat.lcm] at h₀ h₁ ⊢
<;> omega
}
</sketch>案例 3:基于环境反馈有效改错
StepFun-Prover Preview是阶跃星辰团队在形式化证明方向的阶段性成果,团队也将在形式化推理模型方向持续探索。
Github:
https://github.com/stepfun-ai/StepFun-Prover-Preview
Huggingface:
https://huggingface.co/stepfun-ai/StepFun-Prover-Preview-32B
技术报告:
https://arxiv.org/abs/2507.20199


















 53
53

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









