



V²Flow团队 发自 凹非寺
量子位 | 公众号 QbitAI
视觉Token可以与LLMs词表无缝对齐了!
V²Flow,基于LLMs可以实现高保真自回归图像生成。
随着ChatGPT掀起自回归建模革命后,近年来研究者们开始探索自回归建模在视觉生成任务的应用,将视觉和文本数据统一在“next-token prediction”框架下。
实现自回归图像生成的关键是设计向量化(Vector-Quantization)的视觉Tokenizer,将视觉内容离散化成类似于大语言模型词表的离散Token。
现有方法虽取得进展,却始终面临两大桎梏:
1、传统视觉tokenizer生成的离散表征与LLM词表存在显著的分布偏差。
2、维度诅咒:图像的二维结构迫使大语言模型以逐行方式预测视觉token,与一维文本的连贯语义预测存在本质冲突。
结构性与特征分布性的双重割裂,暴露了当前自回归视觉生成的重大缺陷:缺乏能够既保证高保真图像重建,又能与预训练LLMs词汇表在结构上和特征分布上统一的视觉tokenizer。解决这一问题对于实现有效的多模态自回归建模和增强的指令遵循能力至关重要。
因此,一个核心问题是:
能否设计一种视觉tokenizer,使生成的离散视觉token在保证高质量视觉重建的同时,与预训练LLMs词汇表实现无缝融合?
统一视觉Token与大语言模型词表
最新开源的V²Flow tokenizer,首次实现了将视觉内容直接嵌入现有大语言模型的词汇空间,在保证高质量视觉重建的同时从根本上解决模态对齐问题。总体而言,V²Flow主要包括三点核心贡献:
视觉词汇重采样器。
如图1(a) ,将图像压缩成紧凑的一维离散token序列,每个token被表示为大语言模型(例如Qwen、LLaMA系列)词汇空间上的软类别分布。这一设计使得视觉tokens可以无缝地嵌入现有LLM的词汇序列中。换言之,图像信息被直接翻译成LLM“听得懂”的语言,实现了视觉与语言模态的对齐。
在图1(b)中,经由重采样器处理后,视觉tokens的潜在分布与大型语言模型(LLM)的词汇表高度一致。这种在结构和潜在分布上的高度兼容性,能够降低视觉tokens直接融入已有LLM的复杂性。
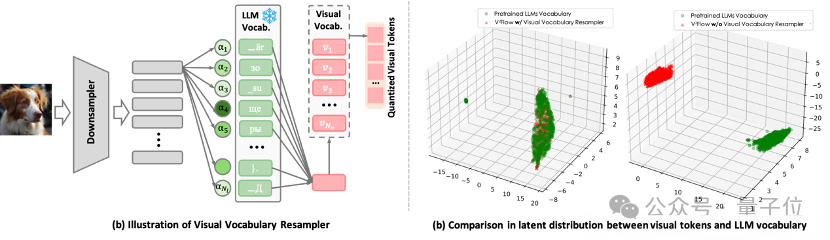
△ 图 1 视觉词汇重采样器的核心设计。
掩码自回归流匹配编码器。
为了实现离散化视觉token的高保真视觉重建,V²Flow提出了掩码自回归流匹配解码器。该解码器采用掩码Transformer编码-解码结构,为视觉tokens补充丰富的上下文信息。增强后的视觉tokens用于条件化一个专门设计的速度场模型,从标准正态先验分布中重建出连续的视觉特征。在流匹配采样阶段,该解码器采用类似MA的方式,以“next-set prediction”的方式逐步完成视觉重建。
相比于近期提出的仅依赖掩码编码器-解码器结构的TiTok,V2Flow自回归采样的优势是能够在更少的视觉token数量下实现更高的重建质量,有效提高了压缩效率。
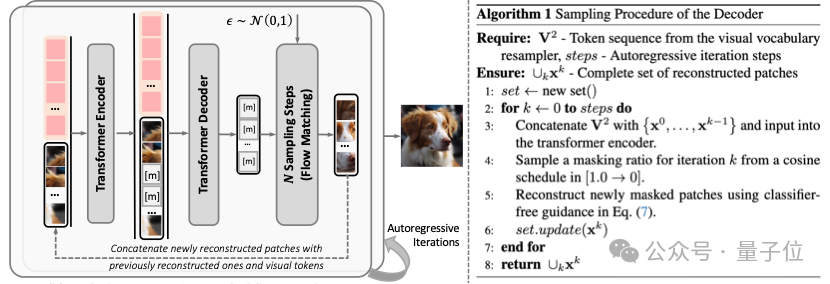
△ 图 2 掩码自回归流匹配解码器示意图以及采样阶段算法流程
端到端自回归视觉生成。
图3展示了V²Flow协同LLMs实现自回归视觉生成的流程。为促进两者无缝融合,在已有LLM词汇表基础上扩展了一系列特定视觉tokens,并直接利用V²Flow中的码本进行初始化。训练阶段构建了包含文本-图像对的单轮对话数据,文本提示作为输入指令,而离散的视觉tokens则作为预测目标响应。
在推理阶段,经过预训练的LLM根据文本指令预测视觉tokens,直至预测到 token为止。随后,离散视觉tokens被送入V²Flow解码器,通过流匹配采样重建出高质量图像。
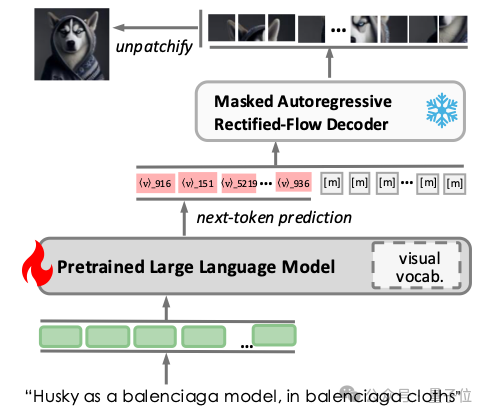
△ 图3 V²Flow与预训练LLMs融合实现自回归视觉生成的整体流程。
实验结果
重建质量方面,V²Flow无论是在ImageNet-1k 测试数据集的256和512分辨率下均取得了竞争性的重建性能。
相比于字节提出的一维离散化tokenizer TiTok相比,V²Flow利用更少的离散tokens实现了更高质量的图像重建,显著提高了整体压缩效率。
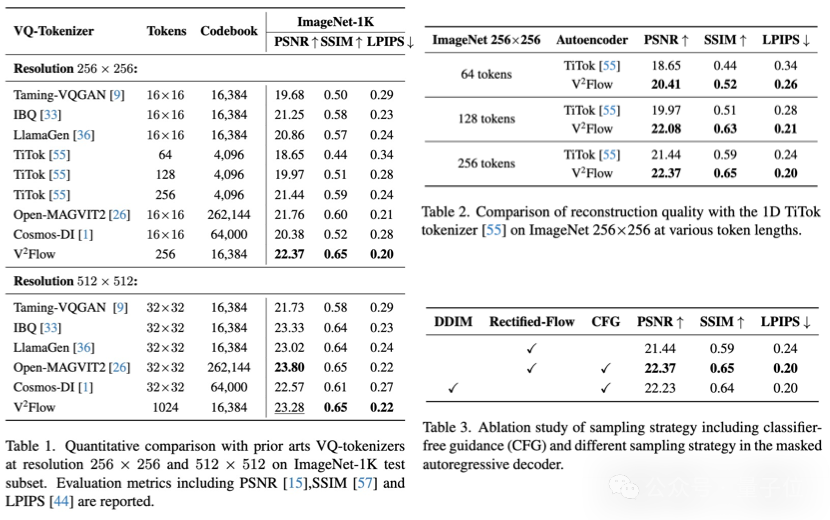
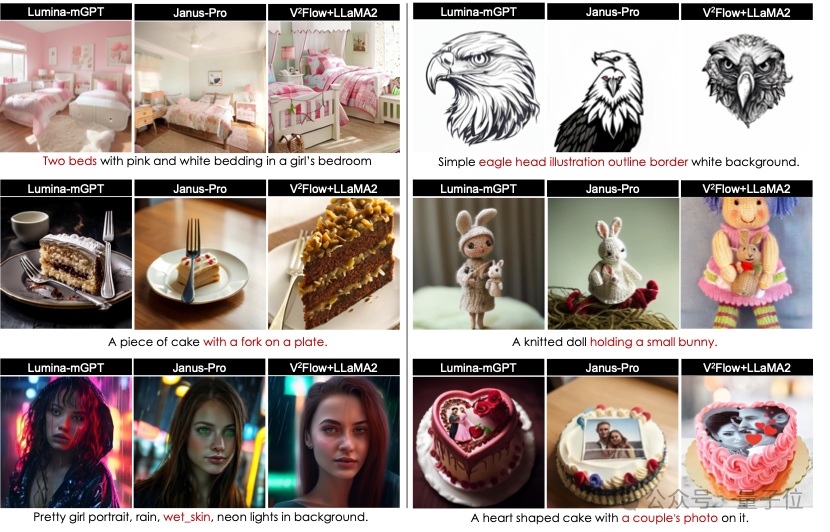
文本引导图像生成方面,实验结果表明,相比于当前两种最先进的自回归生成模型Janus-Pro-7B和Lumina-mGPT-7B,V²Flow+LLaMA2-7B能够更加准确地捕捉文本提示中的语义细节,展示了极具竞争力的生成性能。
开源生态与团队招募:共建多模态未来
开源承诺:让技术普惠每一位探索者
开源是推动AI技术进化的核心动力。本次发布的V²Flow框架已完整公开训练与推理代码库,开发者可基于现有代码快速复现论文中的核心实验。更令人期待的是,团队预告将于近期陆续发布:
512/1024分辨率预训练模型:支持高清图像重建与生成
自回归生成模型:集成LLaMA等主流大语言模型的开箱即用方案
多模态扩展工具包:未来将支持视频、3D、语音等跨模态生成任务
加入我们:共创下一代多模态智能
V²Flow作者团队现招募多模态生成算法研究型实习生!如果你渴望站在AI内容生成的最前沿,参与定义自回归架构的未来,这里将是你实现突破的绝佳舞台。
我们做什么?
探索文本、图像、视频、语音、音乐的统一自回归生成范式
构建支持高清、长序列、强语义关联的多模态大模型
攻克数字人、3D生成、实时交互创作等产业级应用难题
我们需要你具备:
硬核技术力
精通Python,熟练使用PyTorch/TensorFlow等框架
深入理解Diffusers、DeepSpeed等AIGC工具链
在CV/NLP领域顶级会议(CVPR、ICML、NeurIPS等)发表论文者优先
极致创新欲
对多模态生成、自回归架构、扩散模型等技术有浓厚兴趣
曾在Kaggle、ACM竞赛等获得Top名次者优先
有开源项目贡献或独立开发经验者优先
投递方式:zhangguiwei@duxiaoman.com
论文链接:
https://arxiv.org/abs/2503.07493
开源项目链接:
https://github.com/Davinci-XLab/V2Flow



















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









