




一、 背景
随着HarmonyOS系统的持续演进和全场景智慧生态的构建,人工智能技术正在加速向端侧设备渗透。作为华为自主研发的全场景AI计算框架,MindSpore凭借其"端边云协同"的设计理念和高效的自动微分能力,为开发者提供了开箱即用的深度学习解决方案。
鸢尾花分类是机器学习中的经典案例,也是常用的一个入门案例。本文使用Mindspore框架,构建一个简单的神经网络模型,对鸢尾花进行分类。
二、环境准备
演示教学使用环境如下:
1. 操作系统:Ubuntu 18.04 LTS
2. conda 24.9.2
3. PyCharm 2024.3.5 (Professional Edition)
三、环境搭建
(一)安装Anaconda和PyCharm(具体详见其他教程)
注意事项:安装时,此项选择 "yes" ,以便后续操作。
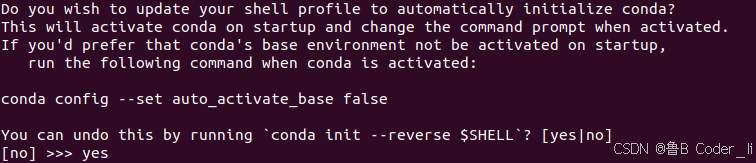
(二)在Ubuntu系统打开终端(Ctrl + Alt + T),创建conda虚拟环境
使用下列语句,创建一个名称为 YWHmodel 的虚拟环境,制定Python版本为3.11。
conda create --name YWHmodel python=3.11
(三)激活conda虚拟环境
使用以下语句,激活并进入该虚拟环境。
conda activate YWHmodel
(四)在虚拟环境中下载依赖资源包
1. 首先下载Mindspore框架资源包,使用官方提供指令,选择合适版本下载。
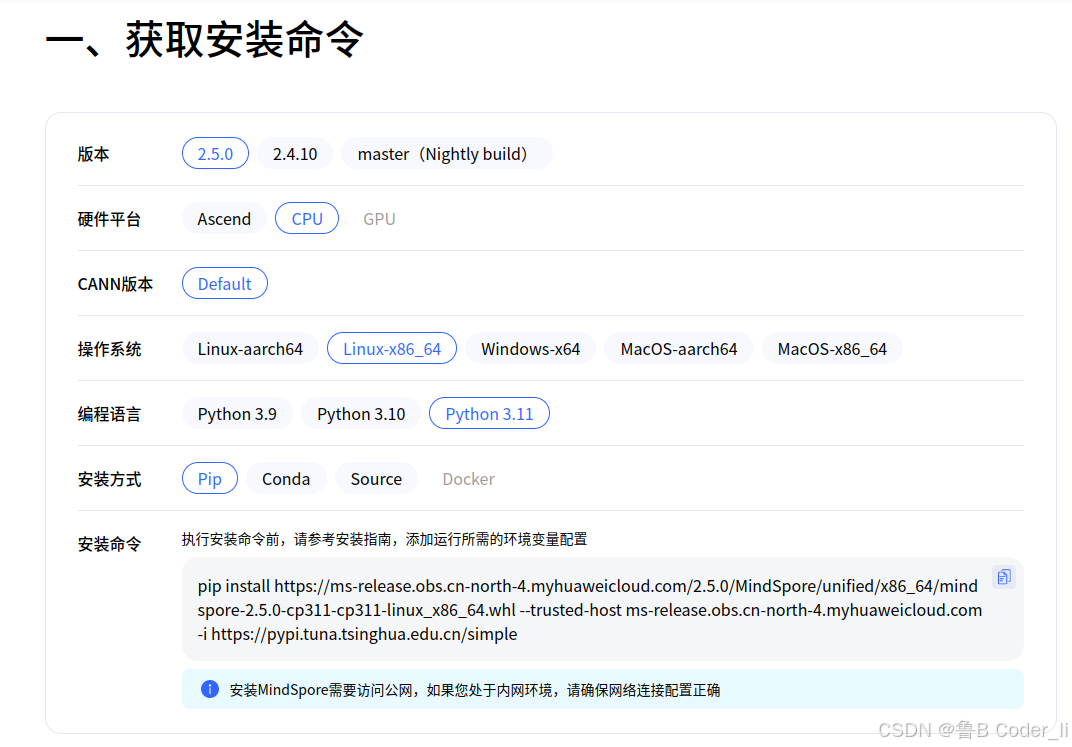
下载命令如下:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.5.0/MindSpore/unified/x86_64/mindspore-2.5.0-cp311-cp311-linux_x86_64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
验证是否安装成功:
python -c "import mindspore;mindspore.set_device(device_target='CPU');mindspore.run_check()"
当出现下列结果,说明安装成功!
MindSpore version: 版本号
The result of multiplication calculation is correct, MindSpore has been installed on platform [CPU] successfully!
2. 下载其他依赖资源包(使用清华源加速安装)
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
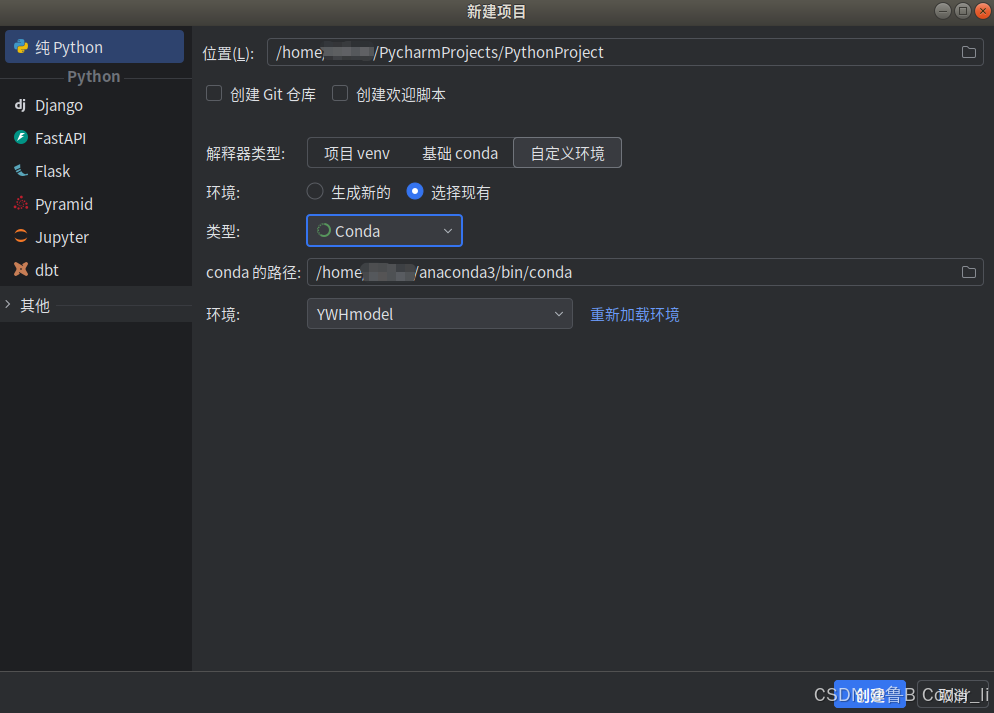
(五)打开PyCharm,加载配置好的环境
按照下述图片进行选择环境,点击创建项目,选择“自定义环境” --> “选择现有” --> “Conda”类型 --> “YWHmodel”环境 --> “创建”,等待PyCharm加载完毕。
四、基于Mindspore的鸢尾花分类模型实现
(一)构建神经网络模型
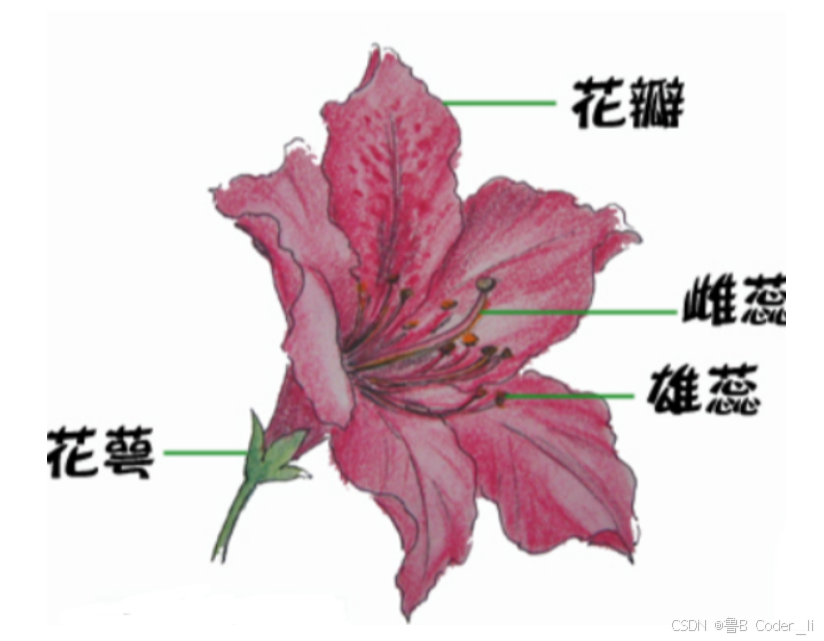
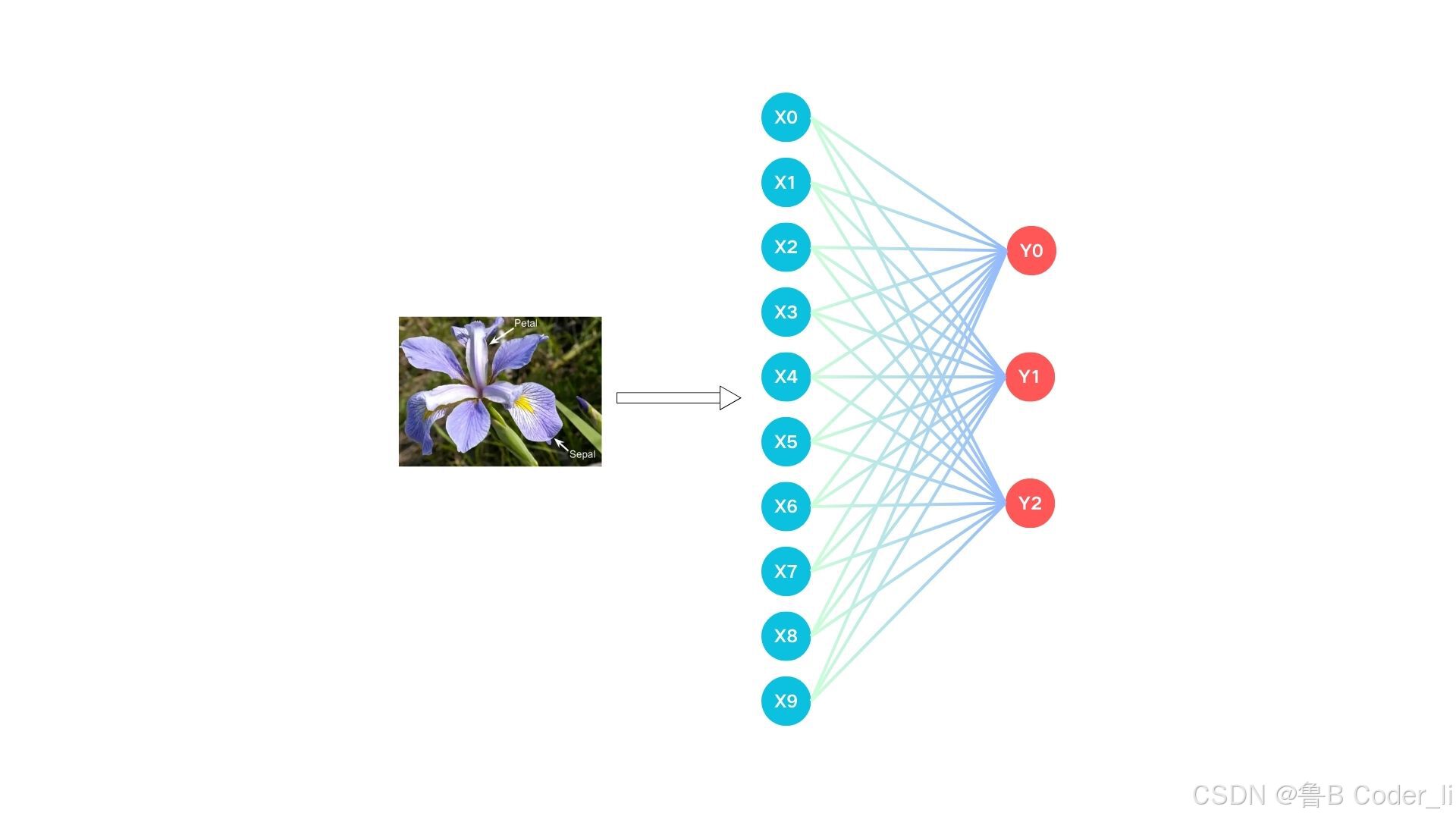
对于每一个鸢尾花,拥有四个特性,分别是花瓣、花萼、雄蕊和雌蕊,那么对应四个输入的参数。因此,我们考虑构建简单的神经网络模型,包含三个全连接层和一个 ReLU 激活函数。如下图所示:
(二)创建Python文件
在打开的PyCharm项目中,新建Python文件,命名为 "main.py"。
(三)导入框架及相关依赖资源
import numpy as np
import matplotlib.pyplot as plt
# 导入 Mindspore 模块和辅助模块
import mindspore as ms
from mindspore import Tensor
from mindspore import nn
from mindspore import context
from mindspore.nn import TrainOneStepCell
# 导入 sklearn 模块和辅助模块
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
mindspore: Mindspore深度学习框架。
mindspore.nn: 提供各种层和损失函数。
sklearn.datasets.load_iris: 加载鸢尾花数据集。
sklearn.model_selection.train_test_split: 划分训练集和测试集。
sklearn.preprocessing.StandardScaler:数据标准化处理。
numpy: 用于数值转换及运算。
matplotlib.pyplot:用于绘制图表。
(四)设置训练为GRAPH_MODEL,使用CPU训练
context.set_context(mode=context.GRAPH_MODE, device_target="CPU")
(五)加载数据(X存储特征数据,y存储标签数据)
加载数据时,使用numpy库中的astype()方法,将数据转换为Mindspore易于接收的数据。
iris = load_iris()
X = iris.data.astype(np.float32)
y = iris.target.astype(np.int32)
(六)划分训练集和测试集(stratify=y表示进行分层抽样,测试集占20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
(七)数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
(八)转换为Mindspore张量
使用Mindspore包中的Tensor转换。
X_train_tensor = Tensor(X_train)
y_train_tensor = Tensor(y_train)
X_test_tensor = Tensor(X_test)
y_test_tensor = Tensor(y_test)
(九)模型定义与实例化
在MindSpore中,"nn.Cell" 是所有神经网络的基类,类似于PyTorch中的 "nn.Module" 。用户定义的模型需要继承这个类,并实现"construct"方法来定义前向传播过程。在PyTorch中的"forward"方法,Mindspore框架中需要实现"construct"方法。
首先定义模型IrisNet类,根据之前分析得出的模型,定义一个三层全连接神经网络,用于鸢尾花分类任务,使用ReLU增加非线性。
class IrisNet(nn.Cell):
def __init__(self):
super().__init__()
self.layer1 = nn.Dense(4, 10)
self.layer2 = nn.Dense(10, 10)
self.output = nn.Dense(10, 3)
self.relu = nn.ReLU()
def construct(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.output(x)
return x
MindSpore的训练流程通常要求将前向计算和损失计算封装成一个完整的计算图,以便框架能够自动管理反向传播和梯度计算。因此,我们考虑封装一个CustonTrainNet类,供训练时调用。
class CustomTrainNet(nn.Cell):
def __init__(self, network, loss_fn):
super().__init__()
self.network = network
self.loss_fn = loss_fn
def construct(self, x, label):
outputs = self.network(x)
loss = self.loss_fn(outputs, label)
return loss
进行模型实例化。
model = IrisNet()
(十)定义损失函数和优化器
定义损失函数(loss_fn)为交叉熵损失函数,采用梯度下降算法(SGD)进行优化,学习率定义为0.01。
net_with_loss: 组合模型和损失函数,计算损失
train_set: 自动完成梯度计算和参数更新
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=0.01)
net_with_loss = CustomTrainNet(model, loss_fn)
train_net = TrainOneStepCell(net_with_loss, optimizer)
(十一)模型训练
调用train_net时,依次执行:前向传播 --> 损失计算 --> 后向传播 --> 参数更新
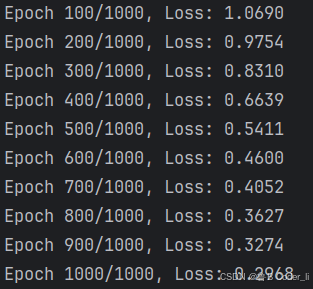
每100次迭代进行一次打印,观察损失值的变化。
epochs = 1000
losses = []
for epoch in range(epochs):
loss = train_net(X_train_tensor, y_train_tensor)
losses.append(float(loss))
if (epoch + 1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}")
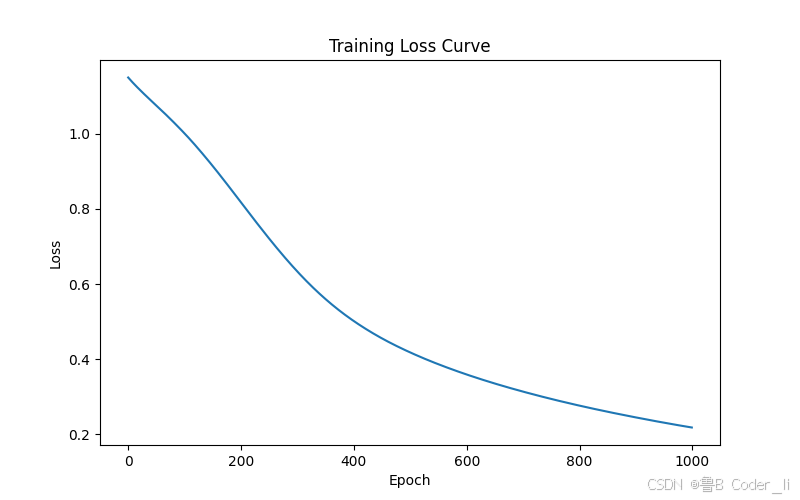
(十二)训练损失曲线可视化
plt.figure(figsize=(8, 5))
plt.plot(losses)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss Curve")
plt.show()
运行代码,结果如图所示:
(十三)保存完整模型
使用export函数导出为MINDIR格式。export函数接收4个参数:
1. model: 要导出的模型
2. input_sample: 输入样例(确定模型输入维度)
3. file_name: 保存文件名
4. file_format: 导出格式
input_sample = Tensor(np.expand_dims(X_train[0], axis=0), dtype=ms.float32)
ms.export(
model,
input_sample,
file_name="iris_model",
file_format="MINDIR"
)
print("模型已保存!")
最终得到模型"iris_model.mindir",如下图所示:

五、总结
本案例通过 Mindspore 构建了一个简单的全连接神经网络,实现了经典的 鸢尾花分类任务。通过本案例,可掌握 MindSpore 的基础用法,并为复杂任务(如图像分类、自然语言处理)奠定实践基础。

















 1758
1758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









