



克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
开源模型,还是得看杭州。
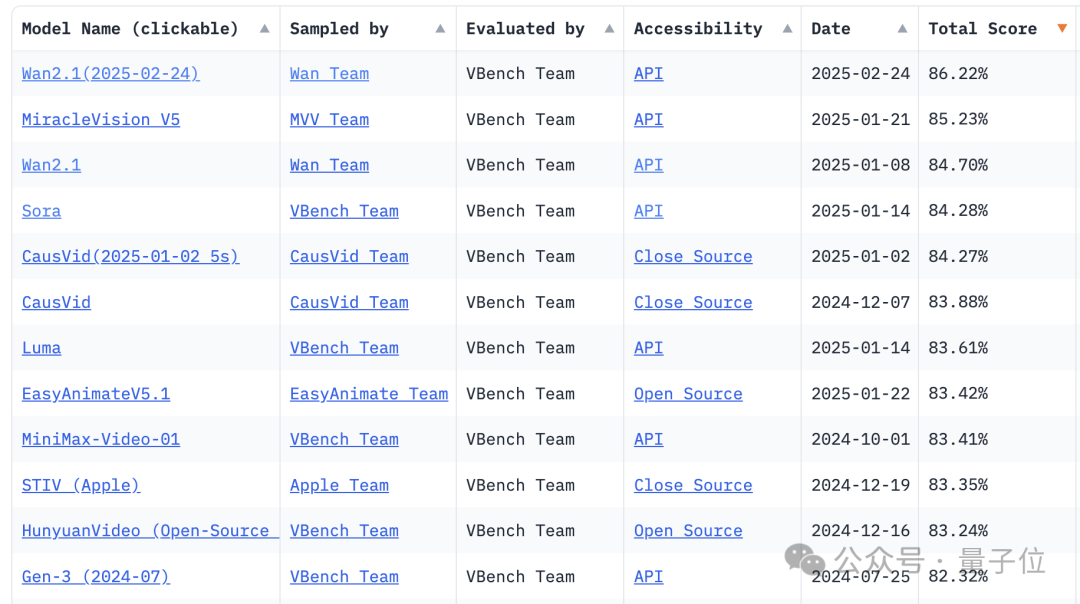
前脚发完QwQ-Max,阿里就在深夜开源了视频生成模型Wan 2.1,14B参数直接屠榜VBench,什么Sora、Gen-3通通不是它的对手。
从官方Demo中看,复杂运动细节非常到位,5个人一起跳hip-hop也能做到动作同步。

而且在静态图像生成中都还是老大难问题的文字,现在也被万相给攻克了。

当然了,14B的参数量说大不大,但在个人消费级显卡上本地部署还是比较吃力的。
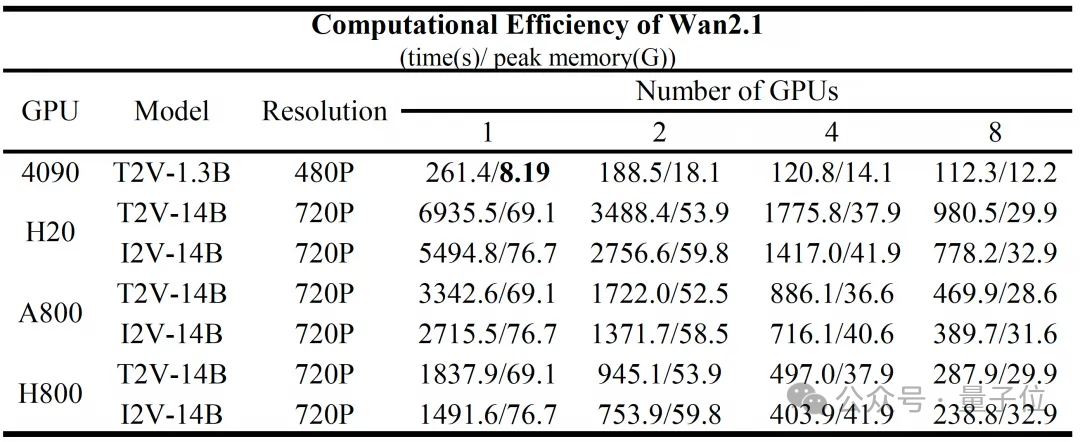
不过14B(支持分辨率720P)之外,还有一个1.3B的小号版本(支持分辨率480P),在一块4090上占用显存是8个多GB,消耗时间4分21秒。
如此观之,用12GB的4070,也是能带动的。
同时阿里还上线了两个图生视频模型,都是14B但分为480P和720P两个版本。
四个模型全都是Apache 2.0,也就是免费商用。
而且官方也放出计划表,AI创作者们非常喜欢的ComfyUI,之后也会集成。

视频生成模型会写字了
目前可以玩到Wan 2.1的途径有很多,最简单的方法是通过通义万相自己的平台。
在平台里,1.3B和14B版本分别叫做极速版和专业版,每次消耗5个或3个“灵感值”(新用户默认有50个,还可通过签到等多种方式免费获得)。
不过由于热度实在太高,等待的时间也会比较长,甚至有时会出现“过于火爆”的情况。

动手能力稍强的话,可以根据官方的教程通过HuggingFace、魔搭社区或者本地等方式自行折腾,当然还有一些第三方平台也进行了跟进。
网友们也是玩出了各种花活,有人用它生成了《我的世界》风格的故事场景。

△作者:X/@TheXeophon
再看看官方案例,从效果维度上看,Wan 2.1最大的亮点,可能就是支持在视频中生成文字了。
而且不是生硬地加入,会根据文字所处位置的材质进行合理变化,以及随载体一同运动。

当然相对文字来说更基础的动作细节,技术也同样过关。
让两个人跳一段华尔兹,多次转身前后人物形象依然保持一致,背景的转动也很自然。

并且也更懂物理规律,一支箭射出后,弓弦的抖动刻画得非常到位。

小狗切菜的过程当中,被切的西红柿也没有出现畸变。

还有像人从水面中探出头这种场景,不仅界面处处理得很好,带起的水也是从水流逐渐变化成水滴。
唯一的瑕疵之处是,头出来的时候人物的嘴是张着的(有网友指正,张嘴是正常现象)。

另外关于图像生视频,也有网友进行了体验,没用任何提示词就得到了这样的日漫风动画:

△作者:X/@seiiiiiiiiiiru
除了效果本身,1.3B版本8个多GB的低显存占用,对个人创作者来说也是一个极好的消息。
那么,Wan 2.1是如何实现又好又省的呢?
创新3D变分自动编码器
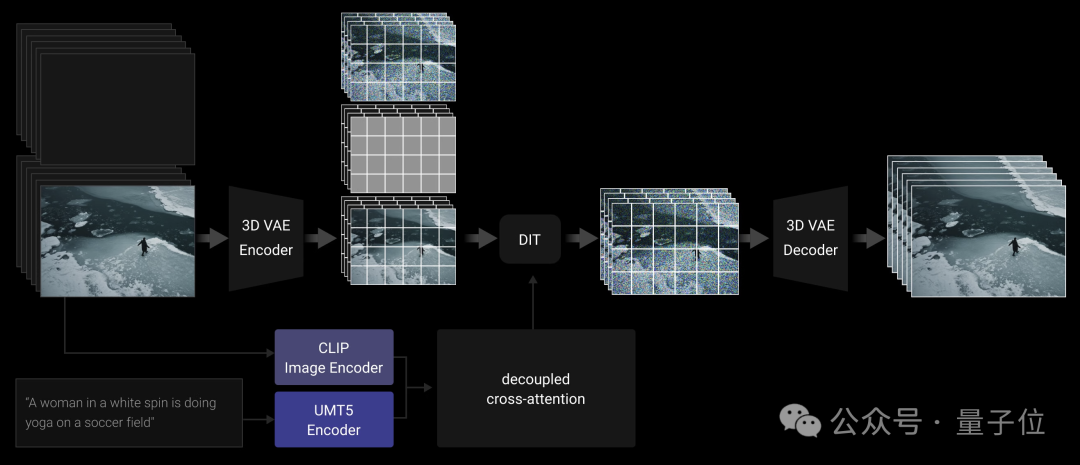
和主流的视频生成技术路线一样,Wan 2.1的主体采用了DiT(Diffusion Transformer)架构。
Wan利用T5编码器对输入的多语言文本进行编码,并在每个Transformer块内加入交叉注意力机制,将文本嵌入到模型架构中。
此外,Wan采用线性层和SiLU层来处理输入时间嵌入并分别预测六个调制参数。这样的MLP在所有Transformer块之间共享,每个块都学习一组不同的偏差。
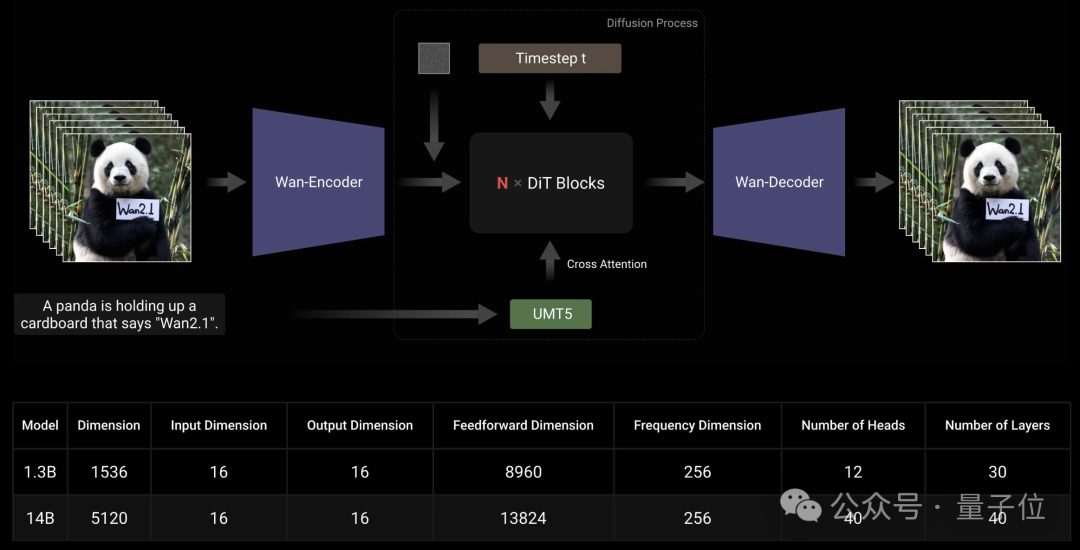
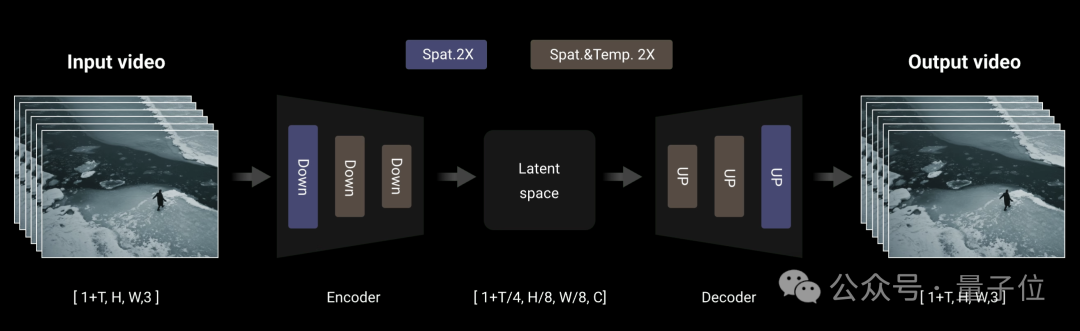
编码上,Wan采用了3D变分自动编码器,这是一种专门为视频生成设计的3D因果关系体系结构。
它在卷积模块中实现了特征缓存机制,并结合了多种策略来改善时空压缩,减少记忆使用情况并确保时间因果关系。
具体来说,由于视频序列帧数遵循1+T输入格式,因此Wan将视频分成1+T/4个块,与潜在特征的数量一致。
在处理输入视频序列时,该模型采用逐块策略,其中每个编码和解码操作仅处理与单个潜在表示相对应的视频块。
基于时间压缩比,每个处理块中的帧数最多限制为4,从而有效防止GPU内存溢出。
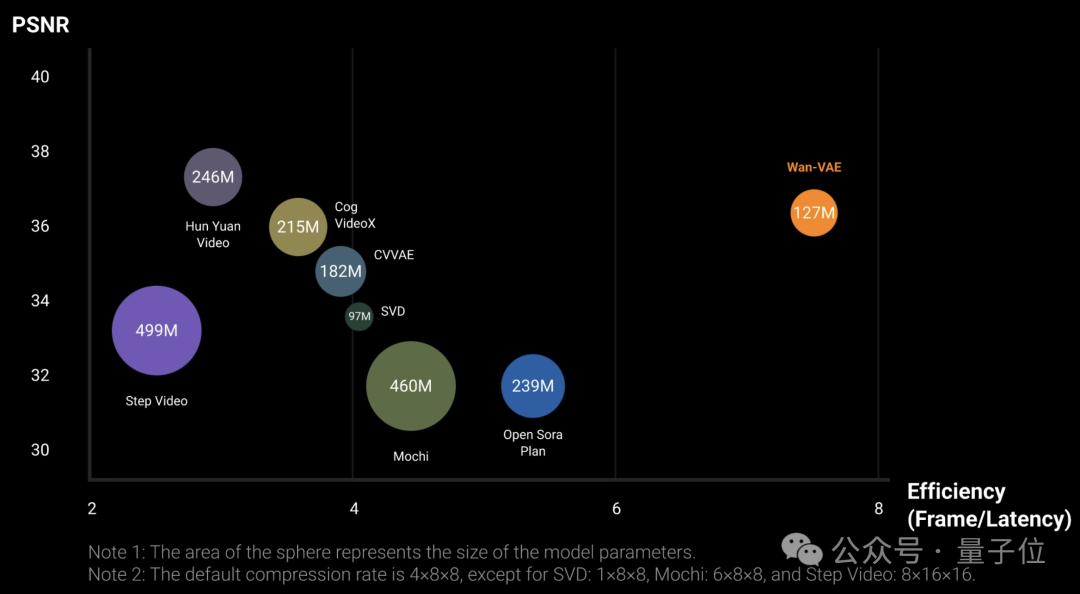
实验结果表明,在单块A800上,Wan的VAE的重建速度比现有的SOTA方法快2.5倍。
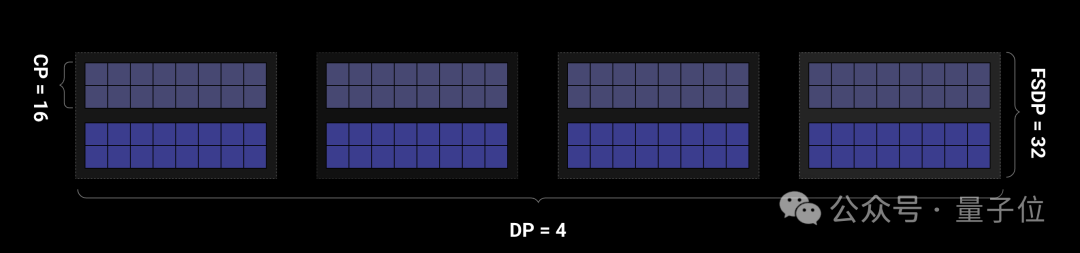
为了使模型扩展并提高训练效率,Wan对编码器采用FSDP模型切分与上下文并行性(CP)相结合的分布式策略;对于DiT模块则采用DP、FSDP、RingAttention、Ulysses混合的并行策略。
在推理阶段,为了使用多卡减少生成单个视频的延迟,还需要通过CP来进行分布式加速。
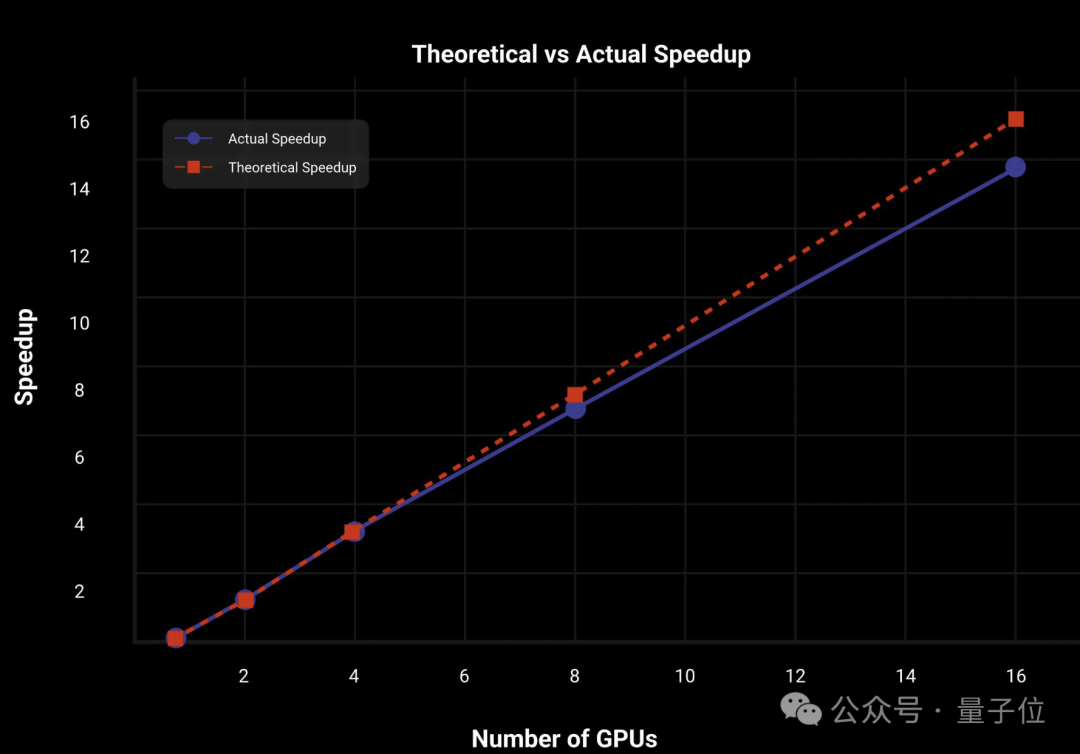
在14B版本的Wan上,2D上下文并行和FSDP并行策略,让DiT达到了几乎线性的加速。
I2V部分,Wan引入了额外的条件图像作为第一帧来控制视频合成,用CLIP图像编码器从条件图像中提取特征表示。
具体而言,条件图像沿时间轴与零填充帧连接,形成指导帧。然后,这些指导帧由3D VAE压缩为条件潜在表示。
另外由于I2V DiT模型的输入通道比T2V模型多,因此I2V版本中还使用了额外的投影层,并用零值初始化。
之后阿里还会放出更详细的报告,对技术细节感兴趣的读者可以持续关注~
参考链接:
https://mp.weixin.qq.com/s/SRj06E-VCSpCiQZqE0gpHA
GitHub:
https://github.com/Wan-Video/Wan2.1
Hugging Face:
https://huggingface.co/Wan-AI
魔搭社区:
https://www.modelscope.cn/models/Wan-AI



















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









