



 ICLR拒稿结果让AI研究者不满,如Transformer架构挑战者Mamba论文,四位审稿人打出8/8/6/3分数仍被拒,引发对评审流程的质疑。有研究者认为评审过程有缺陷,投稿接不接受很随机。此外,还提到了新生代会议CoLM,它专注语言模型领域,将采用双盲审核。
ICLR拒稿结果让AI研究者不满,如Transformer架构挑战者Mamba论文,四位审稿人打出8/8/6/3分数仍被拒,引发对评审流程的质疑。有研究者认为评审过程有缺陷,投稿接不接受很随机。此外,还提到了新生代会议CoLM,它专注语言模型领域,将采用双盲审核。
梦晨 西风 发自 凹非寺
量子位 | 公众号 QbitAI
一项ICLR拒稿结果让AI研究者集体破防,纷纷刷起小丑符号 。
。
争议论文为Transformer架构挑战者Mamba,开创了大模型的一个新流派。发布两个月不到,后续研究MoE版本、多模态版本等都已跟上。
但面对ICRL给出的结果,康奈尔副教授Alexander Rush都表示看不懂怎么回事了,“如果这都被拒了,那我们小丑们还有什么机会”。
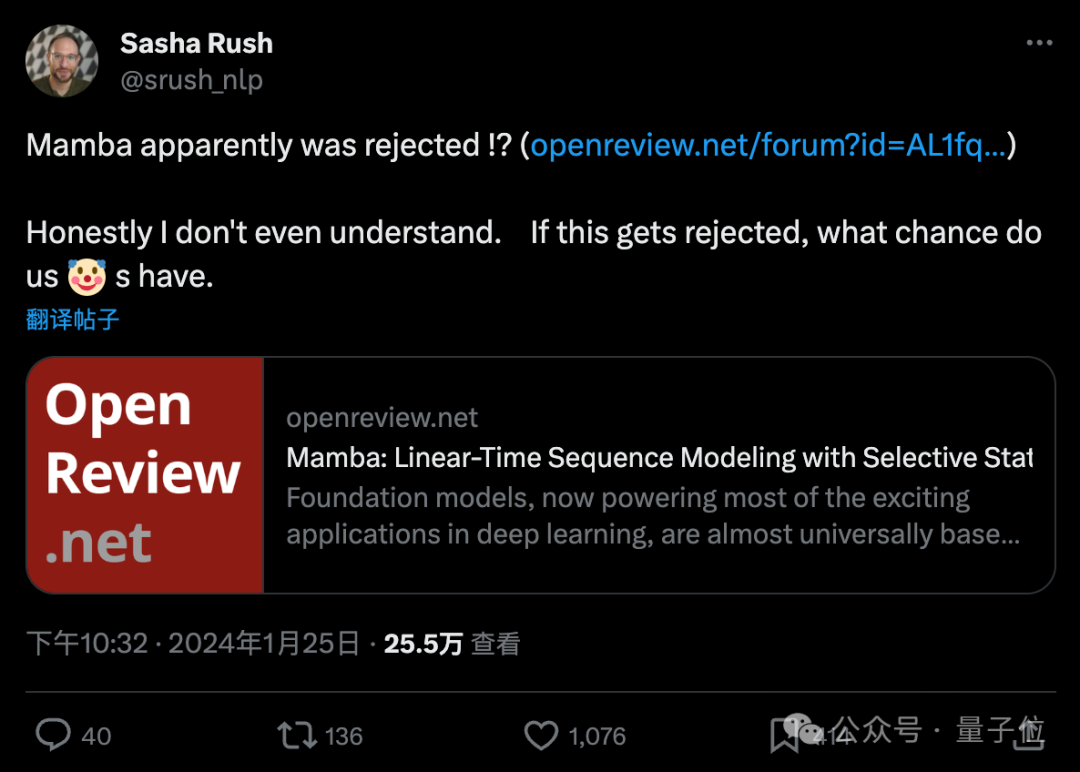
在评论区和转发区,不少研究者带上小丑面具前来报道。

具体来说,四位审稿人打出8/8/6/3的分数,这样被拒很多人就已经觉得不正常。
其中一位审稿人提的问题是“有没有训练更大的模型,和10b参数的Transformer比较如何?”。
对此,有人表示已经开始向审稿人提及实验成本了。
审稿人可能不知道他们要求的实验会花费50000美元。

ICLR会议创办的初衷正是优化同行评审过程,LeCun作为会议创始人之一,也表达了不满:
很遗憾,历届程序委员会主席慢慢把它变成了一个与传统评审流程差不多的会议。
只有一些小胜利:OpenReview平台现在被大多数ML/AI会议使用,以及论文提交后立刻就能被所有人阅读(尽管匿名)。
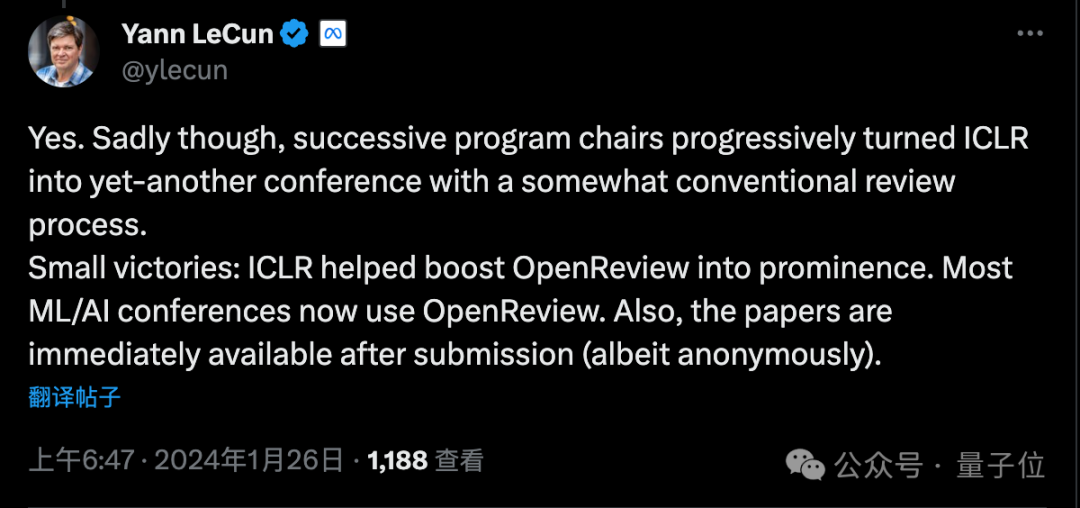
LeCun还举例自己也有一篇从未被接受、ArXiv独占的论文,现在被引用次数已超过1880次。

也有研究者认为,这次很多高分被接受论文与Mamba比起来充其量只能算增量研究,更令人遗憾了。

这届ICLR混乱重重
先来借用给6分审稿人的意见,简单介绍一下Mamba论文的主要贡献。
提出了基于SSM状态空间模型的新架构,可实现Transformer质量的性能,同时线性缩放序列长度。
提出了一种硬件感知算法,通过扫描而不是卷积来循环计算模型,避免具体化扩展状态以减少内存使用。
将先前的深度序列模型架构简化为同构架构,具有快速推理、线性缩放和改进的长序列性能。
在多种模态(语言、音频和基因组学)上都取得SOTA性能,成为跨模态通用序列模型主干的有力候选者。

但这位审稿人提出的二次内存需求问题,不少熟悉这篇论文的人都表示不认可。


对此,作者也在Rebuttal中给出了解释,内存需求实际上是随序列长度线性增长的。

另外一位打3分的审稿人,还被吃瓜群众指出可能根本不熟悉什么是RNN。

作者针对这位审稿人的Rebuttal太长,足足分了4条才发完。

然鹅,这位对自己评分给出5级置信度的审稿人,根本没有回复。

这就让人更担心会不会影响领域主席的判断了。

正如这位研究者所说,这届ICLR出现的争议还不止一例。
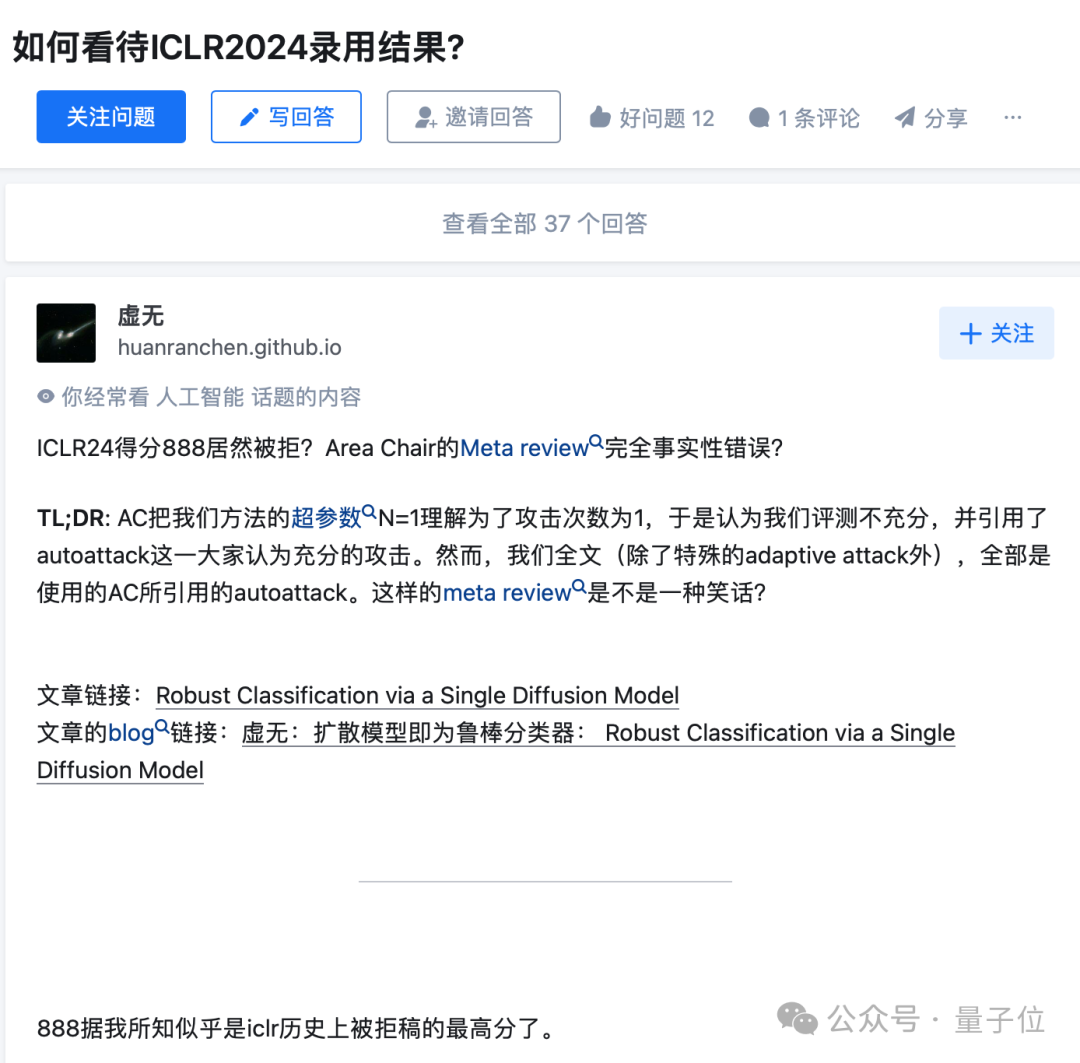
8/8/6/3如果被拒还算事出有因,知乎相关讨论上还有得分8/8/8被AC拒,就更离谱了。
还有作者和审稿人吵起来,以至于要讨论礼貌问题的。
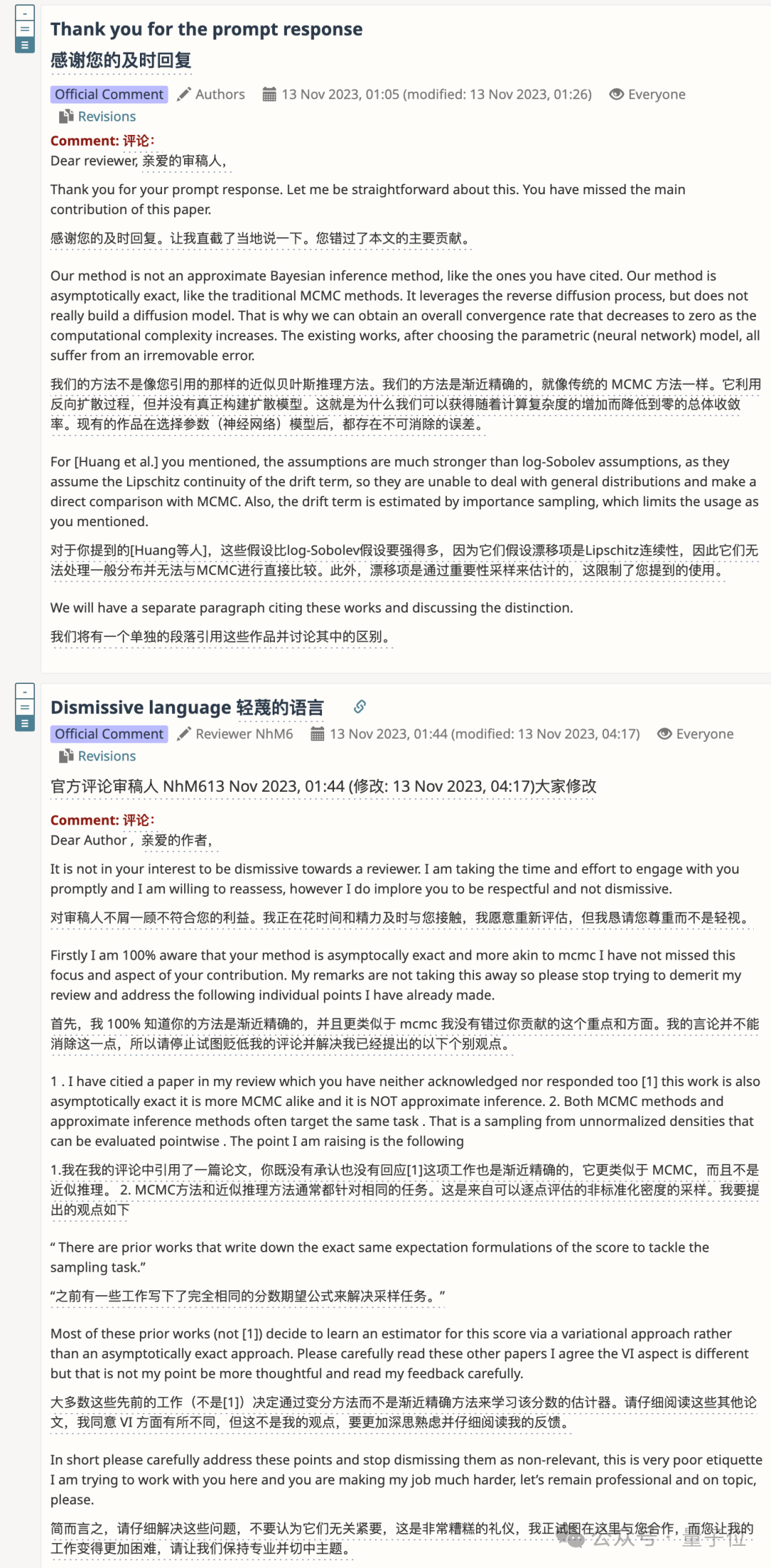
投稿接不接收全靠随机?
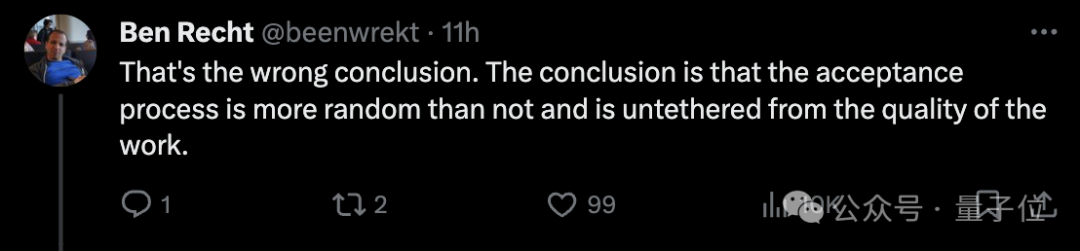
这也引发了网友们对整体学术评审现状的讨论。其中一个主要讨论点是评审过程有缺陷“接不接受真的很随机,和论文本身的质量关系不大”:
网友也是缓缓打出一个问号:
既然评审流程存在问题,那解决方案是什么?就靠运气?

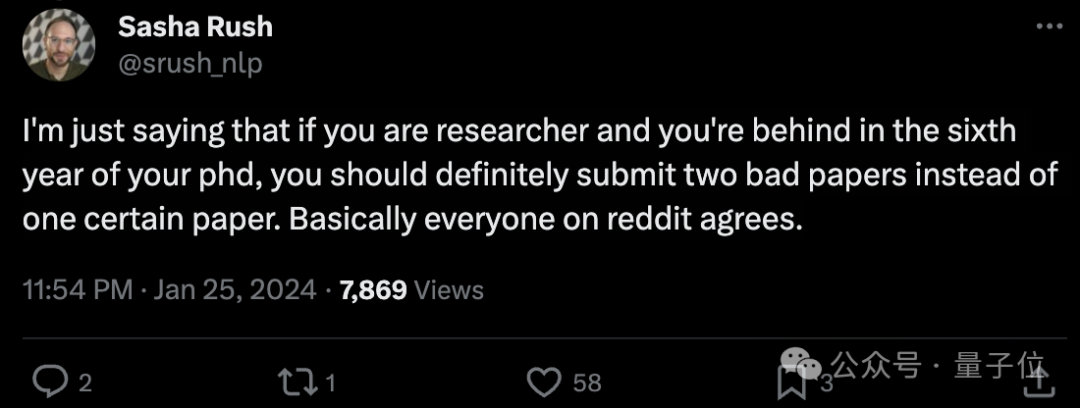
对此,康奈尔副教授Alexander Rush甚至还提出了这样的建议(手动狗头):
如果你读博已经读到了第六年的那种,应该提交两篇糟糕的论文,而不是一篇好的。
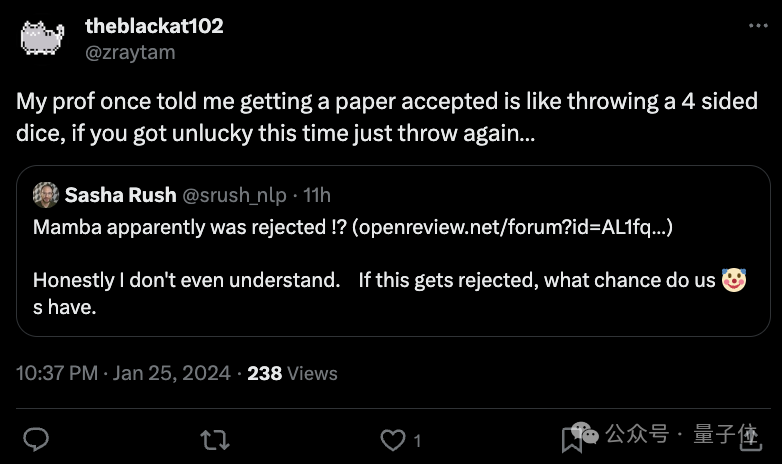
不只一位学者分享了类似的建议:
我的教授曾说,论文被接受的过程就像掷一个四面骰子,如果这次运气不好,就再掷一次……
当然,也有人抱有不同的观点,认为会议作为一种认可,已出名的作品其实已经不需要了,可以给其他未被发掘的论文更多机会,所以已经出名的论文被学术会议拒绝也是完全可以接受的。
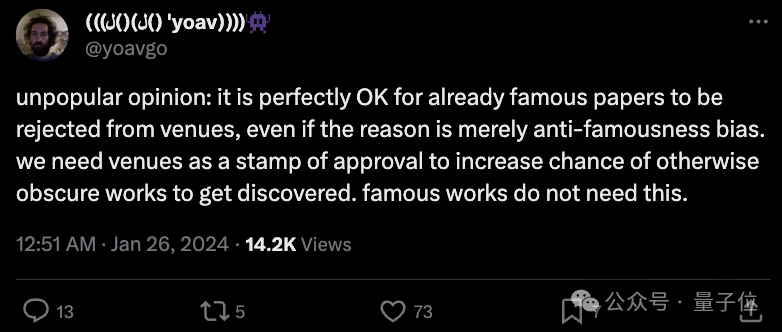
值得一提的是,还有不少人建议大家转投新生代会议CoLM,Alexander Rush自己也参与了这个会议的创办:
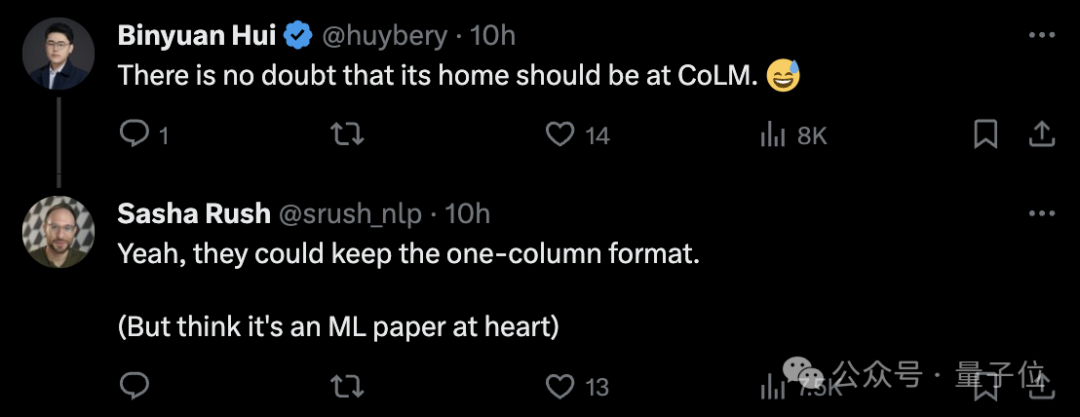
而大家提到的CoLM会议,全称Conference On Language Modeling,专注于语言模型领域。CoLM刚创立不久,第一届大会将在今年10月份举办。
其中七位组织者均是来自业界学界的大佬,其中有三位是华人学者谷歌周登勇、普林斯顿陈丹琦、Meta的Angela Fan。
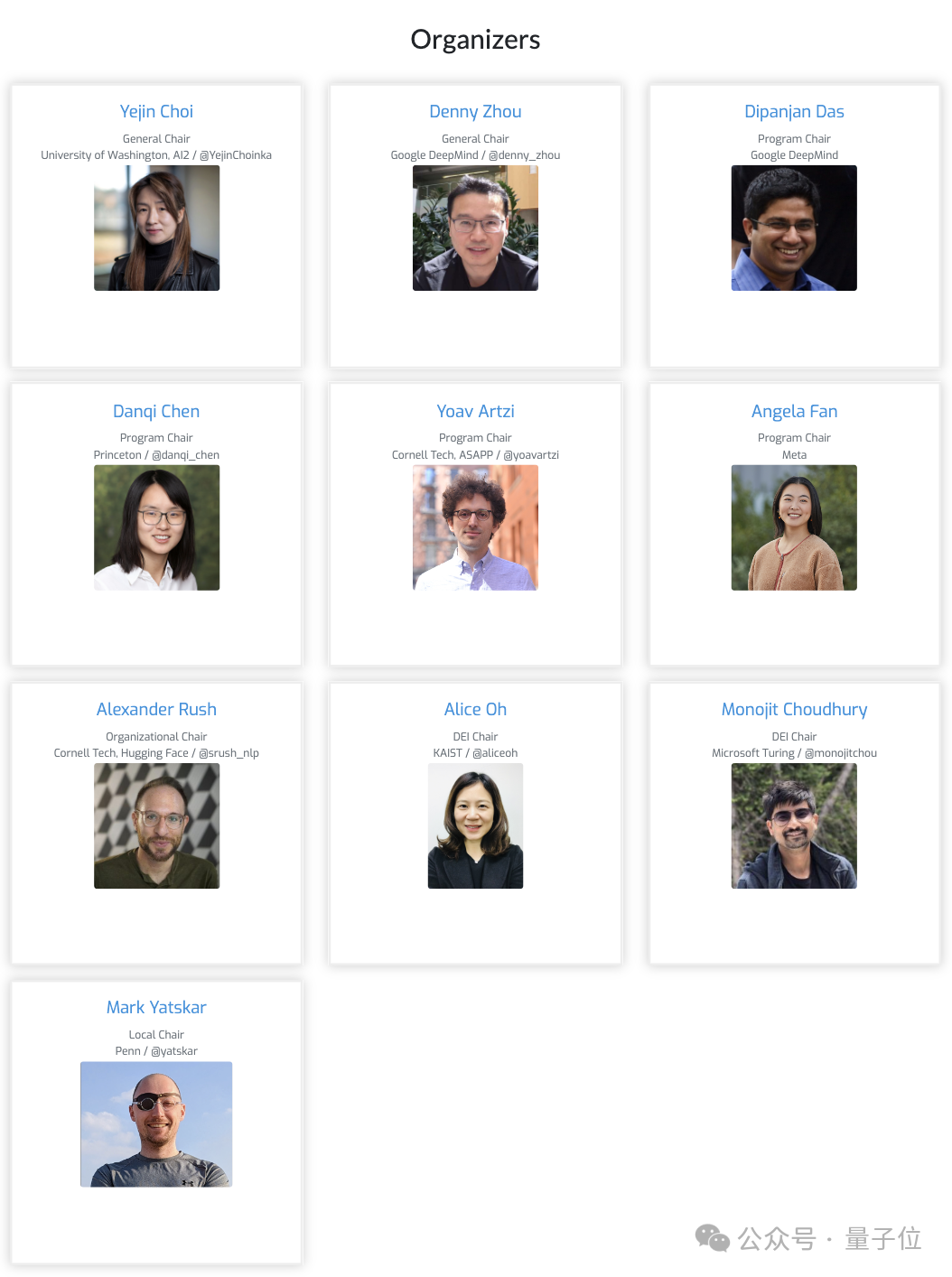
与ICLR类似,COLM将采用双盲审核,并使用OpenReview管理投稿。
会议征稿主题包括但不限于语言建模及大模型语境下的对齐、数据、评估、社会影响、安全、科学、高效计算、工程、学习和推理算法等17个方向。
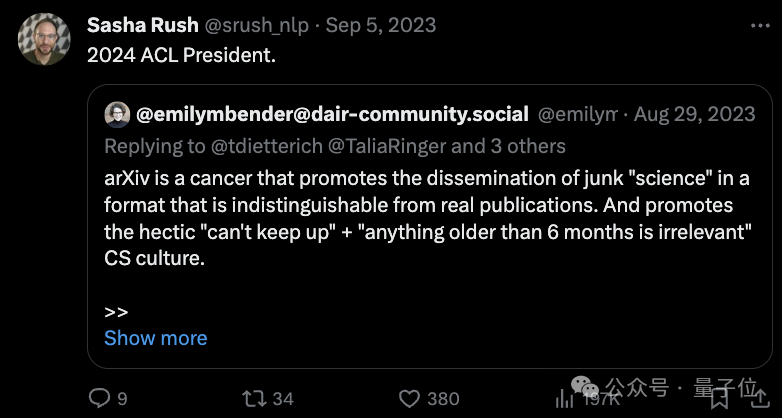
据说,COLM还是在ACL 2024主席公开抨击称“arXiv是科研的毒瘤”而后引发争论的背景下,催生出来的。
参考链接:
[1]https://twitter.com/srush_nlp/status/1750526956452577486
[2]https://x.com/ylecun/status/1750594387141369891
[3]https://openreview.net/forum?id=AL1fq05o7H
— 完 —
点这里👇关注我,记得标星哦~



















 30
30

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









