




 在爬取大量数据时遇到IP被封的问题,本文介绍了两种策略:修改请求头以模拟浏览器访问和使用代理IP。通过添加请求头伪装浏览器身份,并引用代码生成代理IP池,确保即使IP被封也能继续爬取。最终成功避免了IP被封,实现了数据的完整爬取。
在爬取大量数据时遇到IP被封的问题,本文介绍了两种策略:修改请求头以模拟浏览器访问和使用代理IP。通过添加请求头伪装浏览器身份,并引用代码生成代理IP池,确保即使IP被封也能继续爬取。最终成功避免了IP被封,实现了数据的完整爬取。
继续老套路,这两天我爬取了猪八戒上的一些数据 网址是:http://task.zbj.com/t-ppsj/p1s5.html,可能是由于爬取的数据量有点多吧,结果我的IP被封了,需要自己手动来验证解封ip,但这显然阻止了我爬取更多的数据了。
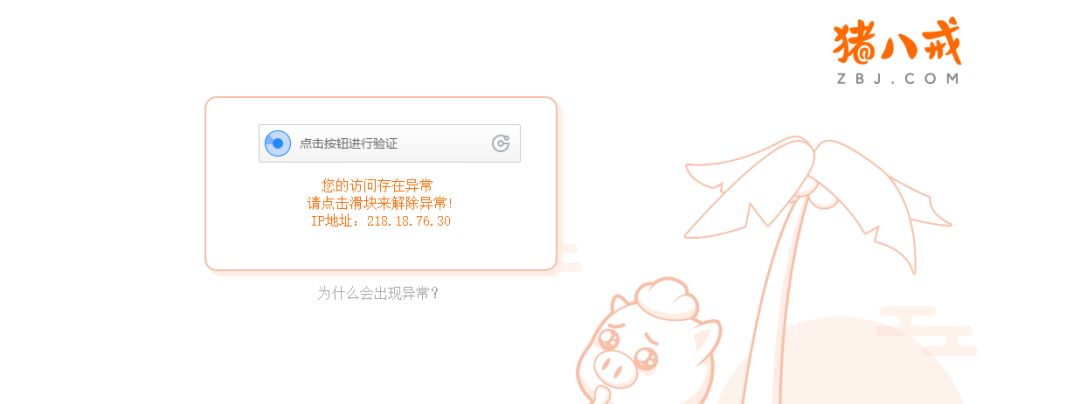
下面是我写的爬取猪八戒的被封IP的代码
# coding=utf-8
import requests
from lxml import etree
def getUrl():
for i in range(33):
url = 'http://task.zbj.com/t-ppsj/p{}s5.html'.format(i+1)
spiderPage(url)
def spiderPage(url):
if url is None:
return None
htmlText = requests.get(url).text
selector = etree.HTML(htmlText)
tds = selector.xpath('//*[@class="tab-switch tab-progress"]/table/tr')
try:
for td in tds:
price = td.xpath('./td/p/em/text()')
href = td.xpath('./td/p/a/@href')
title = td.xpath('./td/p/a/text()')
subTitle = td.xpath('./td/p/text()')
deadline = td.xpath('./td/span/text()')
price = price[0] if len(price)>0 else '' # python的三目运算 :为真时的结果 if 判定条件 else 为假时的结果
title = title[0] if len(title)>0 else ''
href = href[0] if len(href)>0 else ''
subTitle = subTitle[0] if len(subTitle)>0 else ''
deadline = deadline[0] if len(deadline)>0 else ''
print price,title,href,subTitle,deadline
print '---------------------------------------------------------------------------------------'
spiderDetail(href)
&nb 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









