



Pine 明敏 发自 凹非寺
量子位 | 公众号 QbitAI
陈丹琦新论文来了!
研究团队全员女将,这是她在普林斯顿的第一篇all-female author论文。

论文主题也和女性议题有关。
论文提出了MABEL,一种使用限定标签来让AI减少性别偏见的方法。
通过这一方法,团队证明如果上游预训练中对于性别偏见的矫正,能直接影响下游任务。
而且适用于任何模型。
目前该论文被EMNLP 2022接收,项目已开源。
在Hugging Face上也能找到使用了这一方法的BERT-base和BERT-large模型,即插即用。

使用限定标签减轻偏见
陈丹琦团队的这个新方法MABEL,全称是一种使用专用标签消除性别偏见的方法(a Method for Attenuating Gender Bias using Entailment Labels)。
MABEL是在任务不可知的情况下来消除偏见的,换言之,这种方法适用于任何模型。
此前适用于这种情况的消除偏见方法,比较流行的是SEAT(句子编码器关联测试),但后来被相关研究证明:
其内在指标衡量出的结果与外部指标没有直接的相关性。
也就是说,虽然一个模型在使用SEAT方法测试其消除偏见的得分很高,但在实际执行任务的过程中仍然不及预期。
而这次研究团队呢,吸取了SEAT的经验,内在指标与外部指标两手抓。
并且据团队介绍,MABEL还是第一个利用来自监督句子对的语义信号来消除偏见的方法。
那它到底是怎样来消除模型中的性别偏见的呢?
一言以蔽之,MABEL通过对预训练数据库中的所有带有敏感属性的词进行反义替换,其他词则保持不变,然后进行对比学习来消除偏见。
具体来说,研究团队做了两方面的工作。
首先是数据集方面,研究团队使用的是自然语言推理(NLI)数据集,它在训练有区别性和高质量的句子表征方面特别有效。
由于研究团队主攻性别歧视方向的偏见,因此,他们从NLI数据集中提取了在前提或者假设中包含性别术语的所有隐含对。
然后对数据进行反事实增强,即将数据集中包含性别敏感的词汇全部替换成反义词汇,如男生→女生…
接下来的步骤就比较关键了:训练!
训练主要针对的是以下三个损失函数:
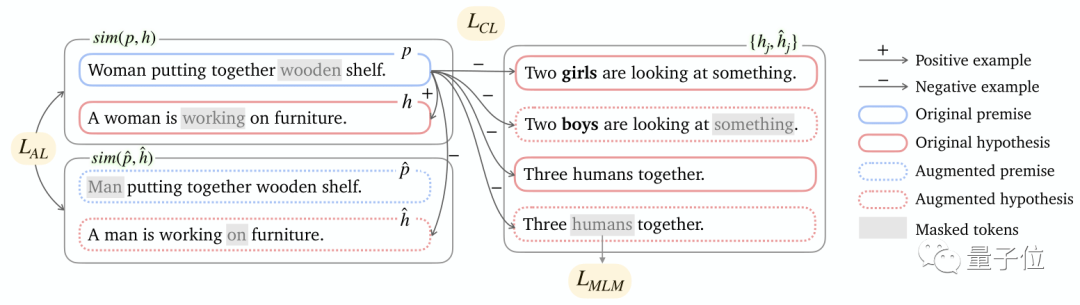
第一个是基于隐含的对比损失 (Entailment-based contrastive loss),它比较像SimCSE。
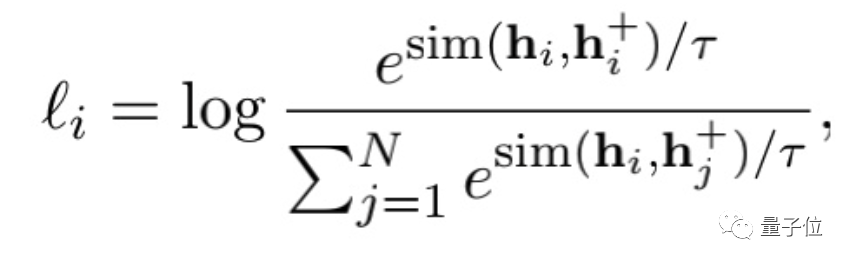
△SimCSE
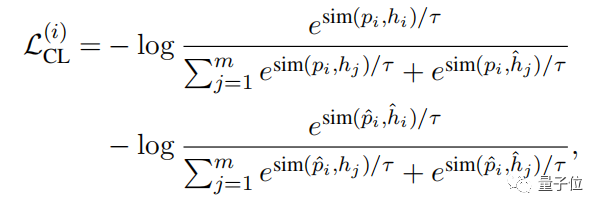
△Entailment-based contrastive loss
这种对比性的损失是将具有类似含义的两个句子进行对比,使两个句子的隐含对中有更强的关联,进而使编码器学习更多丰富的语义关联。
第二个是对齐损失 (Alignment loss),这就比较好理解了,它是用来表示原始隐含对和其增强对之间的内部关联。
也就是说,这个函数能够使模型最后生成的结果在男女之间更加平衡,以保证最后模型生成的结果性别歧视降到最低。
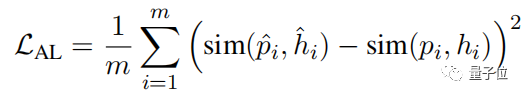
第三个是掩码语言模型损失 (Masked language modeling loss),这是最后额外附加的一个损失,目的是为了保持模型的语言建模能力。
研究团队在所有句子中随机屏蔽了15%的标记。通过利用周围的上下文来预测原始的术语,编码器被激励去保留token级别的知识。
最终的损失函数如下:
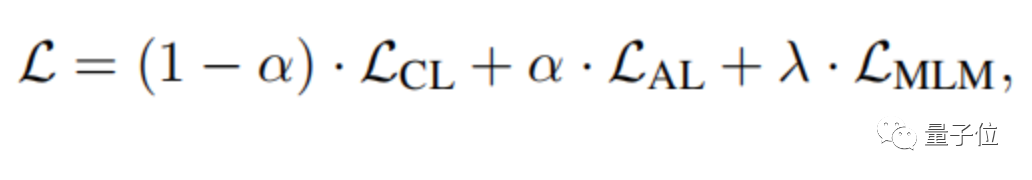
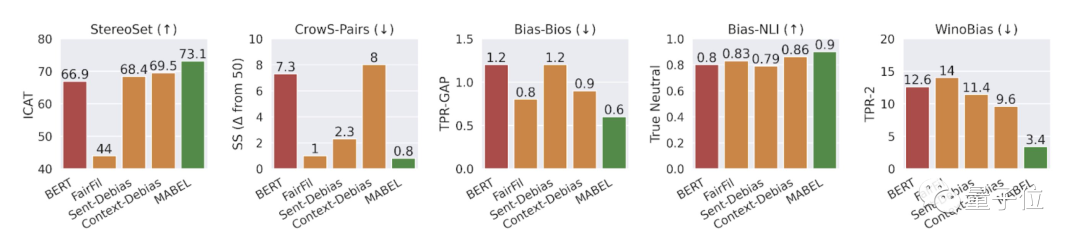
讲了这么多,那MABEL这个方法偏见消除的效果如何?
研究团队直接做了个可视化的柱状图来呈现这个方法消除性别歧视的效果。
在五个衡量指标中,包括两个内在指标(左边两个)和三个外部指标,MABEL表现出了良好的公平性-性能权衡。
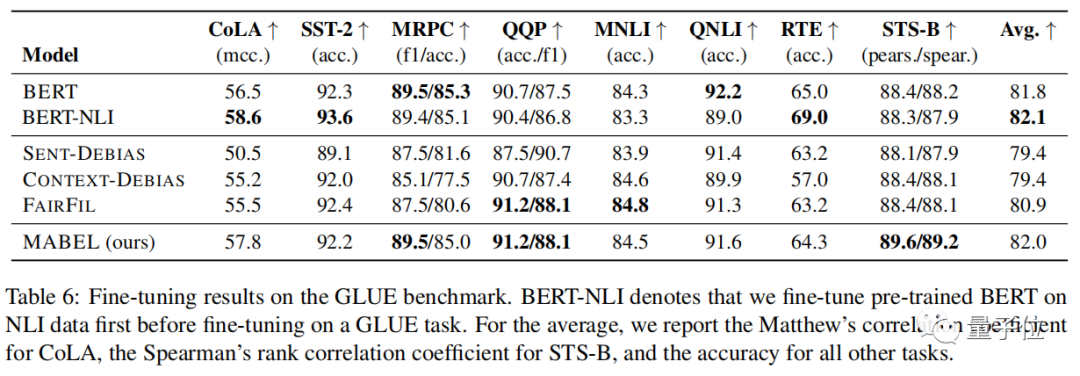
此外,研究团队还评估了语言模型在使用了消除性别歧视的方法后是否仍然保持一般的语言理解,结果显示模型能够很好地保留其在GLUE上的自然语言理解(NLU)能力。
陈丹琦带队,全员女将
最后,来看一下研究团队阵容。
陈丹琦,清华姚班校友,计算机领域近年来最受关注的青年学者之一。

现任普林斯顿大学助理教授,NLP组共同负责人、也是AIML组成员。
此前,她凭借在信息学竞赛圈内的传奇经历引发众人关注——CDQ分治算法就是以她的名字命名。2008年,代表中国队斩获一枚IOI金牌。
她长达 156 页的博士毕业论文《Neural Reading Comprehension and Beyond》,也一度火爆出圈。不光获得当年斯坦福最佳博士论文奖,还成为了斯坦福大学近十年来最热门毕业论文之一。
今年2月,陈丹琦凭借在NLP领域的成就和潜力,斩获斯隆研究奖,该奖项素有“诺奖风向标”称号。
论文一作为Jacqueline He。

她是一位今年刚刚毕业的普林斯顿计算机系本科生,目前是在Meta工作。
陈丹琦介绍说,Jacqueline同时也在申请博士学位。
团队中还有一位陈丹琦的学生Mengzhou Xia。

她现在是普林斯顿计算机专业的一位博士生,本科毕业于复旦大学,后赴卡内基梅隆大学读研。研究兴趣领域为大规模预训练模型的性能和效率。
除此之外,研究团队中还有一位72岁的高龄女学者。
她是普林斯顿语言学&计算机科学系教授Christiane D. Fellbaum。
其研究领域包括自然语言处理、词汇语义、计算语言学、文本语料库等,曾联合开发WordNet。这是一个基于认知语言学的英语词典,可按照单词意思组成了一个“单词的网络”。

论文地址:
https://arxiv.org/abs/2210.14975
参考链接:
[1]https://twitter.com/danqi_chen/status/1599828154839093248?
[2]https://www.cs.princeton.edu/~danqic/
— 完 —
量子位「MEET2023智能未来大会」
12月14日,线上直播

点这里关注我 👇 记得标星噢 ~


















 22
22

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









